1. 在程序执行过程中,高速缓存(Cache) 与主存间的地址映射由( )。
A. 程序员和操作系统共同协调完成
B. 操作系统进行管理
C. 程序员自行安排
D. 硬件自动完成
高速缓存(Cache)是位于CPU和主存之间的高速存储子系统。采用高速缓存的主要目的是提高存储器的平均访问速度,使存储器的速度与CPU的速度相匹配。Cache的存在对程序员是透明的。其地址变换和数据块的替换算法均由硬件实现。通常Cache被集成到CPU内,以提高访问速度,其主要特点是容量小、速度快、成本高。
1)Cache的组成
Cache的组成如下图所示。Cache由两部分组成,即控制部分和缓存部分。缓存部分用来存放主存的部分复制信息。控制部分的功能是:判断CPU要访问的信息是否在Cache中,若在即为命中,若不在则没有命中。命中时直接对Cache寻址;未命中时,要按照替换原则,决定主存的一块信息放到Cache的哪一块里面。
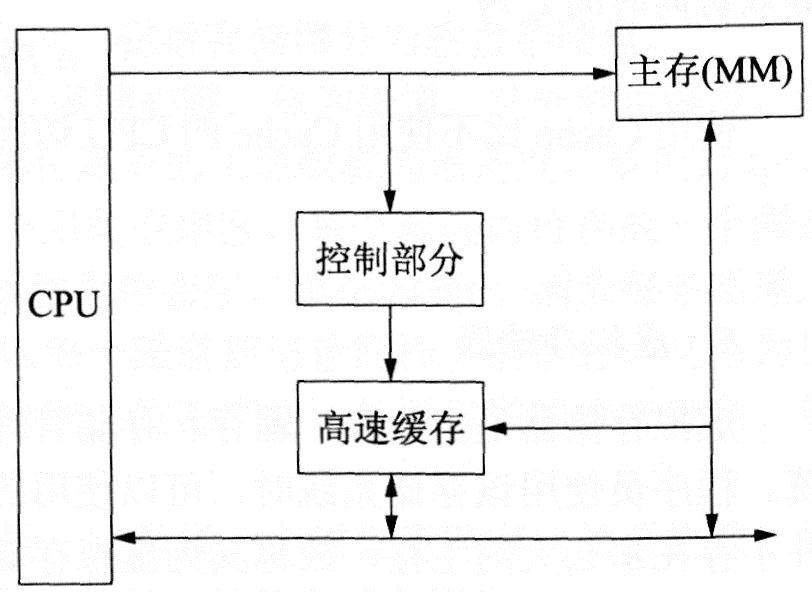
高速缓存的组成框图
2)Cache中的地址映像方法
因为处理机访问都是按主存地址访问的,而应从Cache中读写信息,因此这就需要地址映像,即把主存中的地址映射成Cache中的地址。地址映像的方法有3种,即直接映像、全相联映像和组相联映像。
(1)直接映像就是主存的块与Cache中块的对应关系是固定的。主存中的块只能存放在Cache的相同块号中。因此,只要主存地址中的主存区号与Cache中的主存区号相同,则表明访问Cache命中。一旦命中,以主存地址中的区内块号立即可得到要访问的Cache中的块。这种方式的优点是地址变换很简单,缺点是灵活性差。
(2)全相联映像允许主存的任一块可以调入Cache的任何一块的空间中。在地址变换时,利用主存地址高位表示的主存块号与Cache中的主存块号进行比较,若相同则为命中。这种方式的优点是主存的块调入Cache的位置不受限制,十分灵活;其缺点是无法从主存块号中直接获得Cache的块号,变换比较复杂,速度比较慢。
(3)组相联映像是前面两种方式的折中。具体做法是将Cache中的块再分成组。组相联映像就是规定组采用直接映像方式而块采用全相联映像方式。这种方式下,通过直接映像方式来决定组号,在一组内再用全映像方式来决定Cache中的块号。由主存地址高位决定主存区号,与Cache中区号比较可决定是否命中。主存后面的地址即为组号,但组块号要根据全相联映像方式,由记录可以决定组内块号。
3)替换算法
选择替换算法的目标是使Cache获得最高的命中率。常用的替换算法有以下几种。
(1)随机替换(RAND)算法:用随机数发生器产生一个要替换的块号,将该块替换出去。
(2)先进先出(FIFO)算法:将最先进入的Cache信息块替换出去。
(3)近期最少使用(LRU)算法:将近期最少使用的Cache中的信息块替换出去。这种算法比先进先出算法要好些,但此法也不能保证过去不常用的将来也不常用。
(4)优化替换(OPT)算法:先执行一次程序,统计Cache的替换情况。有了这样的先验信息,在第二次执行该程序时便可以用最有效的方式来替换,达到最优的目的。
4)Cache的性能分析
若H为Cache的命中率,tc为Cache的存取时间,tm为主存的访问时间,则Cache的等效访问时间ta为
ta=Htc+(1-H)tm
使用Cache比不使用Cache的CPU访问存储器的速度提高的倍数r可以用下式求得,即
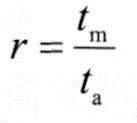
Cache即高速缓冲存储器,是为了解决CPU和主存之间速度匹配问题而设置的。它是介于CPU和主存之间的小容量存储器,存取速度比主存快。其改善系统性能的依据是程序的局部性原理。
.Cache主要由两部分组成,即控制部分和存储器部分。
.Cache存储器部分用来存放主存的部分副本。
.控制部分的功能是判断CPU要访问的信息是否在Cache存储器中,若在即为命中,若不在则没有命中。
2. 计算机中提供指令地址的程序计数器PC在( )中。
A. 控制器
B. 运算器
C. 存储器
D. I/O设备
指令是指挥计算机完成各种操作的基本命令。
(1)指令格式。计算机的指令由操作码字段和操作数字段两部分组成。
(2)指令长度。指令长度有固定长度的和可变长度的两种。有些RISC的指令是固定长度的,但目前多数计算机系统的指令是可变长度的。指令长度通常取8的倍数。
(3)指令种类。指令有数据传送指令、算术运算指令、位运算指令、程序流程控制指令、串操作指令、处理器控制指令等类型。
3. 以下关于两个浮点数相加运算的叙述中,正确的是( ).
A. 首先进行对阶,阶码大的向阶码小的对齐
B. 首先进行对阶,阶码小的向阶码大的对齐
C. 不需要对阶,直接将尾数相加
D. 不需要对阶,直接将阶码相加
4. 某计算机系统的CPU主频为2.8GHz。某应用程序包括3类指令,各类指令的CPI(执行每条指令所需要的时钟周期数)及指令比例如’下表所示。执行该应用程序时的平均CPI为(4);运算速度用MIPS表示,约为( 5)。
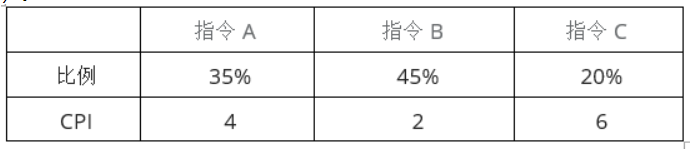
A. 25
B. 3
C. 3.5
D. 4
SNMPv3的应用程序分为5种。
(1)命令生成器(Command Generators):建立SNMP Read/Write请求,并且处理对这些请求的响应。
(2)命令响应器(Command Responders):接收SNMP Read/Write请求,对管理数据进行访问,并按照协议规定的操作产生响应报文,返回读/写命令的发送者。
(3)通知发送器(Notification Originators):监控系统中出现的特殊事件,产生通知类报文,并且要有一种机制,以决定向何处发送报文,使用何种SNMP版本和安全参数等。
(4)通知接收器(Notification Receivers):监听通知报文,并产生响应。
(5)代理转发器(Proxy Repeaters):在SNMP实体之间转发报文。
指令是指挥计算机完成各种操作的基本命令。
(1)指令格式。计算机的指令由操作码字段和操作数字段两部分组成。
(2)指令长度。指令长度有固定长度的和可变长度的两种。有些RISC的指令是固定长度的,但目前多数计算机系统的指令是可变长度的。指令长度通常取8的倍数。
(3)指令种类。指令有数据传送指令、算术运算指令、位运算指令、程序流程控制指令、串操作指令、处理器控制指令等类型。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
主频是CPU的时钟频率(CPU Clock Speed),或者说是CPU运算时的工作频率。一般主频越高,一个时钟周期里面执行的指令数也越多,CPU的速度也越快。外频是系统总线的工作频率,倍频则是CPU外频与主频相差的倍数,因此,主频=外频×倍频。
内存总线速度
内存总线速度是指CPU与二级(L2)高速缓存和内存之间的通信速度。由于在外存上的信息必须读入内存才能由CPU进行处理,因此CPU与内存之间的总线速度对整个系统性能就显得非常重要。但是,访问内存的速度与CPU的运行速度会有差异,故引入二级缓存来协调内存和CPU之间速度不匹配的矛盾。
扩展总线速度
扩展总线速度是指CPU与扩展设备之间的数据传输速度。扩展总线是CPU与外部设备通信的桥梁。在计算机系统中的扩展总线有VESA或PCI总线,当打开计算机时看见的一些插槽就是扩展总线连接的扩展槽。例如,通过插在PCI扩展槽上的网卡,使得CPU能与网络设备通信。
总线宽度
总线宽度分为地址总线宽度和数据总线宽度。其中,地址总线宽度决定了CPU可以访问的物理地址空间,即CPU能够使用多大容量的内存。例如,地址线的宽度为32位,最多可以直接访问4096 MB(4GB)的物理空间。数据总线负责整个系统中数据流量的大小,其数据总线宽度决定了CPU与二级高速缓存、内存以及输入输出设备之间一次数据传输的信息量。
运算速度是计算机工作能力和生产效率的主要表征,取决于给定时间内CPU所能处理的数据量和CPU的主频。
5. 某计算机系统的CPU主频为2.8GHz。某应用程序包括3类指令,各类指令的CPI(执行每条指令所需要的时钟周期数)及指令比例如’下表所示。执行该应用程序时的平均CPI为(4);运算速度用MIPS表示,约为( 5)。
A. 700
B. 800
C. 930
D. 1100
6. 中断向量提供( ).
A. 函数调用结束后的返回地址
B. I/O设备的接口地址
C. 主程序的入口地址
D. 中断服务程序入口地址
7. 以下关于认证和加密的叙述中,错误的是( )。
A. 加密用以确保数据的保密性
B. 认证用以确保报文发送者和接收者的真实性
C. 认证和加密都可以阻止对手进行被动攻击
D. 身份认证的目的在于识别用户的合法性,阻止非法用户访问系统
8. 访问控制是对信息系统资源进行保护的重要措施,适当的访问控制能够阻止未经授权的用户有意或者无意地获取资源。计算机系统中,访问控制的任务不包括( )。
A. 审计
B. 授权
C. 确定存取权限
D. 实施存取权限
信息系统是用于收集、处理、存储、分发信息的相互关联的组件的集合,其作用在于支持组织的决策与控制。
信息系统包括三项活动,如下图所示。
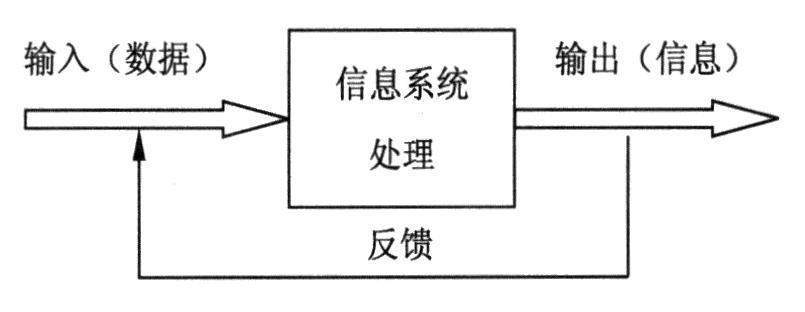
信息系统的三项活动
.输入活动:从组织或外部环境中获取或收集原始数据。
.处理活动:将输入的原始数据转换为更有意义的形式。
.输出活动:将处理后形成的信息传递给人或者需要此信息的活动。
反馈是把输出信息返回到组织内相应成员中,组织成员借助反馈信息来评测或纠正输入阶段的活动。
信息系统的组成包含七大部分:
.计算机硬件系统。
.计算机软件系统。
.数据及存储介质。
.通信系统。
.非计算机系统的信息收集、处理设备。
.规章制度。
.工作人员。
从用途类型来划分,信息系统一般可分为电子商务系统、事务处理系统、管理信息系统、生产制造系统、电子政务系统和决策支持系统等。
信息系统集成是采用现代管理理论(例如软件工程、项目管理等)作为计划、设计、控制的方法论,将硬件、软件、数据库、网络等部件按照规划的结构和秩序,有机地整合到一个有清晰边界的信息系统中,以达到既定系统目标的过程。
9. 路由协议称为内部网关协议,自治系统之间的协议称为外部网关协议,以下属于外部网关协议的是( )。
A. RIP
B. 0SPF
C. BGP
D. UDP
自治系统是由同构型的网关连接的互联网,这样的系统往往是由一个网络管理中心控制的。自治系统内部的网关之间执行内部网关协议(IGP),互相交换路由信息。IGP是自治系统内部专用的,为特定的应用服务,在自治系统之外是无效的。
一个互联网也可能由不同的自治系统互联而成。在这种情况下,不同的自治系统可能采用不同的路由表和不同的路由选择算法。在不同自治系统中的网关之间交换路由信息,要用外部网关协议(EGP)。EGP比IGP传送的信息要少一些,因为EGP只涉及自治系统之间的路由信息,而与系统内部路由无关。EGP以自治系统为节点,通告各个网关可到达哪些系统。
自治系统之间使用EGP,最新的EGP叫作边界网关协议(BGP)。BGP的主要功能是控制路由策略,如是否愿意转发过路的分组等。BGP的报文通过TCP连接传送。BGP报文可实现以下3个功能过程。
(1)建立邻居关系。位于不同自治系统中的两个路由器首先要建立邻居关系,然后才能周期性地交换路由信息。建立邻居关系的过程是:一个路由器发送open报文,另一个路由器若愿意接受请求,则以keepalive(保持活动状态)报文应答。
(2)邻居可达性。这个过程维护邻居关系的有效性。通过周期性地互相发送keepalive报文,双方都知道对方的活动状态。
(3)网络可达性。每个路由器保持一个数据库,记录着它可到达的所有子网。当情况有变化时,用更新报文把最新信息及时地广播给所有实现BGP的路由器。
Internet的内部路由协议经过了几次大的变化。最初的RIP(路由选择信息协议)是基于Bellman-Ford算法的延迟矢量协议。这个协议在网络规模不大时工作得较好,当网络规模扩大后,因为交换的路由信息太多而显得效率很低。于是,在1979年5月被另一个路由协议——基于Dijkstra算法的链路状态协议所取代。从1988年开始,IETF开始研制新的路由协议,这就是OSPF(开放最短路径优先)协议。1990年,OSPF正式成为新的内部路由协议标准。
OSPF基本上仍是一种链路状态协议。OSPF的路由器维护一个本地链路状态表,并随时向其他相邻的路由器发送关于链路状态的更新信息。通过周期地扩散传播链路状态信息,每个路由器都记住了关于网络拓扑结构的全局数据库。同时OSPF路由器根据用户指定的链路费用标准(延迟、带宽或收费率等)计算最短通路,由到达各个目标的最短通路构成路由表。OSPF报文包含在原始的IP数据报中传送。
在一个计算机网络中,当连接不同类型而协议差别又较大的网络时,要选用网关(Gateway)设备。网关的功能体现在OSI模型的最高层,它将协议进行转换,将数据重新分组,以便在两个不同类型的网络系统之间进行通信。由于协议转换是一件复杂的事,一般来说,网关只进行一对一转换,或是少数几种特定应用协议的转换,网关很难实现通用的协议转换。用于网关转换的应用协议有电子邮件、文件传输和远程登录等。
网关和多协议路由器组合在一起可以连接多种不同的系统。和网桥一样,网关可以是本地的,也可以是远程的。常见的网关有电子邮件网关、IBM主机网关、因特网网关和局域网网关等。
冲突域是连接在同一导线上的所有工作站的集合。这个域代表了冲突在其中发生并传播的区域,这个区域可以被认为是共享段。在OSI模型中,冲突域被看作第一层的概念,连接同一冲突域的设备有集线器(Hub)、中继器(Repeater)或者其他进行简单复制信号的设备。也就是说,用Hub或者Repeater连接的所有节点可以被认为是在同一个冲突域内,它不会划分冲突域。而第二层设备(如网桥、交换机)和第三层设备(如路由器)都可以划分冲突域。
广播域是接收同样广播消息的节点集合。由于广播域被认为是OSI中的第二层概念,所以像集线器、交换机等第一层、第二层设备连接的节点被认为都是在同一个广播域。而路由器、第三层交换机则可以划分广播域。
10. 所有资源只能由授权方或以授权的方式进行修改,即信息未经授权不能进行改变的特性是指信息的( )。
A. 完整性
B. 可用性
C. 保密性
D. 不可抵赖性
11. 在Windows操作系统下,要获取某个网络开放端口所对应的应用程序信息,可以使用命令( )。
A. ipconfig
B. traceroute
C. netstat
D. nslookup
SNMPv3的应用程序分为5种。
(1)命令生成器(Command Generators):建立SNMP Read/Write请求,并且处理对这些请求的响应。
(2)命令响应器(Command Responders):接收SNMP Read/Write请求,对管理数据进行访问,并按照协议规定的操作产生响应报文,返回读/写命令的发送者。
(3)通知发送器(Notification Originators):监控系统中出现的特殊事件,产生通知类报文,并且要有一种机制,以决定向何处发送报文,使用何种SNMP版本和安全参数等。
(4)通知接收器(Notification Receivers):监听通知报文,并产生响应。
(5)代理转发器(Proxy Repeaters):在SNMP实体之间转发报文。
Windows操作系统是Microsoft公司推出的应用于计算机的GUI产品,它起源于Xerox公司的研究工作,其第一个成功图形界面操作系统是Windows 3.0。Windows操作系统产品主要包括适合于桌面PC机和适合于网络服务器的网络操作系统NT系列。桌面级操作系统的版本主要有Windows 3.2、Windows 95、Windows 98、Windows ME、Windows 2000 Professional和Windows XP等。网络操作系统的版本主要有Windows NT 3.5、Windows NT 4.0、Windows 2000 Server系列和Windows Server 2003系列等。
在TCP/IP网络中,传输层的所有服务都包含端口号,它们可以唯一区分每个数据包包含哪些应用协议。端口系统利用这种信息来区分包中的数据,尤其是端口号使一个接收端计算机系统能够确定它所收到的IP包类型,并把它交给合适的高层软件。
端口号和设备IP地址的组合通常称作插口(socket)。任何TCP/IP实现所提供的服务都用知名的1~1023之间的端口号。这些知名端口号由Internet号分配机构(Internet Assigned Numbers Authority,IANA)来管理。例如,SMTP所用的TCP端口号是25,POP3所用的TCP端口号是110,DNS所用的UDP端口号为53,WWW服务使用的TCP端口号为80。FTP在客户与服务器的内部建立两条TCP连接,一条是控制连接,端口号为21;另一条是数据连接,端口号为20。
256~1023之间的端口号通常由Unix系统占用,以提供一些特定的UNIX服务。也就是说,提供一些只有UNIX系统才有的、其他操作系统可能不提供的服务。
在实际应用中,用户可以改变服务器上各种服务的保留端口号,但要注意,在需要服务的客户端也要改为同一端口号。
现代操作系统的基本功能是管理计算机系统的硬件、软件资源,这些管理工作分为处理机管理、存储器管理、设备管理、文件管理、作业和通信事务管理。
操作系统的性能与计算机系统工作的优劣有着密切的联系。评价操作系统的性能指标一般有:
(1)系统的可靠性。
(2)系统的吞吐率(量),是指系统在单位时间内所处理的信息量,以每小时或每天所处理的各类作业的数量来度量。
(3)系统响应时间,是指用户从提交作业到得到计算结果这段时间,又称周转时间;
(4)系统资源利用率,指系统中各个部件、各种设备的使用程度。它用在给定时间内,某一设备实际使用时间所占的比例来度量。
(5)可移植性。
12. 甲、 乙两个申请人分别就相同内容的计算机软件发明创造,向国务院专利行政部门门提出专利申请,甲先于乙一日提出,则( )。
A. 甲获得该项专利申请权
B. 乙获得该项专利申请权
C. 甲和乙都获得该项专利申请权
D. 甲和乙都不能获得该项专利申请权
计算机软件是指计算机系统中的程序及其文档。程序是计算任务的处理对象和处理规则的描述。任何以计算机为处理工具的任务都是计算任务。处理对象是数据(如数字、文字、图形、图像、声音等,它们只是表示,而无含义)或信息(数据及有关的含义)。处理规则一般指处理的动作和步骤。文档是为了便于了解程序所需的阐述性资料。
按照软件的应用领域,可以将计算机软件分为十大类:系统软件、应用软件、工程/科学软件、嵌入式软件、产品线软件、Web应用、人工智能软件、开放计算、网络资源和开源软件。
13. 小王是某高校的非全日制在读研究生,目前在甲公司实习,负责了该公司某软件项目的开发工作并撰写相关的软件文档。以下叙述中,正确的是( )。
A. 该软件文档属于职务作品,但小王享有该软件著作权的全部权利
B. 该软件文档属于职务作品,甲公司享有该软件著作权的全部权利
C. 该软件文档不属于职务作品,小王享有该软件著作权的全部权利
D. 该软件文档不属于职务作品,甲公司和小王共同享有该著作权的全部权利
14. 按照我国著作权法的权利保护期,以下权利中,( )受到永久保护。
A. 发表权
B. 修改权
C. 复制权
D. 发行权
知识产权管理相关的法律包括专利法、商标法、著作权法和反不正当竞争法等法律,就系统集成行业的工作实践而言,知识产权管理属于特定专业知识领域,组织通常会由相关的法务部门负责知识产权管理相关事项。基于考试角度,考生应该重点了解《著作权法》相关的内容和条款,下面摘录了《著作权法》中的重要条款内容,供考生参考。关于《著作权法》的完整内容,考生可以参考清华大学出版社官方网站本书参考资料部分所对应的电子文档。
第一章总则
第一条为保护文学、艺术和科学作品作者的著作权,以及与著作权有关的权益,鼓励有益于社会主义精神文明、物质文明建设的作品的创作和传播,促进社会主义文化和科学事业的发展与繁荣,根据宪法制定本法。
第二条中国公民、法人或者其他组织的作品,不论是否发表,依照本法享有著作权。
第三条本法所称的作品,包括以下列形式创作的文学、艺术和自然科学、社会科学、工程技术等作品:
(一)文字作品;
(二)口述作品;
(三)音乐、戏剧、曲艺、舞蹈、杂技艺术作品;
(四)美术、建筑作品;
(五)摄影作品;
(六)电影作品和以类似摄制电影的方法创作的作品;
(七)工程设计图、产品设计图、地图、示意图等图形作品和模型作品;
(八)计算机软件;
(九)法律、行政法规规定的其他作品。
第五条本法不适用于:
(一)法律、法规,国家机关的决议、决定、命令和其他具有立法、行政、司法性质的文件,及其官方正式译文;
(二)时事新闻;
(三)历法、通用数表、通用表格和公式。
第二章著作权
第九条著作权人包括:
(一)作者;
(二)其他依照本法享有著作权的公民、法人或者其他组织。
第十条著作权包括下列人身权和财产权:
(一)发表权,即决定作品是否公之于众的权利;
(二)署名权,即表明作者身份,在作品上署名的权利;
(三)修改权,即修改或者授权他人修改作品的权利;
(四)保护作品完整权,即保护作品不受歪曲、篡改的权利;
(五)复制权,即以印刷、复印、拓印、录音、录像、翻录、翻拍等方式将作品制作一份或者多份的权利;
(六)发行权,即以出售或者赠予方式向公众提供作品的原件或者复制件的权利;
(七)出租权,即有偿许可他人临时使用电影作品和以类似摄制电影的方法创作的作品、计算机软件的权利,计算机软件不是出租的主要标的的除外;
(八)展览权,即公开陈列美术作品、摄影作品的原件或者复制件的权利;
(九)表演权,即公开表演作品,以及用各种手段公开播送作品的表演的权利;
(十)放映权,即通过放映机、幻灯机等技术设备公开再现美术、摄影、电影和以类似摄制电影的方法创作的作品等的权利;
(十一)广播权,即以无线方式公开广播或者传播作品,以有线传播或者转播的方式向公众传播广播的作品,以及通过扩音器或者其他传送符号、声音、图像的类似工具向公众传播广播的作品的权利;
(十二)信息网络传播权,即以有线或者无线方式向公众提供作品,使公众可以在其个人选定的时间和地点获得作品的权利;
(十三)摄制权,即以摄制电影或者以类似摄制电影的方法将作品固定在载体上的权利;
(十四)改编权,即改变作品,创作出具有独创性的新作品的权利;
(十五)翻译权,即将作品从一种语言文字转换成另一种语言文字的权利;
(十六)汇编权,即将作品或者作品的片段通过选择或者编排,汇集成新作品的权利;
(十七)应当由著作权人享有的其他权利。
著作权人可以许可他人行使前款第(五)项至第(十七)项规定的权利,并依照约定或者本法有关规定获得报酬。
著作权人可以全部或者部分转让本条第一款第(五)项至第(十七)项规定的权利,并依照约定或者本法有关规定获得报酬。
第十一条著作权属于作者,本法另有规定的除外。
创作作品的公民是作者。
由法人或者其他组织主持,代表法人或者其他组织意志创作,并由法人或者其他组织承担责任的作品,法人或者其他组织视为作者。
如无相反证明,在作品上署名的公民、法人或者其他组织为作者。
第十二条改编、翻译、注释、整理已有作品而产生的作品,其著作权由改编、翻译、注释、整理人享有,但行使著作权时不得侵犯原作品的著作权。
第十三条两人以上合作创作的作品,著作权由合作作者共同享有。没有参加创作的人,不能成为合作作者。
合作作品可以分割使用的,作者对各自创作的部分可以单独享有著作权,但行使著作权时不得侵犯合作作品整体的著作权。
第十四条汇编若干作品、作品的片段或者不构成作品的数据或者其他材料,对其内容的选择或者编排体现独创性的作品,为汇编作品,其著作权由汇编人享有,但行使著作权时,不得侵犯原作品的著作权。
第十六条公民为完成法人或者其他组织工作任务所创作的作品是职务作品,除本条第二款的规定以外,著作权由作者享有,但法人或者其他组织有权在其业务范围内优先使用。作品完成两年内,未经单位同意,作者不得许可第三人以与单位使用的相同方式使用该作品。
有下列情形之一的职务作品,作者享有署名权,著作权的其他权利由法人或者其他组织享有,法人或者其他组织可以给予作者奖励:
(一)主要是利用法人或者其他组织的物质技术条件创作,并由法人或者其他组织承担责任的工程设计图、产品设计图、地图、计算机软件等职务作品;
(二)法律、行政法规规定或者合同约定著作权由法人或者其他组织享有的职务作品。
第十七条受委托创作的作品,著作权的归属由委托人和受托人通过合同约定。合同未作明确约定或者没有订立合同的,著作权属于受托人。
第十九条著作权属于公民的,公民死亡后,其本法第十条第一款第(五)项至第(十七)项规定的权利在本法规定的保护期内,依照继承法的规定转移。
著作权属于法人或者其他组织的,法人或者其他组织变更、终止后,其本法第十条第一款第(五)项至第(十七)项规定的权利在本法规定的保护期内,由承受其权利义务的法人或者其他组织享有;没有承受其权利义务的法人或者其他组织的,由国家享有。
第二十条作者的署名权、修改权、保护作品完整权的保护期不受限制。
第二十一条公民的作品,其发表权、本法第十条第一款第(五)项至第(十七)项规定的权利的保护期为作者终生及其死亡后五十年,截止于作者死亡后第五十年的12月31日;如果是合作作品,截止于最后死亡的作者死亡后第五十年的12月31日。
法人或者其他组织的作品、著作权(署名权除外)由法人或者其他组织享有的职务作品,其发表权、本法第十条第一款第(五)项至第(十七)项规定的权利的保护期为五十年,截止于作品首次发表后第五十年的12月31日,但作品自创作完成后五十年内未发表的,本法不再保护。
第二十二条在下列情况下使用作品,可以不经著作权人许可,不向其支付报酬,但应当指明作者姓名、作品名称,并且不得侵犯著作权人依照本法享有的其他权利:
(一)为个人学习、研究或者欣赏,使用他人已经发表的作品;
(二)为介绍、评论某一作品或者说明某一问题,在作品中适当引用他人已经发表的作品;
(三)为报道时事新闻,在报纸、期刊、广播电台、电视台等媒体中不可避免地再现或者引用已经发表的作品;
(四)报纸、期刊、广播电台、电视台等媒体刊登或者播放其他报纸、期刊、广播电台、电视台等媒体已经发表的关于政治、经济、宗教问题的时事性文章,但作者声明不许刊登、播放的除外;
(五)报纸、期刊、广播电台、电视台等媒体刊登或者播放在公众集会上发表的讲话,但作者声明不许刊登、播放的除外;
(六)为学校课堂教学或者科学研究,翻译或者少量复制已经发表的作品,供教学或者科研人员使用,但不得出版发行;
(七)国家机关为执行公务在合理范围内使用已经发表的作品;
(八)图书馆、档案馆、纪念馆、博物馆、美术馆等为陈列或者保存版本的需要,复制本馆收藏的作品;
(九)免费表演已经发表的作品,该表演未向公众收取费用,也未向表演者支付报酬;
(十)对设置或者陈列在室外公共场所的艺术作品进行临摹、绘画、摄影、录像;
(十一)将中国公民、法人或者其他组织已经发表的以汉语言文字创作的作品翻译成少数民族语言文字作品在国内出版发行;
(十二)将已经发表的作品改成盲文出版。
前款规定适用于对出版者、表演者、录音录像制作者、广播电台、电视台的权利的限制。
第二十三条为实施九年制义务教育和国家教育规划而编写出版教科书,除作者事先声明不许使用的外,可以不经著作权人许可,在教科书中汇编已经发表的作品片段或者短小的文字作品、音乐作品或者单幅的美术作品、摄影作品,但应当按照规定支付报酬,指明作者姓名、作品名称,并且不得侵犯著作权人依照本法享有的其他权利。
前款规定适用于对出版者、表演者、录音录像制作者、广播电台、电视台的权利的限制。
第三章著作权许可使用和转让合同
第二十四条使用他人作品应当同著作权人订立许可使用合同,本法规定可以不经许可的除外。
许可使用合同包括下列主要内容:
(一)许可使用的权利种类;
(二)许可使用的权利是专有使用权或者非专有使用权;
(三)许可使用的地域范围、期间;
(四)付酬标准和办法;
(五)违约责任;
(六)双方认为需要约定的其他内容。
第二十五条转让本法第十条第一款第(五)项至第(十七)项规定的权利,应当订立书面合同。
权利转让合同包括下列主要内容:
(一)作品的名称;
(二)转让的权利种类、地域范围;
(三)转让价金;
(四)交付转让价金的日期和方式;
(五)违约责任;
(六)双方认为需要约定的其他内容。
第四章出版、表演、录音录像、播放
第三十条图书出版者出版图书应当和著作权人订立出版合同,并支付报酬。
第三十一条图书出版者对著作权人交付出版的作品,按照合同约定享有的专有出版权受法律保护,他人不得出版该作品。
第三十二条著作权人应当按照合同约定期限交付作品。图书出版者应当按照合同约定的出版质量、期限出版图书。
图书出版者不按照合同约定期限出版,应当依照本法第五十四条的规定承担民事责任。
图书出版者重印、再版作品的,应当通知著作权人,并支付报酬。图书脱销后,图书出版者拒绝重印、再版的,著作权人有权终止合同。
第三十三条著作权人向报社、期刊社投稿的,自稿件发出之日起十五日内未收到报社通知决定刊登的,或者自稿件发出之日起三十日内未收到期刊社通知决定刊登的,可以将同一作品向其他报社、期刊社投稿。双方另有约定的除外。
作品刊登后,除著作权人声明不得转载、摘编的外,其他报刊可以转载或者作为文摘、资料刊登,但应当按照规定向著作权人支付报酬。
第三十四条图书出版者经作者许可,可以对作品修改、删节。
报社、期刊社可以对作品作文字性修改、删节。对内容的修改,应当经作者许可。
第三十五条出版改编、翻译、注释、整理、汇编已有作品而产生的作品,应当取得改编、翻译、注释、整理、汇编作品的著作权人和原作品的著作权人许可,并支付报酬。
第四十条录音录像制作者使用他人作品制作录音录像制品,应当取得著作权人许可,并支付报酬。
录音录像制作者使用改编、翻译、注释、整理已有作品而产生的作品,应当取得改编、翻译、注释、整理作品的著作权人和原作品著作权人许可,并支付报酬。
录音制作者使用他人已经合法录制为录音制品的音乐作品制作录音制品,可以不经著作权人许可,但应当按照规定支付报酬;著作权人声明不许使用的不得使用。
第四十一条录音录像制作者制作录音录像制品,应当同表演者订立合同,并支付报酬。
第四十二条录音录像制作者对其制作的录音录像制品,享有许可他人复制、发行、出租、通过信息网络向公众传播并获得报酬的权利;权利的保护期为五十年,截止于该制品首次制作完成后第五十年的12月31日。
被许可人复制、发行、通过信息网络向公众传播录音录像制品,还应当取得著作权人、表演者许可,并支付报酬。
第五章法律责任和执法措施
第四十七条有下列侵权行为的,应当根据情况,承担停止侵害、消除影响、赔礼道歉、赔偿损失等民事责任:
(一)未经著作权人许可,发表其作品的;
(二)未经合作作者许可,将与他人合作创作的作品当作自己单独创作的作品发表的;
(三)没有参加创作,为谋取个人名利,在他人作品上署名的;
(四)歪曲、篡改他人作品的;
(五)剽窃他人作品的;
(六)未经著作权人许可,以展览、摄制电影和以类似摄制电影的方法使用作品,或者以改编、翻译、注释等方式使用作品的,本法另有规定的除外;
(七)使用他人作品,应当支付报酬而未支付的;
(八)未经电影作品和以类似摄制电影的方法创作的作品、计算机软件、录音录像制品的著作权人或者与著作权有关的权利人许可,出租其作品或者录音录像制品的,本法另有规定的除外;
(九)未经出版者许可,使用其出版的图书、期刊的版式设计的;
(十)未经表演者许可,从现场直播或者公开传送其现场表演,或者录制其表演的;
(十一)其他侵犯著作权以及与著作权有关的权益的行为。
根据著作权法及实施条例规定,著作权人对作品享有5种权利:
(1)发表权:即决定作品是否公之于众的权利。
(2)署名权:即表明作者身份,在作品上署名的权利。
(3)修改权:即修改或授权他人修改作品的权利。
(4)保护作品完整权:即保护作品不受歪曲、篡改的权利。
(5)使用权、使用许可权和获取报酬权、转让权:即以复制、表演、播放、展览、发行、摄制电影、电视、录像,或者改编、翻译、注释和编辑等方式使用作品的权利,以及许可他人以上述方式使用作品,并由此获得报酬的权利。
根据著作权法的相关规定,著作权的保护是有一定期限的。
(1)著作权属于公民。署名权、修改权、保护作品完整权的保护期没有任何限制,永远属于保护范围。而发表权、使用权和获得报酬权的保护期为作者终生及其死亡后的50年(第50年的12月31日)。作者死亡后,著作权依照继承法进行转移。
(2)著作权属于单位。发表权、使用权和获得报酬权的保护期为50年(首次发表后的第50年的12月31日),若50年内未发表的,不予保护。但单位变更、终止后,其著作权由承受其权利义务的单位享有。
当第三方需要使用时,需得到著作权人的使用许可,双方应签订相应的合同。合同中应包括许可使用作品的方式,是否专有使用,许可的范围与时间期限,报酬标准与方法,以及违约责任等。若合同未明确许可的权力,需再次经著作权人许可。合同的有效期限不超过10年,期满时可以续签。
对于出版者、表演者、录音录像制作者、广播电台、电视台而言,在下列情况下使用作品,可以不经著作权人许可、不向其支付报酬。但应指明作者姓名、作品名称,不得侵犯其他著作权。
(1)为个人学习、研究或欣赏,使用他人已经发表的作品。
(2)为介绍、评论某一个作品或说明某一个问题,在作品中适当引用他人已经发表的作品。
(3)为报道时事新闻,在报纸、期刊、广播、电视节目或新闻纪录影片中引用已经发表的作品。
(4)报纸、期刊、广播电台、电视台刊登或播放其他报纸、期刊、广播电台、电视台已经发表的社论、评论员文章。
(5)报纸、期刊、广播电台、电视台刊登或者播放在公众集会上发表的讲话,但作者声明不许刊登、播放的除外。
(6)为学校课堂教学或科学研究,翻译或者少量复制已经发表的作品,供教学或科研人员使用,但不得出版发行。
(7)国家机关为执行公务使用已经发表的作品。
(8)图书馆、档案馆、纪念馆、博物馆和美术馆等为陈列或保存版本的需要,复制本馆收藏的作品。
(9)免费表演已经发表的作品。
(10)对设置或者陈列在室外公共场所的艺术作品进行临摹、绘画、摄影及录像。
(11)将已经发表的汉族文字作品翻译成少数民族文字在国内出版发行。
(12)将已经发表的作品改成盲文出版。
15. 结构化分析方法中,数据流图中的元素在( )中进行定义。
A. 加工逻辑
B. 实体联系图
C. 流程图
D. 数据字典
数据流图也称数据流程图(Data Flow Diagram,DFD),它是一种便于用户理解、分析系统数据流程的图形工具。它摆脱了系统的物理内容,精确地在逻辑上描述系统的功能、输入、输出和数据存储等,是系统逻辑模型的重要组成部分。
1)数据流图的基本图形元素
数据流图中的基本图形元素包括数据流(Data Flow)、加工(Process)、数据存储(Data Store)和外部实体(Extemal Agent)。其中,数据流、加工和数据存储用于构建软件系统内部的数据处理模型;外部实体表示存在于系统之外的对象,用来帮助用户理解系统数据的来源和去向。
(1)数据流。
数据流由一组固定成分的数据组成,表示数据的流向。在DFD中,数据流的流向可以有以下几种:从一个加工流向另一个加工;从加工流向数据存储(写):从数据存储流向加工(读);从外部实体流向加工(输入);从加工流向外部实体(输出)。
DFD中的每个数据流用一个定义明确的名字表示。除了流向数据存储或从数据存储流出的数据流不必命名外,每个数据流都必须有一个合适的名字,以反映该数据流的含义。值得注意的是,DFD中描述的是数据流,而不是控制流。
数据流或者由具体的数据属性(也称为数据结构)构成,或者由其他数据流构成。组合数据流是由其他数据流构成的数据流,它们用于在高层的数据流图中组合相似的数据流,以使数据流图更便于阅读。
(2)加工。
加工描述了输入数据流到输出数据流之间的变换,也就是输入数据流经过什么处理后变成了输出数据流。每个加工都有一个名字和编号。编号能反映出该加工位于分层DFD中的哪个层次和哪张图中,也能够看出它是哪个加工分解出来的子加工。
一个加工可以有多个输入数据流和多个输出数据流,但至少有一个输入数据流和一个输出数据流。
(3)数据存储。
数据存储用来存储数据。通常,一个流入加工的数据流经过加工处理后就消失了,而它的某些数据(或全部数据)可能被加工成输出数据流,流向其他加工或外部实体。除此之外,在软件系统中还常常要把某些信息保存下来以供以后使用,这时可以使用数据存储。
每个数据存储都有一个定义明确的名字标识。可以有数据流流入数据存储,表示数据的写入操作;也可以有数据流从数据向数据存储,表示对数据的修改。
这里要说明的是,DFD中的数据存储在具体实现时可以用文件系统实现,也可以用数据库系统实现。数据存储的存储介质可以是磁盘、磁带或其他存储介质。
(4)外部实体(外部主体)。
外部实体是指存在于软件系统之外的人员或组织,它指出系统所需数据的发源地(源)和系统所产生的数据的归宿地(宿)。例如,对于一个考务处理系统而言,考生向系统提供报名单(输入数据流),所以考生是考务处理系统的一个源;而考务处理系统要将考试成绩的统计分析表(输出数据流)传递给考试中心,所以考试中心是该系统的一个宿。
在许多系统中,某个源和某个宿可以是同一个人员或组织,此时,在DFD中可以用同一个符号表示。考生向系统提供报名单,而系统向考生送出准考证,所以在考务处理系统中,考生既是源又是宿。
源和宿采用相同的图形符号表示,当数据流从该符号流出时,表示它是源;当数据流流向该符号时,表示它是宿;当两者皆有时,表示它既是源又是宿。
2)数据流图的扩充符号
在DFD中,一个加工可以有多个输入数据流和多个输出数据流,此时可以加上一些扩充符号来描述多个数据流之间的关系。
(1)星号(*)。
星号表示数据流之间存在"与"关系。如果是输入流则表示所有输入数据流全部到达后才能进行加工处理;如果是输出流则表示加工结束将同时产生所有的输出数据流。
(2)加号(+)。
加号表示数据流之间存在"或"关系。如果是输入流则表示其中任何一个输入数据流到达后就能进行加工处理;如果是输入流则表示加工处理的结果是至少产生其中一个输出数据流。
(3)异或(⊕)。
异或表示数据流之间存在"互斥"关系。如果是输入流则表示当且仅当其中一个输入流到达后才能进行加工处理;如果是输出流则表示加工处理的结果是仅产生这些输出数据流中的一个。
3)数据流图的层次结构
从原理上讲,只要纸足够大,一个软件系统的分析模型就可以画在一张纸上。然而,一个复杂的软件系统可能涉及上百个加工和上百个数据流,甚至更多。如果将它们画在一张图上,则会十分复杂,不易阅读,也不易理解。
根据自顶向下逐层分解的思想,可以将数据流图按照层次结构来绘制,每张图中的加工个数可大致控制在"7加减2"的范围内,从而构成一套分层数据流图。
(1)层次结构。
分层数据流图的顶层只有一张图,其中只有一个加工,代表整个软件系统,该加工描述了软件系统与外界之间的数据流,称为顶层图。
顶层图中的加工(即系统)经分解后的图称为0层图,也只有一张。处于分层数据流图最底层的图称为底层图,在底层图中,所有的加工不再进行分解。分层数据流图中的其他图称为中间层,其中至少有一个加工(也可以是所有加工)被分解成一张子图。在整套分层数据流图中,凡是不再分解成子图的加工称为基本加工。
(2)图和加工的编号。
首先介绍父图和子图的概念。
如果某图(记为A)中的某一个加工分解成一张子图(记为B),则称A是B的父图,B是A的子图。若父图中有n个加工,则它可以有0一刀张子图,但每张子图只对应一张父图。
为了方便对图进行管理和查找,可以采用下列方式对DFD中的图和加工编号。
①顶层图中只有一个加工(代表整个软件系统),该加工不必编号。
②0层图中的加工编号分别为1、2、3--。
③子图号就是父图中被分解的加工号。
④对于子图中加工的编号,若父图中的加工号为X的加工分解成某一子图,则该子图中的加工编号分别为x.1、x.2、X.3…。
4)分层数据流图的审查
在分层数据流图画好后,应该认真检查图中是否存在错误或不合理(不理想)的部分。
(1)分层数据流图的一致性和完整性。
①分层数据流图的一致性。
a.父图与子图的平衡。
b.数据守恒。
c.局部数据存储。
d.一个加工的输出数据流不能与该加工的输入数据流同名。
②分层数据流图的完整性。
a.每个加工至少有一个输入数据流和一个输出数据流。
b.在整套分层数据流图中,每个数据存储应至少有一个加工对其进行读操作,另一个加工对其进行写操作。
c.分层数据流图中的每个数据流和文件都必须命名(除了流入或流出数据存储的数据流),并保持与数据字典一致。
d.分层数据流图中的每个基本加工都应有一个加工规约。
(2)构造分层DFD时需要注意的问题。
①适当命名。
a.名字应反映整个对象(如数据流、加工),而不是只反映它的某一部分。
b.避免使用空洞的、含义不清的名字,如"数据""信息""处理""统计"等。
c.如果发现某个数据流或加工难以命名,往往是DFD分解不当的征兆,此时应考虑重新分解。
②画数据流而不是控制流。
③避免一个加工有过多的数据流。
a.把需要重新分解的某张图的所有子图连接成一张图。
b.把连接后的图重新划分成几个部分,使各部分之间的联系最小。
c.重新定义父图,即第b步中的每个部分作为父图中的一个加工。
d.重新建立各子图,即第b步中的每个部分都是一张子图。
e.为所有的加工重新命名并编号。
④分解尽可能均匀。
⑤先考虑确定状态,忽略琐碎的细节。
⑥随时准备重画。
(3)分解的程度。
在自顶向下画数据流图时,为了便于对分解层数进行把握,可以参照以下几条与分解有关的原则。
①7加减2。
②分解应自然,概念上应合理、清晰。
③只要不影响DFD的易理解性,可适当增加子加工数量,以减少层数。
④一般来说,上层分解得快一些(即多分解几个加工),下层分解得慢一些(即少分解几个加工)。
⑤分解要均匀。
结构化分析(Structured Analysis, SA)方法是面向数据流进行需求分析的方法,采用自顶向下、逐层分解的方法,建立系统的处理流程,以数据流图和数据字典为主要工具,建立系统的逻辑模型。SA方法的分析结果由以下几部分组成:一套分层的数据流图、一本数据词典、一组小说明。
1)数据流图
数据流图(Data Flow Diagram, DFD)用来描述数据流从输入到输出的变换流程。它以图形的方式描绘数据在系统中流动和处理的过程,它只反映系统必须完成的逻辑功能,所以是一种功能模型。
DFD的基本元素如下图所示。
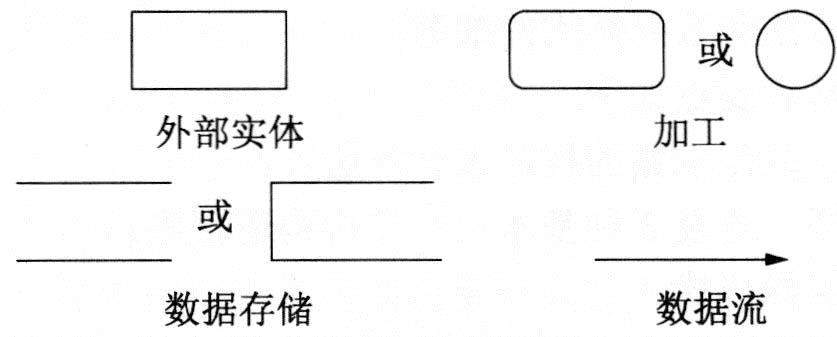
DFD的基本元素
(1)数据流:由一组固定成分的数据组成,表示数据的流向。
(2)加工:描述了输入数据流到输出数据流之间的变换,也就是输入数据流经过某种处理后变成了输出数据流。
(3)数据存储:用来表示暂时存储的数据,每个数据存储都有一个名字。
(4)外部实体:它是指存在于软件系统之外的人员或组织。
2)数据字典
数据流图仅描述了系统的"分解",但没有对图中各成分进行说明。数据词典就是用来定义数据流图中的各个成分含义的。
数据字典有4类条目,包括数据流、数据项、数据存储和基本加工。
3)加工逻辑的描述
加工逻辑的描述用来说明DFD中的数据加工的细节,表达"做什么",而不是"怎样做"。描述工具有结构化语言、判定表和判定树。
SA方法使用抽象模型的概念,按照软件内部数据传递、变换的关系,自顶向下、逐层分解,直至找到满足功能要求的所有可实现的软件为止。SA方法给出一组帮助系统分析人员产生功能规约的原理与技术。它一般利用图形表达用户需求,使用的手段主要有数据流图、数据字典、结构化语言、判定表及判定树等。
SA方法的步骤如下:
(1)分析当前的情况,做出反映当前物理模型的数据流图(Data Flow Diagram,DFD)。
(2)推导出等价的逻辑模型的DFD。
(3)设计新的逻辑系统,生成数据字典和基元描述。
(4)建立人机接口,提出可供选择的目标系统物理模型的DFD。
(5)确定各种方案的成本和风险等级,据此对各种方案进行分析。
(6)选择一种方案。
(7)建立完整的需求规约。
16. 良好的启发式设计原则上不包括( )。
A. 提高模块独立性
B. 模块规模越小越好
C. 模块作用域在其控制域之内
D. 降低模块接口复杂性
防火墙的设计原则如下。
(1)由内到外、由外到内的业务流均要经过防火墙。
(2)只允许本地安全策略认可的业务流通过防火墙,实行默认拒绝原则。
(3)严格限制外部网络的用户进入内部网络。
(4)具有透明性,方便内部网络用户,保证正常的信息通过。
(5)具有抗穿透攻击能力,强化记录、审计和报警。
17. 如下所示的软件项目活动图中,顶点表示项目里程碑,连接顶点的边表示包含的活动,边上的权重表示活动的持续时间(天), 则完成该项目的最短时间为(17)天。在该活动图中,共有(18)条关键路径。
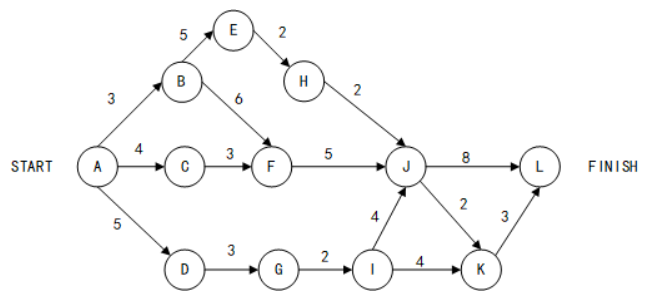
A. 17
B. 19
C. 20
D. 22
活动图(Activity Diagram)是一种特殊的状态图,它展现了在系统内从一个活动到另一个活动的流程。
活动图专注于系统的动态视图,它对于系统的功能建模特别重要,并强调对象间的控制流程。活动图一般包括活动状态和动作状态、转换和对象。当对一个系统的动态方面进行建模时,通常有两种使用活动图的方式:对工作流建模;对操作建模。
在AOV网络中,如果边上的权表示完成该活动所需的时间,则称这样的AOV为AOE网络。例如,下图表示一个具有10个活动的某个工程的AOE网络。图中有7个结点,分别表示事件V1~V7,其中V1表示工程开始状态,V7表示工程结束状态,边上的权表示完成该活动所需的时间。
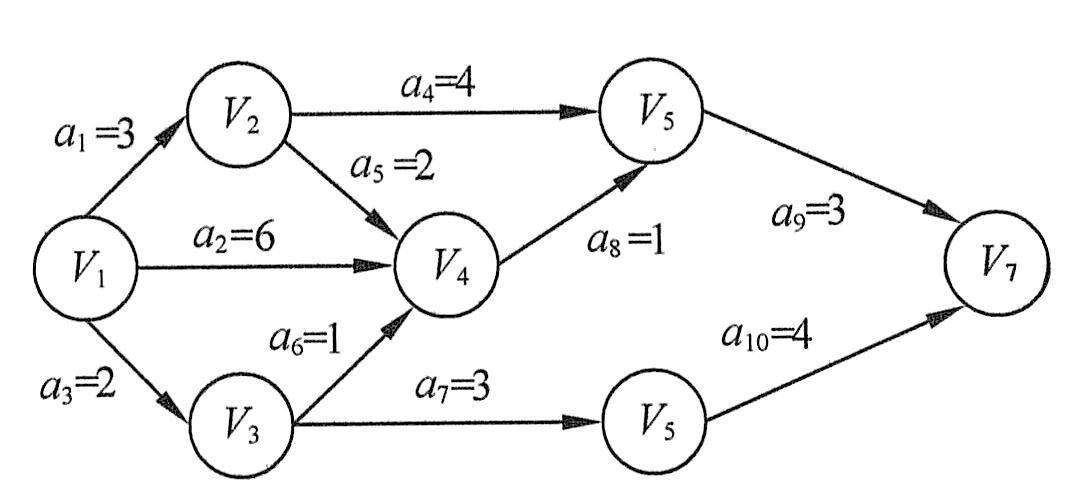
AOE网络的例子
因AOE网络中的某些活动可以并行地进行,所以完成工程的最少时间是从开始结点到结束结点的最长路径长度,称从开始结点到结束结点的最长路径为关健路径(临界路径),关键路径上的活动为关键活动。为了找出给定的AOE网络的关键活动,从而找出关键路径,先定义几个重要的量:
Ve(j)、V1(j):结点j事件最早、最迟发生时间。
e(i)l(i):活动i最早、最迟开始时间。
从源点V1到某结点Vj的最长路径长度,称为事件Vj的最早发生时间,记作Ve(j)。Ve(j)也是以Vj为起点的出边<Vj,Vk>所表示的活动ai的最早开始时间e(i)。
在不推迟整个工程完成的前提下,一个事件Vj允许的最迟发生时间,记作V1(j)。显然,l(i)=V1(j)-(ai所需时间),其中j为ai活动的终点。满足条件l(i)=e(i)的活动为关键活动。
求结点Vj的Ve(j)和V1(j)可按以下两步来做:
由源点开始向汇点递推
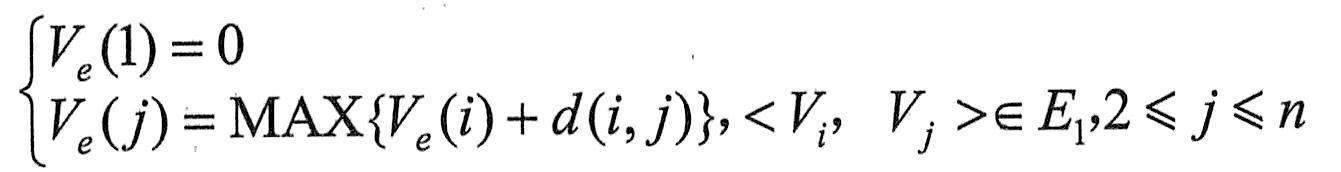
其中,E1是网络中以Vj为终点的入边集合。
由汇点开始向源点递推
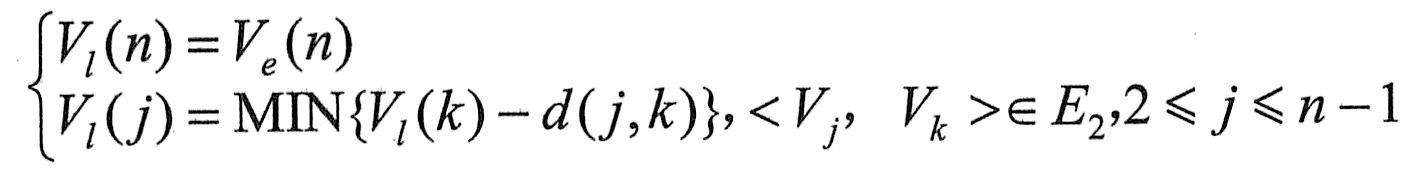
其中,E2是网络中以Vj为起点的出边集合。
要求一个AOE的关键路径,一般需要根据以上变量列出一张表格,逐个检查。例如,求上图所示的AOE的关键路径的表格如下表所示。
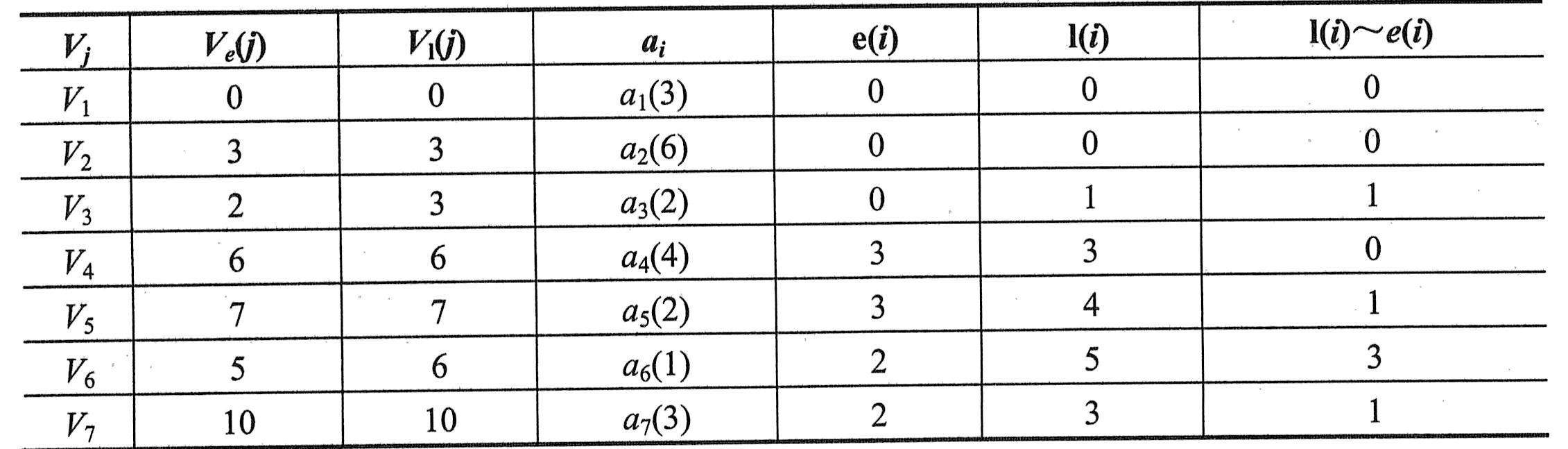
求关键路径的过程

因此,上图的关键活动为a1、a2、a4、a8和a9,其对应的关键路径有两条,分别为(V1,V2,V5,V7)和(V1,V4,V5,V7),长度都是10。
一般来说,不在关键路径上的活动时间的缩短,不能缩短整个工期。而不在关键路径上的活动时间的延长,可能导致关键路径的变化,因此可能影响整个工期。
在实际解答试题时,一般所给出的活动数并不多,我们可以采取观察法求得其关键路径,即路径最长的那条路径就是关键路径。
18. 如下所示的软件项目活动图中,顶点表示项目里程碑,连接顶点的边表示包含的活动,边上的权重表示活动的持续时间(天), 则完成该项目的最短时间为(17)天。在该活动图中,共有(18)条关键路径。
A. 1
B. 2
C. 3
D. 4
19. 软件项目成本估算模型模型COCOMO II中,体系结构阶段模型基于( )进行估算。
A. 应用程序点数量
B. 功能点数量
C. 复用或生成的代码行数
D. 源代码的行数
RPR的体系结构如下图所示。RPR采用了双环结构,由内层的环1和外层的环0组成,每个环都是单方向传送。相邻工作站之间的跨距包含传送方向相反的两条链路。RPR支持多达255个工作站,最大环周长为2000km。
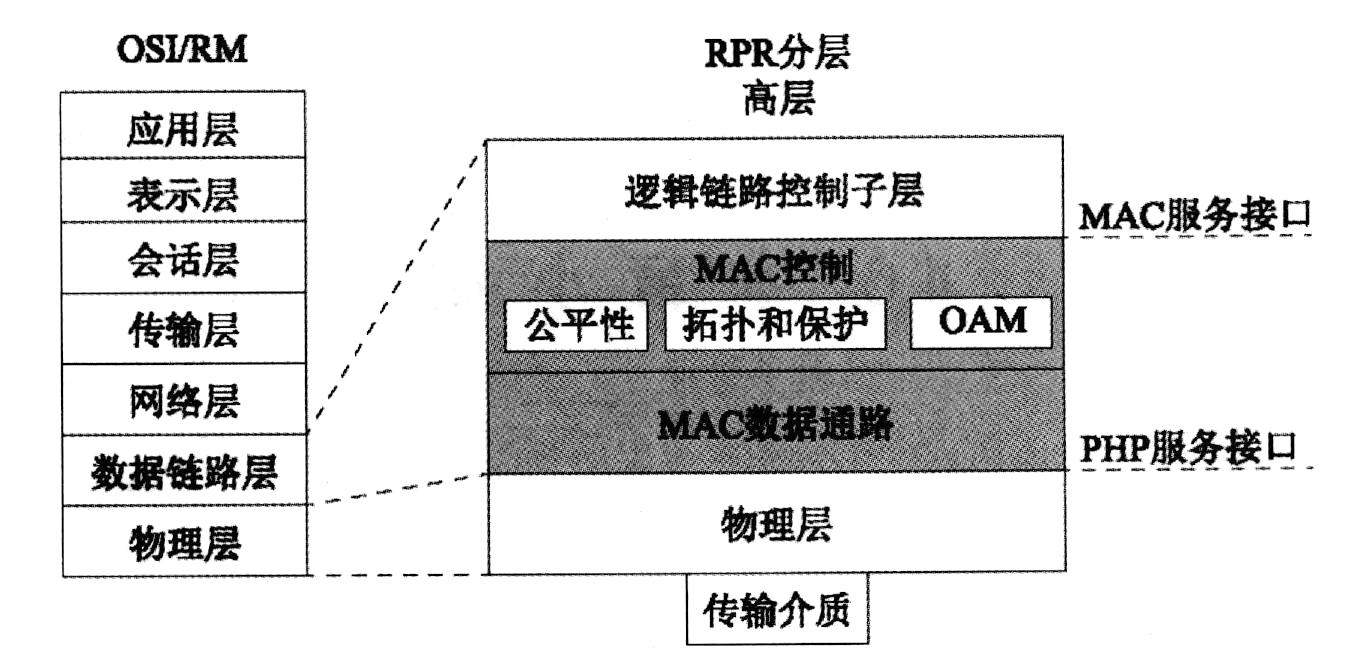
RPR体系结构
成本估算是对完成项目活动所需资金进行近似估算的过程,其主要作用是确定完成项目工作所需的成本数额。
成本估算是在某特定时点,根据已知信息所做出的成本预测。在估算成本时,需要识别和分析可用于启动与完成项目的备选成本方案;需要权衡备选成本方案并考虑风险,如比较自制成本与外购成本、购买成本与租赁成本及多种资源共享方案,以优化项目成本。
输入
成本管理计划
成本管理计划规定了如何管理和控制项目成本,包括估算活动成本的方法和需要达到的准确度。
人力资源管理计划
人力资源管理计划提供了项目人员配备情况、人工费率和相关奖励/认可方案,是制订项目成本估算时必须考虑的因素。
范围基准
范围基准包含以下内容:
.范围说明书:提供了产品描述、验收标准、主要可交付成果、项目边界及项目的假设条件和制约因素。在估算项目成本时必须设定的一项基本假设是,估算将仅限于直接成本,还是也包括间接成本。间接成本是无法直接追溯到某个具体项目的成本,因此只能按某种规定的会计程序进行累计并合理分摊到多个项目中。有限的项目预算是很多项目中最常见的制约因素。其他制约因素包括规定的交付日期、可用的熟练资源和组织政策等。
.工作分解结构:指明了项目的全部组件之间及全部可交付成果之间的相互关系。
.WBS词典:提供了可交付成果的详细信息,并描述了为产出可交付成果,WBS各组件所需进行的工作。
范围基准中可能还包括与合同和法律有关的信息,如健康、安全、安保、绩效、环境、保险、知识产权、执照和许可证等。所有这些信息都应该在进行成本估算时加以考虑。
项目进度计划
项目工作所需的资源种类、数量和使用时间,都会对项目成本产生很大影响。进度活动所需的资源及其使用时间,是本过程的重要输入。在估算活动资源过程中,已经估算出开展进度活动所需的人员数量、人时数及材料和设备数量。活动资源估算与成本估算密切相关。如果项目预算中包括融资成本(如利息),或者资源消耗取决于活动持续时间的长短,那么活动持续时间估算就会对成本估算产生影响。如果成本估算中包含时间敏感型成本,如通过工会集体签订定期劳资协议的员工或价格随季节波动的材料,那么活动持续时间估算也会影响成本估算。
风险登记册
通过审查风险登记册,考虑应对风险所需的成本。风险既可以是威胁,也可以是机会,通常会对活动及整个项目的成本产生影响。一般而言,在项目遇到负面风险事件后,项目的近期成本将会增加,有时还会造成项目进度延误。同样,项目团队应该对可能给业务带来好处的潜在机会保持敏感。
事业环境因素
可能影响成本估算过程的事业环境因素包括市场条件和发布的商业信息。
组织过程资产
可能影响成本估算过程的组织过程资产包括成本估算政策、成本估算模板、历史信息和经验教训。
工具与技术
专家判断
基于历史信息,专家判断可以对项目环境及以往类似项目的信息提供有价值的见解。专家判断还可以对是否联合使用多种估算方法,以及如何协调方法之间的差异做出决定。
类比估算
类比估算是指以过去类似项目的参数值(如范围、成本、预算和持续时间等)或规模指标(如尺寸、重量和复杂性等)为基础,来估算当前项目的同类参数或指标。在估算成本时,这项技术以过去类似项目的实际成本为依据,来估算当前项目的成本。这是一种粗略的估算方法,有时需要根据项目复杂性方面的已知差异进行调整。
在项目详细信息不足时,例如在项目的早期阶段,就经常使用类比估算技术来估算成本数值。该方法综合利用了历史信息和专家判断。
相对于其他估算技术,类比估算通常成本较低、耗时较少,但准确性也较低。可以针对整个项目或项目中的某个部分,进行类比估算。类比估算可以与其他估算方法联合使用。如果以往项目是本质上而不只是表面上类似,并且从事估算的项目团队成员具备必要的专业知识,那么类比估算就最为可靠。
参数估算
参数估算是指利用历史数据之间的统计关系和其他变量,来进行项目工作的成本估算。参数估算的准确性取决于参数模型的成熟度和基础数据的可靠性。参数估算可以针对整个项目或项目中的某个部分,并可与其他估算方法联合使用。
自下而上估算
自下而上估算是对工作组成部分进行估算的一种方法。首先对单个工作包或活动的成本进行最具体、细致的估算;然后把这些细节性成本向上汇总或“滚动”到更高层次,用于后续报告和跟踪。自下而上估算的准确性及其本身所需的成本,通常取决于单个活动或工作包的规模和复杂程度。
三点估算
通过考虑估算中的不确定性与风险,使用三种估算值来界定活动成本的近似区间,可以提高活动成本估算的准确性:
最可能成本(Cm):对所需进行的工作和相关费用进行比较现实的估算所得到的活动成本。
最乐观成本(Co):基于活动的最好情况所得到的活动成本。
最悲观成本(Cp):基于活动的最差情况所得到的活动成本。
基于活动成本在三种估算值区间内的贝塔分布,使用下面公式来计算预期成本(Ce):
Ce=(Co+4Cm+Cp)/6
储备分析
为应对成本的不确定性,成本估算中可以包括应急储备(有时称为“应急费用”)。应急储备是包含在成本基准内的一部分预算,用来应对已经接受的已识别风险,以及已经制定应急或减轻措施的已识别风险。应急储备通常是预算的一部分,用来应对那些会影响项目的“已知—未知(已经识别但无法主动管理)”风险。例如,预知有些项目可交付成果需要返工,却不知道返工的工作量是多少,可以预留应急储备来应对这些未知数量的返工工作。可以为某个具体活动建立应急储备,也可以为整个项目建立应急储备,还可以同时建立。应急储备可取成本估算值的某一百分比、某个固定值或者通过定量分析来确定。
随着项目信息越来越明确,可以动用、减少或取消应急储备。应该在成本文件中清楚地列出应急储备。应急储备是成本基准的一部分,也是项目整体资金需求的一部分。
也可以估算项目所需的管理储备。管理储备是为了管理控制的目的而特别留出的项目预算,用来应对项目范围中不可预见的工作。管理储备用来应对会影响项目的“未知—未知(未知风险无法进行主动管理)”风险。管理储备不包括在成本基准中,但属于项目总预算和资金需求的一部分。当动用管理储备资助不可预见的工作时,就要把动用的管理储备增加到成本基准中,从而导致成本基准变更。
质量成本
在估算活动成本时,可能要用到关于质量成本(参见第15章内容)的各种假设。
项目管理软件
项目管理应用软件、电子表单、模拟和统计工具等,可用来辅助成本估算。这些工具能简化某些成本估算技术的使用,使人们能快速考虑多种成本估算方案。
卖方投标分析
在成本估算过程中,可能需要根据合格卖方的投标情况,分析项目成本。在用竞争性招标选择卖方的项目中,项目团队需要开展额外的成本估算工作,以便审查各项可交付成果的价格,并计算出组成项目最终总成本的各分项成本。
群体决策技术
基于团队的方法(如头脑风暴、德尔菲技术或名义小组技术)可以调动团队成员的参与,以提高估算的准确度,并提高对估算结果的责任感。选择一组与技术工作密切相关的人员参与估算过程,可以获取额外的信息,得到更准确的估算。另外,让成员亲自参与估算,能够提高他们对实现估算的责任感。
输出
活动成本估算
活动成本估算是对完成项目工作可能需要的成本的量化估算。成本估算可以是汇总的或详细分列的。成本估算应该覆盖活动所使用的全部资源,包括(但不限于)直接人工、材料、设备、服务、设施和信息技术,以及一些特殊的成本种类,如融资成本(包括利息)、通货膨胀补贴、汇率或成本应急储备。如果间接成本也包含在项目估算中,则可在活动层次或更高层次上计列间接成本
估算依据
估算依据即成本估算所需的支持信息,其数量和种类因应用领域而异。估算依据应清晰、完整地说明成本估算是如何得出的。
活动成本估算的支持信息可包括:
.关于估算依据的文件(如估算是如何编制的)。
.关于全部假设条件的文件。
.关于各种已知制约因素的文件。
.对估算区间的说明。
.对最终估算的置信水平的说明。
项目文件更新
可能需要更新的项目文件为风险登记册。
20. 某表达式的语法树如下图所示,其后缀式(逆波兰式)是( )。

A. abcd-+*
B. ab-c+d*
C. abc-d*+
D. ab-cd+*
1)定义
树型结构是一类重要的非线性数据结构,其中以树和二叉树最为常用。
树是由一个或多个节点组成的有限集T,它满足以下两个条件:有一个特定的节点称为根节点;其余的节点分成m个互不相交的有限集T1, T2, …, Tm,其中每个集又都是一棵树,称T1, T2, …, Tm为根节点的子树。
可见树的定义是递归的,即一棵树由子树构成,子树又由更小的子树构成。
2)相关概念
.一个节点的子树数目称为该节点的度。
.树中各节点的度的最大值称为树的度。
.树中节点的最大层次称为树的深度。
若将树中节点的各子树看成是从左到右具有次序的,即不能交换,则称该树为有序树,否则称为无序树。
3)树的遍历
在应用树结构时,常要求按某种次序获得树中全部节点的信息,这可通过树的遍历操作来实现,常用的遍历方法如下。
.前序:先访问根节点,然后从左到右遍历根节点的各棵子树。
.后序:先从左到右遍历根节点的各棵子树,然后访问根节点。
.层序:先访问处于1层上的节点,然后从左到右依次访问处于2层、3层上的节点,即从上到下、从左到右逐层访问树中各层上的节点。
21. 用C/C++语言为某个应用编写的程序,经过( )后形成可执行程序。
A. 预处理、编译、汇编、链接
B. 编译、预处理、汇编、链接
C. 汇编、预处理、链接、编译
D. 链接、预处理、编译、汇编
C++语言是一种面向对象的强类型语言,由AT&T的Bell实验室于1980年推出。
C++语言是C语言的一个向上兼容的扩充,而不是一种新语言。C++是一种支持多范型的程序设计语言,它既支持面向对象的程序设计,也支持面向过程的程序设计。
C++支持基本的面向对象概念,包括对象、类、方法、消息、子类和继承。C++完全支持多继承,并且通过使用try/throw/catch模式提供了一个完整的异常处理机制。它同时支持静态类型和动态类型,也完全支持多继承,不提供自动的无用存储单元收集,这必须通过程序员来实现,或者通过编程环境提供合适的代码库来予以支持。
22. 在程序的执行过程中,系统用( )实现嵌套调用(递归调用)函数的正确返回。
A. 队列
B. 优先队列
C. 栈
D. 散列表
函数可以被看作是一个由用户定义的操作。一般来说,函数用一个名字来表示,函数的操作数称为参数(parameter),由一个位于括号中并且用逗号分隔的参数表(Parameter List)指定。函数的结果被称为返回值(Return Value),返回值的类型被称为函数返回类型(Return Type)。不产生值的函数返回类型是void,意思是什么都不返回。函数执行的动作在函数体(body)中指定。函数体包含在花括号中,有时也称为函数块(Function Block)。函数返回类型以及其后的函数名、参数表和函数体构成了函数定义。
函数是C++语言程序的基本功能单元,其重要性不言而喻。函数接口的两个要素是参数和返回值。C语言中,函数的参数和返回值的传递方式有两种:值传递(Pass By Value)和指针传递(Pass by Pointer)。C++语言中多了引用传递(Pass by Reference)。
23. 假设系统中有三个进程P1、P2和P3,两种资源R1、R2。如果进程资源图如图①和图②所示,那么( )。
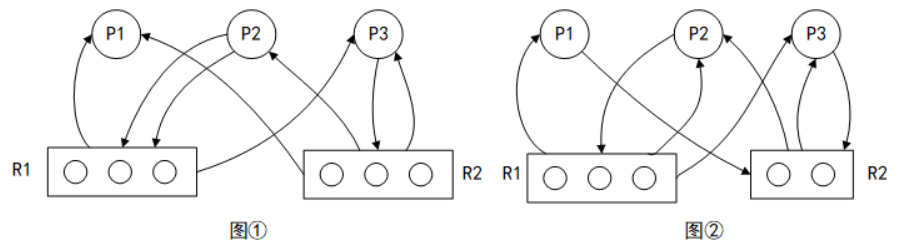
A. 图①和图②都可化简
B. 图①和图②都不可化简
C. 图①可化简,图②不可化简
D. 图①不可化简,图②可化简
24. 假设计算机系统的页面大小为4K,进程P的页面变换表如下表所示。若P要访问的逻辑地址为十六进制3C20H,那么该逻辑地址经过地址变换后,其物理地址应为( )。
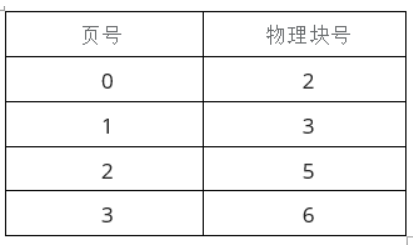
A. 2048H
B. 3C20H
C. 5C20H
D. 6C20H
由进程中的目标代码、数据等的虚拟地址组成的虚拟空间称为虚拟存储器,虚拟存储器允许用户用比内存容量大得多的地址空间来编程,以运行比内存实际容量大得多的程序。用户编程所用的地址称为逻辑地址(虚地址),而实际的内存地址则称为物理地址(实地址)。每次访问内存时都要进行逻辑地址到物理地址的转换,这种转换是由硬件完成的,而内存和外存间的信息动态调度是硬件和操作系统两者配合完成的。
(1)静态重定位:静态重定位是在虚空间程序执行之前由装配程序完成地址影射工作。静态重定位的优点是不需要硬件的支持。缺点是无法实现虚拟存储器,必须占用连续的内存空间,且难以做到程序和数据的共享。
(2)动态重定位:动态重定位是在程序执行过程中,在CPU访问内存之前,将要访问的程序或数据地址转换为内存地址。动态重定位依靠硬件地址变换机构完成,其优点主要有:可以对内存进行非连续分配,提供了虚拟存储器的基础,有利于程序段的共享。
25. 某文件系统采用索引节点管理,其磁盘索引块和磁盘数据块大小均为1KB字节且每个文件索引节点有8个地址项iaddr[0]~iaddr[7],每个地址项大小为4字节,其中iaddr[0]~iaddr[4]采用直接地址索引,iaddr[5]和iaddr[6]采用一级间接地址索引,iaddr[7] 采用二级间接地址索引。若用户要访问文件userA中逻辑块号为4和5的信息,则系统应分别采用(25), 该文件系统可表示的单个文件最大长度是( 26)KB。
A. 直接地址访问和直接地址访问
B. 直接地址访问和一级间接地址访问
C. 一级问接地址访问和一级间接地址访问
D. 一级间接地址访问和二级间接地址访问
文件管理系统就是操作系统中实现文件统一管理的一组软件和相关数据的集合。专门负责管理和存取文件信息的软件机构,简称文件系统。文件系统的功能包括按名存取、统一的用户接口、并发访问和控制、安全性控制、优化性能和差错恢复。
本知识点的要点是掌握与磁盘相关的最重要的概念与计算公式。
磁盘是最常见的一种外部存储器,它是由一至多个圆形磁盘组成的,其常见技术指标如下。
(1)磁道数=(外半径-内半径)×道密度×记录面数
说明:硬盘的第一面与最后一面是起保护作用的,一般不用于存储数据,所以在计算的时候要减掉。例如,6个双面的盘片的有效记录面数是6×2-2=10。
(2)非格式化容量=位密度×3.14×最内圈直径×总磁道数
说明:每个磁道的位密度是不相同的,但每个磁道的容量却是相同的。一般来说,0磁道是最外面的磁道,其位密度最小。
(3)格式化容量=总磁道数×每道扇区数×扇区容量
(4)平均数据传输速率=每道扇区数×扇区容量×盘片转速
说明:盘片转速是指磁盘每秒钟转多少圈。
(5)存取时间=寻道时间+等待时间
说明:寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间。显然,寻道时间与磁盘的转速没有关系。
26. 某文件系统采用索引节点管理,其磁盘索引块和磁盘数据块大小均为1KB字节且每个文件索引节点有8个地址项iaddr[0]~iaddr[7],每个地址项大小为4字节,其中iaddr[0]~iaddr[4]采用直接地址索引,iaddr[5]和iaddr[6]采用一级间接地址索引,iaddr[7] 采用二级间接地址索引。若用户要访问文件userA中逻辑块号为4和5的信息,则系统应分别采用(25), 该文件系统可表示的单个文件最大长度是( 26)KB。
A. 517
B. 1029
C. 65797
D. 66053
27. 假设系统有n (n≥5) 个进程共享资源R,且资源R的可用数为5。若采用PV操作,则相应的信号量S的取值范围应为( )。
A. -1~n-1
B. -5~5
C. -(n-1)~1
D. -(n-5)~5
为了同步一个应用的多个并发线程和协调它们对共享资源的互斥访问,内核提供了一个信号量对象和相关的信号量管理服务。信号量是一个内核对象,就像一把锁,任务获取了该信号量就可以执行期望的操作或访问相关资源,从而达到同步或互斥的目的。
信号量可以分为如下3类:
(1)二值信号量。二值信号量只能有两个值:0或1,当其值为0时,认为信号量不可使用。当其值为1时,认为信号量是可使用的。当二值信号量被创建时,既可以初始化为可使用的,也可以初始化为不可使用的。二值信号量通常作为全局资源,被需要信号量的所有任务共享。
(2)计数信号量。计数信号量使用一个计数器赋予一个数值,表示信号量令牌的个数,允许多次获取和释放。初始化时,如果计数值为0,表示信号量不可用;计数值大于0,表示信号量可用。每获取一次信号量其计数值就减1,每释放一次信号量其计数值就加1。在有些系统中,计数信号量允许实现的计数是有界的,有些则无界。同二值信号量一样,计数信号量也可用做全局资源。
(3)互斥信号量。互斥信号量是一个特殊的二值信号量,它支持所有权、递归访问、任务删除安全和优先级反转,以避免互斥固有的问题。互斥信号量初始为开锁状态,被任务获取后转到闭锁状态,当任务释放该信号量时又返回开锁状态。
通常,内核支持以下几种操作:创建和删除信号量操作、获取和释放信号量操作、清除信号量的等待队列操作以及获取信号量信息操作。
信号是当一个事件发生时产生的软中断,它将信号接收者从其正常的执行路径移开并触发相关的异步处理。本质上,信号通知其他任务或ISR运行期间发生的事件,与正常中断类似,这些事件与被通知的任务是异步的。信号的编号和类型依赖于具体的嵌入式系统的实现。通常,嵌入式系统均提供信号设施,任务可以为每个希望处理的信号提供一个信号处理程序,或是使用内核提供的默认处理程序,也可以将一个信号处理程序用于多种类型的信号。信号可以有被忽略、挂起、处理或阻塞等4种不同的响应处理。
28. 在支持多线程的操作系统中,假设进程P创建了线程T1、T2和T3, 那么以下叙述中错误的是( )。
A. 线程T1、 T2和T3可以共享程P的代码
B. 线程T1、T2可以共享P进程中T3的栈指针
C. 线程T1、T2和T3可以共享进程P打开的文件
D. 线程T1、T2和T3可以共享进程P的全局变量
线程的基本概念
线程是比进程更小的能独立运行的基本单位。在引入线程的操作系统中,线程是进程中的一个实体,是系统独立分配和调度的基本单位。线程自己基本上不拥有资源,只拥有一点在运行中必不可少的资源(如程序计数器、一组寄存器和栈),但它可与同属一个进程的其他线程共享该进程所占用的全部资源。一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行。线程也同样有就绪、等待和运行3种基本状态。
线程的分类
线程的分类如下。
(1)用户级线程。不依赖于内核,该类线程的创建、撤销和切换都不利用系统调用实现。
(2)内核支持线程。依赖于内核,即无论是用户进程中的线程,还是系统中的线程,它们的创建、撤销和切换都利用系统调用实现。
(3)同时实现了两种类型的线程。
线程与进程的比较
下面介绍线程与进程的比较。
(1)调度。将线程作为调度和分配的基本单位,进程作为拥有资源的基本单位。
(2)并发性。不仅进程之间可并发执行,而且同一个进程中的多个线程之间也可并发执行。
(3)拥有资源。进程是拥有资源的一个独立单位,线程不拥有系统资源,但可访问隶属于进程的资源。
(4)系统开销。在创建或撤销进程时,由于系统都要为之分配和回收资源,导致系统的开销明显地大于创建或撤销线程时的开销。
现代操作系统的基本功能是管理计算机系统的硬件、软件资源,这些管理工作分为处理机管理、存储器管理、设备管理、文件管理、作业和通信事务管理。
操作系统的性能与计算机系统工作的优劣有着密切的联系。评价操作系统的性能指标一般有:
(1)系统的可靠性。
(2)系统的吞吐率(量),是指系统在单位时间内所处理的信息量,以每小时或每天所处理的各类作业的数量来度量。
(3)系统响应时间,是指用户从提交作业到得到计算结果这段时间,又称周转时间;
(4)系统资源利用率,指系统中各个部件、各种设备的使用程度。它用在给定时间内,某一设备实际使用时间所占的比例来度量。
(5)可移植性。
29. 喷泉模型是一种适合于面向(29)开发方法的软件过程模型。该过程模型的特点不包括(30)。
A. 对象
B. 数据
C. 数据流
D. 事件
在开发产品或构建系统时,遵循一系列可预测的步骤(即路线图)是非常重要的,它有助于及时交付高质量的产品。软件开发中所遵循的路线图称为"软件过程"。过程是活动的集合,活动是任务的集合。软件过程有3层含义:一个是个体含义,即指软件产品或系统在生存周期中的某一类活动的集合,如软件开发过程、软件管理过程等;二是整体含义,即指软件产品或系统在所有上述含义下的软件过程的总体;三是工程含义,即指解决软件过程的工程,应用软件的原则、方法来构造软件过程模型,并结合软件产品的具体要求进行实例化,以及在用户环境下的运作,以此进一步提高软件的生产率,降低成本。
能力成熟度模型(CMM)
CMM将软件组织的过程能力分成五个成熟度级别:初始级、可重复级、已定义级、已管理级和优化级。由低到高,软件开发生产精度越来越高,每单位工程的生产周期越来越短。
(1)初始级。软件过程是无序的,有时甚至是混乱的,对过程几乎没有定义,成功取决于个人努力。
(2)可重复级。建立了基本的项目管理过程来跟踪费用、进度和功能特性;制定了必要的过程纪律,能重复早先类似应用项目取得的成功。
(3)定义级。已将软件管理和工程两方面的过程文档化、标准化,并综合成该组织的标准软件过程。所有项目均使用经批准、剪裁的标准软件过程来开发和维护软件。
(4)管理级。收集对软件过程和产品质量的详细度量,对软件过程和产品都有定量的理解和控制。
(5)优化级。过程的量化反馈和先进的新思想、新技术促使过程不断改进。
能力成熟度模型集成(CMMI)
CMM的成功导致了适用不同学科领域的模型的衍生,如系统工程的能力成熟度模型,适用于集成化产品开发的能力成熟度模型等。而一个工程项目又往往涉及多个交叉的学科,因此有必要将各种过程改进的工作集成起来。1998年,由美国产业界、政府和卡内基.梅隆大学软件工程研究所共同主持CMMI项目。CMMI是若干过程模型的综合和改进,是支持多个工程学科和领域的、系统的、一致的过程改进框架,能适应现代工程的特点和需要,能提高过程的质量和工作效率。
CMMI提供了两种表示方法:阶段式模型和连续式模型。
1)阶段式模型
阶段式模型的结构类似于CMM,它关注组织的成熟度。CMMI-SE/SW/IPPD 1.1版中有5个成熟度等级。
初始的:过程不可预测且缺乏控制。
已管理的:过程为项目服务。
已定义的:过程为组织服务。
定量管理的:过程已度量和控制。
优化的:集中于过程改进。
2)连续式模型
连续式模型关注每个过程域的能力,一个组织对不同的过程域可以达到不同的过程域能力等级(Capability Level,CL)。CMMI中包括6个过程域能力等级,等级号为0-5。能力等级包括共性目标及相关的共性实践,这些实践在过程域内被添加到特定目标和实践中。当组织满足过程域的特定目标和共性目标时,就说该组织达到了那个过程域的能力等级。
能力等级可以独立地应用于任何单独的过程域,任何一个能力等级都必须满足比它等级低的能力等级的所有准则。对各能力等级的含义简述如下。
CLo(未完成的):过程域未执行或未得到CLi中定义的所有目标。
CLi(已执行的):其共性目标是过程将可标识的输入工作产品转换成可标识的输出工作产品,以实现支持过程域的特定目标。
CL2(已管理的):其共性目标集中于已管理的过程的制度化。根据组织级政策规定过程的运作将使用哪个过程,项目遵循已文档化的计划和过程描述,所有正在工作的人都有权使用足够的资源,所有工作任务和工作产品都被监控、控制和评审。
CL3(已定义级的):其共性目标集中于已定义的过程的制度化。过程是按照组织的剪裁指南从组织的标准过程集中剪裁得到的,还必须收集过程资产和过程的度量,并用于将来对过程的改进。
CL4(定量管理的):其共性目标集中于可定量管理的过程的制度化。使用测量和质量保证来控制和改进过程域,建立和使用关于质量和过程执行的定量目标作为管理准则。
CLs(优化的):使用量化(统计学)手段改变和优化过程域,以满足客户要求的改变和持续改进计划中的过程域的功效。
喷泉模型主要用于描述面向对象的开发过程。该模型具有迭代和无间隙特性。迭代意味着模型中的开发活动常常需要重复多次,在迭代中不断完善软件系统。无间隙是指在开发活动之间不存在明显的边界,允许开发活动交叉、迭代地进行。
30. 喷泉模型是一种适合于面向(29)开发方法的软件过程模型。该过程模型的特点不包括(30)。
A. 以用户需求为动力
B. 支持软件重用
C. 具有迭代性
D. 开发活动之间存在明显的界限
31. 若某模块内所有处理元素都在同一个数据结构上操作,则该模块的内聚类型为( )。
A. 逻辑
B. 过程
C. 通信
D. 功能
聚类是一种无监督学习过程。根据数据的特征,将相似的数据对象归为一类,不相似的数对象归到不同的类中,这就是聚类,每个聚类也称为簇。“物以类聚,人以群分”就是聚类的典型描述。
聚类的典型算法有:基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法和基于统计模型的方法。基于划分的方法将单个数据对象划分为k个不相交的集合,每个集合称为一个簇。典型的算法有k-均值、k-中心点算法等。基于层次的方法将数据对象集进行层次的分解。根据其是自底向上还是自顶向下分解,可以分为凝聚的方法和分裂的方法,而前者的典型算法是AGNES,后者的典型算法是DIANA。基于密度的方法基于数据对象的邻域来进行聚类分析,因此可以识别各种形状的簇,以及一个数据对象可以属于多个不同的簇,DBSCAN、OPTICS和DENCLUE是其中的典型算法。基于网格的方法把对象空间量化为有限个单元,形成一个网格结构。所有的聚类操作在该网格上进行,STING和CLIQUE是其中的两个算法。基于统计模型的算法将数据对象集看作多个服从不同分布的数据集构成,聚类的目的是识别出这些不同的分布的数据对象,EM算法是其中的一个典型算法。
根据数据元素之间关系的不同特性,通常有下列4类基本的逻辑结构,即集合结构、线性结构、树形结构、图形结构。
1)线性结构
线性表是最常用且最简单的一种数据结构。线性表中除第一个元素外,每个元素均只有一个直接前驱;除最后一个元素外,每个元素都只有一个直接后继。
栈是限定仅在表尾进行插入或删除操作的线性表,是只能通过访问它的一端来实现数据存储和检索的一种线性数据结构。
队列是一种先进先出(FIFO)的线性表,它只允许在表的一端进行插入,而在另一端删除元素。
2)树
树是n(n≥0)个互不相交的有限集,当n=0时称为空树。在一棵非空树中,有且仅有一个节点称为根节点;当n>1时,其余的节点可分为若干个不相交的集合,其中每一个集合本身又是一棵树,这些集合称为根节点的子树。
3)图
图是由两个集合V和E组成的二元组,记为G=(V, E),其中V是顶点的非空有限集合,E是图中边的有限集合。
32. 软件质量属性中,( )是指软件每分钟可以处理多少个请求。
A. 响应时间
B. 吞吐量
C. 负载
D. 容量
33. 提高程序执行效率的方法一般不包括( )。
A. 设计更好的算法
B. 采用不同的数据结构
C. 采用不同的程序设计语言
D. 改写代码使其更紧凑
34. 软件可靠性是指系统在给定的时间间隔内、在给定条件下无失效运行的概率。若MTTF和MTTR分别表示平均无故障时间和平均修复时间,则公式( )可用于计算软件可靠性。
A. MTTF/(1+MTTF)
B. 1/(1+MTTF)
C. MTTR/(1+MTTR)
D. 1/(1+MTTR)
可靠性是指在指定条件下使用时,软件产品维持规定的性能级别的能力。
.成熟性:指软件产品为避免由软件内部的故障而导致失效的能力。
.容错性:指在软件出现故障或者违反其指定接口的情况下,软件产品维持规定的性能级别的能力。
.易恢复性:指在失效发生的情况下,软件产品重建规定的性能级别并恢复受直接影响的数据的能力指。
.可靠性的依从性:指软件产品遵循与可靠性相关的标准、约定或法规的能力。
可靠度为R(t)的系统的平均无故障时间(Mean Time To Failure,MTTF)定义为从t=0时到故障发生时系统的持续运行时间的期望值,计算公式如下:
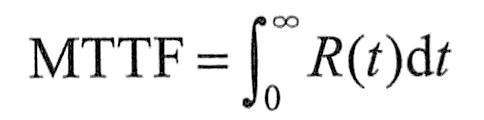
如果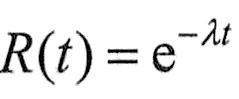
例如,假设同一型号的1000台计算机,在规定的条件下工作1000小时,其中有10台出现故障。这种计算机千小时的可靠度R为(1000-10)/1000=0.99。失效率为10/(1000×1000=1×10-5)。因为平均无故障时间与失效率的关系为MTTF=1/λ,因此,MTTF=105小时。
35. 用白盒测试技术对下面流程图进行测试,设计的测试用例如下表所示。至少采用测试用例(35)才可以实现语句覆盖;至少采用测试用例(36)才可以实现路径覆盖。

A. ①
B. ②
C. ③
D. ④
白盒测试也称为结构测试,根据程序的内部结构和逻辑来设计测试用例,对程序的路径和过程进行测试,检查是否满足设计的需要。
测试工作伴随着整个网络工程的全过程,无论是布线安装还是系统调试,都需要进行反复的测试和确定。
测试计划
测试计划应包括下列5个方面的内容。
1)简要说明
简要说明包括工程的概况和需要达到的主要指标。
2)测试内容
测试内容包括逐项列出的测试步骤、名称、内容和预期达到的目标。
3)测试清单
测试清单是对每项测试内容列出测试的部位和参与测试的单位,包括进度的安排、测试工具和相应的条件(设备和软件等)。
4)测试设计说明
测试设计说明是对每项测试内容的测试设计进行考虑,包括测试的控制方式、输入条件和预期的输出结果。
5)评价准则
评价准则用来说明测试所能检查的范围及其局限性,以及用来判断测试工作是否通过的评价尺度,包括合理的输出结果、测试输出结果与预期输出结果之间容许出现的偏差范围。
测试工作完成后,应提交一份测试分析报告。该报告主要包括下列内容:概要说明、测试结果、结论、原因分析、建议和评价。
网络测试
网络测试是对网络设备、网络系统以及网络对应用的支持进行检测,以展示和证明网络系统能否满足用户在性能、安全性、易用性、可管理性等方面需求的测试。网络测试的实施一般包括以下环节。
◆根据测试目的,确定测试目标。
◆在对相关网络技术和实现细节透彻掌握的基础上,设计测试方案。
◆建立网络负载模型。
◆配置测试环境,包括测试工具的选择及必要的测试工具的研发。
◆采集和整理数据。
◆分析和解释数据。
◆准确、直观、形象地表示测试结果。
网络测试包括网络设备测试、网络系统测试和网络应用测试3个层次。
1)网络设备测试
网络设备测试主要包括以下几个方面:功能测试、可靠性和稳定性测试、一致性测试、互操作性测试和性能测试等。
(1)功能测试用来验证产品是否具有设计的每一项功能。
(2)可靠性和稳定性测试往往通过加重负载的办法来分析和评估系统的可靠性和稳定性。
(3)一致性测试用来验证产品的各项功能是否符合标准。
(4)互操作性测试用来考查一个网络产品是否能在不同厂家的多种网络产品互联的网络环境中很好地工作。网络产品不同于其他产品的最大特点是必须符合标准,不同的网络产品之间要能互操作。
(5)性能测试的主要目标是分析产品在各种不同的配置和负载条件下的容量和对负载的处理能力,如交换机的吞吐量、转发延迟等。
典型的网络设备性能测试方法有两种:第一种是将设备放在一个仿真的网络环境中进行测试,第二种是使用专用的网络测试设备对产品进行测试。
2)网络系统测试和网络应用测试
网络系统测试除了普通意义上的物理连通性、基本功能和一致性的测试以外,主要包括网络系统的规划验证测试、网络系统的性能测试、网络系统的可靠性与可用性的测试与评估、网络流量的测量和模型化等。
(1)网络系统的规划验证测试主要采用的两个基本手段是模拟和仿真。
◆模拟是通过软件的办法,建立网络系统的模型,模拟实际网络的运行。通过设定各种配置和参数模拟系统的行为,对系统的容量、性能以及对应用的支撑程度给出定量的评价。这对于大型网络的规划设计是不可缺少的环节。
◆仿真是指通过建立典型的试验环境,仿真实际的网络系统。规划验证测试的目的在于分析所采用的网络技术的可行性和合理性,网络设计方案的合理性,所选网络设备的功能、性能等是否能够合理地、有效地支持网络系统的设计目标。
(2)网络系统的性能测试是指通过对网络系统的被动测量和主动测量来确定系统中站点的可达性、网络系统的吞吐量、传输速率、带宽利用率、丢包率、服务器和网络设备的响应时间、产生最大网络流量的应用和用户,以及服务质量等。此项工作同时可以发现系统的物理连接和系统配置中的问题,确定网络瓶颈,发现网络问题。测试设备记录一段时间内的网络流量,实时和非实时地分析数据。被动测量不干涉网络的正常工作,不影响网络的性能。主动测量向网络发送特定类型的数据包或网络应用,以便分析系统的行为。
(3)网络系统的可靠性与可用性的测试与评估。系统可用性取决于系统的可靠性(MTTF)及可维护性(MTTR)的高低,其中可靠性是指系统服务多久不中断,可维护性是指服务中断后多久可恢复。三者之间满足如下关系:
System Usability=MTTF/(MTTF+MTTR)*100%
其中,MTTF是指平均无故障时间,MTTR是指平均故障修复时间,MTBF是指平均故障间隔时间。有MTBF=MTTF+MTTR,故
System Usability=MTTF/MTBR*100%
(4)网络流量的测量和模型化。网络流量的测量和模型化对于分析网络性能和带宽的利用率、指导网络流量管理、开发高效的网络应用十分重要。这方面的工作主要有以下几个方面。
◆产生已知特征的流量,使该流量沿网络传播,最后回到测试仪。记录和分析流量特性的任何改变(如延迟漂移)。
◆对链路总体流量的测量和传输时间、吞吐量、带宽利用率等进行分析。
◆分析特定流量的特征和提供的QoS;收集一个时间段内的测量数据进行分析,分析流量沿网络传播过程中流量特征的变化和网络流量的统计行为,建立流量模型。
(5)网络应用层次上的测试则主要体现在测试网络对应用的支持水平,如网络应用的性能和服务质量的测试等。例如,部署基于IP的语音传输VoIP时,最直接的问题是网络中的交换机和路由器设备能否有效地支持语音传输,网络能支持多大的语音流量、多少个语音通道;如果网络支持VoIP,对网络的其他业务特别是关键业务,会产生什么样的影响;网络是否支持服务质量QoS。这些问题都需要通过网络应用测试来回答。
(6)网络系统测试的核心工具是协议分析仪。这是一种专用的网络测试设备,它能够连接到网络上,产生并向网络发送数据,捕捉网络数据,分析数据。协议分析仪一般具有网络监测、故障查找、协议解码和流量产生等功能。
网络设备安全性测试
现在有很多新型网络设备尤其是网络边缘路由器增加了防护功能,阻止了人为、故意的网络攻击。然而,提供的防护会不会对正常数据转发造成影响?有什么样的影响?这些很难从理论上估计,需要进行必要的网络设备安全性测试。
本节提到的测试项,主要是验证网络设备所提供的基本安全功能,并检测这些安全功能项对网络设备运行造成的影响。这些测试项分为访问列表测试和DOS攻击测试两大类。
1)访问列表测试
访问列表测试用于检测边缘路由器的访问列表能否起到防火墙的作用,访问列表测试控制网络传输过滤数据报文,访问列表测试阻止或允许数据报文通过网络接口。过滤依据可以是源地址、目的地址和上层协议号。边缘路由器通过将进入或离开的数据报文与访问列表中的过滤项进行比较,决定允许或阻止数据报文通过。对于边缘路由器能提供的访问列表容量,以及不断变化的访问列表对数据转发的影响都要进行测试。
2)DOS攻击测试
DOS攻击测试用于检测边缘路由设备抵抗"拒绝服务(DOS)攻击"的能力。当设备由于伪造的服务请求和虚假的传输而变得非常繁忙时,就无法响应正常的服务请求,从而造成损失。DOS攻击测试考验网络设备检测并阻止某种特定攻击的能力,并在检测受到某种攻击、设备超负荷运行的情况下,正常传输转发性能所受的影响。
具体的网络设备安全性测试项目如下。
◆访问列表性能测试。
◆虚假源地址攻击测试。
◆LAND攻击检查。
◆SYN风暴检查。
◆Smurf攻击检查。
◆Ping风暴检查。
◆Teardrop攻击检查。
◆Ping to Death检查。
性能测试
性能测试包括可靠性测试、功能/特性测试、吞吐量测试、衰减测试、容量规划测试、响应时间测试、可接受性测试和网络瓶颈测试等。
1)可靠性测试
可靠性测试是使被测网络在较长时间内(通常是24~72小时)经受较大负载,通过监视网络中发生的错误和出现的故障,验证在高强度环境中网络系统的存活能力,也就是它的可靠性。可靠性测试可作为接受性测试的一部分,在产品评估测试中可作为比较测试或作为产品升级进行的衰减测试的一部分。采用的负载模式很重要,越贴近真实负载模式越好。可靠性测试中使用网络分析仪监控网络运行,捕获网络错误。
通常在较长时间段内和持续负载下,不同网络具有不同级别的存活度。如果测试时间足够长、负载足够大,所有可靠性测试最终都会失败。
可靠性测试应用于网络生命周期中的以下3个阶段。
◆计划:作为产品评估测试的一部分,比较不同产品或建立要求规范。
◆开发:验证计划中的要求是否能在系统中完全实现。
◆组建:作为可接受性测试的一部分,在网络运行前进行,核实系统是否达到要求。
2)功能/特性测试
特性测试核实的是单个命令和应用程序功能,通常用较小的负载完成,关注的是用户界面、应用程序的操作以及用户与计算机之间的互操作。特性测试通常由开发人员在他们的工作台上完成,或是在一个小型网络环境下由测试人员完成。
功能测试是面向网络的,核实的是应用程序的多用户特征和在重负载下后台功能是否能正确地执行,关注的是当多个用户正在运行应用程序时,网络和文件系统或数据库服务器之间的交互。功能测试要求网络的配置和负载非常接近于运行环境下的模式。该测试可以在运行网络或独立网络实验室里完成。它只应用于网络生命周期中的以下3个阶段。
◆开发:用于核实在期望的运行模式下,在多用户环境里,应用程序的运行性能是否达到要求。
◆组建:在应用程序安装前完成,可独立进行,也可作为接受性测试的一部分,用于核实在期望的运行模式下,应用程序的运行性能是否达到要求。
◆运行:该阶段测试是在应用程序运行后进行的,如果在运行系统中遇到了问题,该阶段测试用于核实应用程序是否如最初应用时那样工作。
3)吞吐量测试
吞吐量测试和应用程序的响应时间测试相似,但检测的是每秒钟传输数据的字节数和数据报文数,而不是响应时间。它用于检测服务器、磁盘子系统、适配卡/驱动连接、网桥、路由器、集线器、交换器和通信连接。吞吐量测试用于测量网络性能、找到网络瓶颈,以及比较不同产品的性能。
吞吐量测试不使用程序脚本,它借助某些软件对网络服务器执行文件输入/输出操作来产生流量,或通过某些软件在网络上发送专门的数据报文或帧。该测试应用于网络生命周期的以下几个阶段。
◆计划:用于比较网络产品,为模拟网络节点提供运行特征和要求规范。
◆开发:用于核实网络组件以及整个网络是否达到规范要求的水平。
◆组建:可独立进行或作为可接受性测试的一部分,在网络组件或整个网络正式运行之前核实它们是否满足规范的要求。
4)衰减测试
衰减测试是将硬件或软件的新版本与当前版本在性能、可靠性和功能等方面进行比较,同时验证产品升级对网络的性能不会有不良影响。衰减测试混杂了很多为完成其他测试任务要进行的测试。衰减测试的关键是要保证被测组件应是运行网络中最关键或最脆弱的组件。
衰减测试不强调升级版的新特性。新特性测试在衰减测试之前作为功能/特征测试的一部分就已完成。尽管新产品应该解决了当前版本中的错误,但它们也经常存在一些以前没有出现过的错误,如果这些错误发生在产品的关键部分,将会引起严重问题。衰减测试不需要测试产品的所有特性,但网络用户正常运行所依靠的关键功能必须在测试之列。
衰减测试应用于网络生命周期的以下两个阶段。
◆开发:用于核实产品升级版是否能满足性能、互操作性和可靠性的要求。
◆升级:在采用升级版本之前用该项测试来比较升级版和当前版,看升级版是否和当前版一样满足性能、互操作性和可靠性的要求。
5)容量规划测试
容量规划测试用于检测当前网络中是否存在多余的容量空间。当网络承受的总负载超过网络总容量时,网络的性能或吞吐量就有可能下降,所以在网络负载接近这一临界点(网络的最大容量)前,就要根据负载增长的幅度扩充网络资源。
进行该项测试要逐渐增加网络负载,直到网络的运行性能、可接受的水平或吞吐量不断下降,达不到设计所要求的水平为止。网络运行负载和网络最大吞吐量之间的差额就是现有系统的冗余量。
容量规划测试应用于网络生命周期的以下3个阶段。
◆计划:用于估计实施该系统所需要的资源,也可用于成本分析和制定预算。
◆开发:检测系统要求的资源是否满足特定的响应时间和吞吐量的要求。
◆升级:当系统响应时间或吞吐量下降时,重新选取网络组件。
6)响应时间测试
响应时间测试用于检测系统完成一系列任务所需的时间,本项测试是用户最关心的。对于表示层,如微软的Windows,该测试是指在不同桌面之间切换或装载新负载所需的时间。在不同负载即不同实际或模拟用户的数目下运行这一实验,可对每个被测试的应用程序生成一个负载—响应时间曲线。
在应用程序测试中,可执行一系列典型网络动作的命令,如打开、读、写、查找和关闭文件,这些命令提供了最好的负载模拟。例如,对每个进行测试的工作站,检测它在几秒内能完成这些命令。
响应时间测试应用于网络生命周期的以下几个阶段。
◆计划:使用模拟应用程序进行,检测规范要求的各项网络服务。
◆开发:检验规范要求的网络服务是否正在被实现。
◆组建:在接受和组建之前,核实规范要求下的网络服务是否已经被实现。
◆运行:检测网络服务的基准和变化,这可能是针对系统质量的最好测试。
响应时间测试应该包括对系统可靠性的检测。常见的可靠性问题,如在路由器或服务器中大量丢失数据报文或由于网络组件故障引发大量坏数据报文,将严重影响网络的响应时间,因此在整个测试期间都应用网络分析仪监视系统错误。
7)可接受性测试
可接受性测试是在系统正式实施前的"试运行"。它是一个非常有效的方法,可确保新系统能提供良好而稳定的性能。和衰减测试一样,可接受性测试中也包含多项测试,如响应时间测试、稳定性测试和功能/特性测试。
可接受性测试应用于许多领域,但在安装或升级网络前应进行的网络可接受性测试则经常被忽略,而事实上,可接受性测试能为网络购买者在经济和技术上提供有力的保证和参考。
可接受性测试可以仅在新增加的部件上完成,将已存在的负载加上新增程序或新增组件可能产生的负载作为测试使用的负载。
可接受性测试应用于网络生命周期的以下两个阶段。
◆开发:在开发阶段前定期执行,用来核实要求的标准是否可行。
◆组建:在网络投入运行之前应用,用来核实系统是否满足所有要求。
8)网络瓶颈测试
通过网络瓶颈测试可以找到导致系统性能下降的瓶颈。测试中需要测试和计算系统的最大吞吐量,然后再在单个网络组件上进行该项测试,明确各组件的最大吞吐量。通过计算单个组件的最大吞吐量和系统最大吞吐量之间的差额,就能发现系统瓶颈的位置以及哪些组件有多余的容量。
系统瓶颈在不同的测试案例中出现的位置可能有所变化。例如,一个客户业务应用程序测试可能表明服务器是系统的瓶颈,而对一个电子邮件系统的测试则可能表明广域网连接才是网络的限制因素。如果可以在测试的环境中重现引起问题的负载,那么这样的测试结果对解决问题将有很大帮助。
瓶颈测试应用于网络生命周期的以下两个阶段。
◆组建:可以作为容量计划的一部分,用于帮助相关人员明确影响网络性能和响应时间的瓶颈位置。
◆运行:作为故障检测的一部分,帮助相关人员找出影响网络性能或引起系统问题的网络瓶颈。
测试报告
测试报告是整个项目的第一份供大家交流和供领导查阅的报告,人们对工程的满意程度和对工程质量的认可很大程度上来源于这份报告。通常在独立网络测试后,要总结测试数据,并基于此对测试过的同类产品进行排序;而系统内部的测试仅是得出一个简单的结论。
测试报告呈现的内容和采取的表现形式非常重要,测试报告通常包含以下信息。
◆测试目的:用一句或两句话解释本次测试的目的。
◆结论:从测试中得到的信息推荐下一步的行动。
◆测试结果总结:对测试进行总结并由此得出结论。
◆测试内容和方法:简单地描述测试是怎样进行的,应该包括负载模式、测试脚本和数据收集方法,并且要解释采取的测试方法怎样保证测试结果和测试目的的相关性,以及测试结果是否可重现。
◆测试配置:网络测试配置用图形表示出来。
测试报告的形式可以是一个简短的总结(2~4页),也可以是一个很长的书面文档(5~20页)。测试总结可以使用图形表示测试结果,如应用程序的响应时间、吞吐量和产品评估。而系统衰减性测试、配置规模测试和应用程序的功能/特性测试的测试报告还要包括更多的信息。
在非常特殊的情况下,测试报告需要长达50页。它通常包括从项目开始到结束按时间编排的所有活动,以及非常详细的问题信息和解决问题的信息。
网络测试工具
网络测试工具一般包括以下几个。
◆网络管理和监控工具。
◆建模和仿真工具。
◆服务质量和服务级别管理工具。
网络管理和监控工具(如HP公司的OpenView)能够在网络测试运行过程中提示某些问题的网络事件的出现。这些工具可以是驻留在网络设备中的应用软件。
协议分析仪也能被用于监测新设计的网络,帮助分析通信的行为、差错、利用率、效率以及广播和多播分组。
建模工具和仿真工具是更为先进的用来测试验证网络设计的工具。仿真就是在不建立实际网络的情况下,使用软件和数学模型来分析网络行为的过程。利用仿真工具,可以根据所需要测试的目标开发一个网络模型,从而估计网络性能,并对各种网络实现方法之间的差异进行比较。仿真工具使得选择比较的空间变得更大,特别适合于实现和检查一个扩展的原型系统。一个好的仿真工具往往非常昂贵,实现的技术也比较复杂,它要求开发人员不但要精通统计分析和建模技术,而且还要对计算机网络有所了解。
服务级别管理工具是一种比较新型的工具,主要用来分析网络应用的端到端性能。有些工具能够管理服务质量和服务级别,有些工具能够监控实时应用的性能,有些工具能够预测新的应用性能,有些工具可以将上述功能结合起来实现更强大的功能。
36. 用白盒测试技术对下面流程图进行测试,设计的测试用例如下表所示。至少采用测试用例(35)才可以实现语句覆盖;至少采用测试用例(36)才可以实现路径覆盖。
A. ①
B. ①②
C. ③④
D. ①②③④
37. 面向对象程序设计语言C++、JAVA中,关键字( )可以用于区分同名的对象属性和局部变量名。
A. private
B. protected
C. public
D. this
Smalltalk
Smalltalk并不是一种单纯的程序设计语言,而是反映面向对象程序设计思想的程序设计环境。这个系统在其本身的设计中强调了对象概念的归一性,引入了类、方法、实例等概念和术语,应用了单重继承和动态绑定,成为OOPLs发展过程中的一个引人注目的里程碑。
在Smalltalk-80中,除了对象之外没有其他形式的数据,对一个对象的唯一操作就是向它发消息。在这种语言中,连类也被看成是对象——类是元类的实例。因此,定义一个类就是向元类发一条消息,请求元类执行它的new来生成一个实例,也就是生成这个类,而消息中的参数就是关于这个类的说明。Smalltalk全面支持面向对象的概念。
Eiffel
Eiffel的主要特点是全面的静态类型化、有大量的开发工具、支持多继承。Eiffel也全面支持面向对象的概念。
C++
C++语言是一种面向对象的强类型语言,由AT&T的Bell实验室于1980年推出。
C++语言是C语言的一个向上兼容的扩充,而不是一种新语言。C++是一种支持多范型的程序设计语言,它既支持面向对象的程序设计,也支持面向过程的程序设计。
C++支持基本的面向对象概念,包括对象、类、方法、消息、子类和继承。C++完全支持多继承,并且通过使用try/throw/catch模式提供了一个完整的异常处理机制。它同时支持静态类型和动态类型,也完全支持多继承,不提供自动的无用存储单元收集,这必须通过程序员来实现,或者通过编程环境提供合适的代码库来予以支持。
Java
Java语言起源于Oak语言,Oak语言被设计成能运行在设备的嵌入式芯片上。
Java编译成伪代码,这需要一个虚拟机来对其进行解释,Java的虚拟机在几乎每一种平台上都可以运行。这实质上使得开发是与机器独立无关的,并且提供了通用的可移植性。
Java把类的概念和接口的概念区分开来,并试图通过只允许接口的多继承来克服多继承的危险。
Java的异常处理机制与C++的try/throw/catch相类似,但更加严密。在Java中,通过声明轻型线程来处理并发性,这些线程通过副作用和同步协议进行通信。
Java Beans是组件,即类及其所需资源的集合,它们主要被设计用来提供定制的GUI小配件。
Java中关于面向对象概念的术语有对象、类、方法、实例变量、消息、子类和继承。
C++语言是一种面向对象的强类型语言,由AT&T的Bell实验室于1980年推出。
C++语言是C语言的一个向上兼容的扩充,而不是一种新语言。C++是一种支持多范型的程序设计语言,它既支持面向对象的程序设计,也支持面向过程的程序设计。
C++支持基本的面向对象概念,包括对象、类、方法、消息、子类和继承。C++完全支持多继承,并且通过使用try/throw/catch模式提供了一个完整的异常处理机制。它同时支持静态类型和动态类型,也完全支持多继承,不提供自动的无用存储单元收集,这必须通过程序员来实现,或者通过编程环境提供合适的代码库来予以支持。
类和继承
1)类
一个类是一些属性和方法的封装体,类的定义用关键字class声明,用关键字public、protected、 private指定类的成员的存取控制属性:private(私有)成员只有类内部的方法才能访问,protected(保护)成员派生类和同一文件夹下的类可以访问,public(公有)成员可以从类的外部访问。默认是public。这体现了面向对象的以下指导思想:尽量将类内部的细节隐藏起来,对类的属性的操作应该通过类的方法来进行。
另外,public还可以用来修饰类,public类能够被其他文件夹下的类访问,非public类只能被同一文件夹下的类访问。一个.java文件中可以包含多个类,会被编译成多个.class文件,但只能有一个public类,而且该类名要和文件名一样。
2)继承
Java中用关键字extends表示类间的继承关系。父类的公有属性和方法成为子类的属性和方法,子类如果有和父类的同名、同参数类型的方法,那么子类对象在调用该方法时,调用的是子类的方法,亦即方法的重置。如果想要调用父类的同名方法,需要用super关键字(属性同理)。
子类的对象可以作为祖先类的对象使用,即所谓类的向上转换,反之则不行。具体表现在:可以用子类对象来对祖先类对象赋值,可以用子类对象作为实参去调用以父类对象为形参的函数。
对象的引用本质
Java中的对象实际上是对象的引用,本质上和C语言中的指针是一样的;但也和C语言指针不尽相同,例如,不能自增、自减,不能强制转换成其他类型。
例如:

构造方法
构造方法就是类的对象生成时会被调用的方法。每个类至少有一个构造方法(Constructor),也称构造函数。构造方法的名字和类名相同,没有任何返回类型。每个类都有一个默认的构造方法,但当用户自定义了构造方法后,默认的构造函数就不再有效了。
重载
同一个类中的两个或两个以上方法,名字相同,而参数个数不同或参数类型不同,称为重载。注意:不能有各方法名字和参数都一样,而仅仅返回值类型不同。
静态属性和静态方法
静态属性和静态方法的声明用关键字static实现,一个类的静态属性只有一份,由所有该类的对象共享。不需要创建对象也能访问类的静态属性和方法,访问方式为"类名.静态属性或静态方法",静态方法与对象无关,因此不能在静态方法中访问非静态属性和调用非静态方法。
this和super关键字
这两个关键字颇为重要。this代表当前对象,super代表当前对象的父类的东西。
this主要用途有以下两个。
(1)一个构造函数调用另一个构造函数,对构造函数的调用必须是第一条语句。
(2)将对象自身作为参数来调用一个函数。
super的用途如下:在子类中调用父类的同名方法,或在子类的构造函数中调用父类的构造函数,此时亦必须是第一条语句。
多态
所谓多态,是指通过基类对象调用一个基类和派生类都有的方法时,在运行时才能确定到底调用的是基类的方法还是派生类的方法。多态的好处是增加了程序的可扩展性。多态是通过动态联编实现的,即编译时不确定,程序运行时才确定调用哪个函数。
抽象类与接口
1)抽象类
抽象类通过关键字abstract实现,抽象类的目的是定义一个框架,规定某些类必须具有的一些共性。
包含抽象方法的类一定是抽象类,所谓抽象方法是指没有函数体的方法。
抽象类的直接派生类必须实现其抽象方法;抽象类只能用于继承,不能创建对象。
2)接口(Interface)
接口用关键字interface声明,只能用于继承。注意:此时关键字为implements(实现)。接口用于替代多继承的概念,能实现多继承的部分特点,又避免了多继承的混乱,还能起到规定程序框架的作用。注意:接口也可以用于多态。
直接继承了接口的类,必须实现接口中的抽象方法;间接的则可以实现,也可以不实现。
3)抽象类与接口的异同
接口和抽象类都不能创建对象。
抽象类不能参与多继承,抽象类可以有非静态的成员变量,可以有非抽象方法;接口可以参与多继承,所有属性都是静态常量,所有方法都是public抽象方法。
异常处理
1)异常概念
异常,即出错,比如0作为除数、找不到类、打开文件错误、数组越界等。异常如果不进行处理,那么程序运行就会结束;如果进行处理,那么会在执行完异常处理代码后继续运行。
Java中所有异常类均继承自类Exception。
Java中的异常类层次结构如下:

此外,还有EOFException、 FileNotFoundException、 MalformedURLException等。
2)捕获异常
异常处理的典型用法如下,将可能出现异常的代码放在try块中,其后由一个或多个catch捕获相应异常进行处理,注意只执行第一个匹配的catch块,忽略后面的。

如果某个方法中所产生的异常该方法自己没有处理,那么可以在调用该方法的方法中进行处理,如果自己处理了,那么调用它的方法就无法得到该异常。
3)抛出异常
异常除了运行中系统产生的之外,也可以主动抛出异常,用关键字throw,如throw new Exception()。注意:throw只能抛出Throwable子类的异常。
4)带throws关键字的方法
带throws关键字的方法声明如下:

强制调用该方法的方法必须处理可能发生的异常,或者将异常重新定向。假定方法A带throws关键字,而方法B中调用了方法A,则方法B中必须有处理方法A中可能产生的异常的语句,或者方法B也带throws关键字,指明调用方法B的方法必须处理异常。
final关键字
用final关键字定义的常量,在其初始化或第一次赋值后,其值不能被改变。常量必须先有值,然后才能使用。对于常量的第一次赋值只能在构造函数中进行。
final对象的值不能被改变,指的是该对象不能再指向其他对象,而不是指不能改变当前对象内部的属性值。
函数参数声明为final后,函数中不能改变其值。
final方法是不能被重置的方法。
final类不能被继承,其所有方法都是final的,但属性可以不是final的。
在计算机系统中,对象是指一组属性及这组属性上的专用操作的封装体。属性可以是一些数据,也可以是另一个对象。每个对象都有它自己的属性值,表示该对象的状态,用户只能看见对象封装界面上的信息,对象的内部实现对用户是隐蔽的。封装的目的是使对象的使用者和生产者分离,使对象的定义和实现分开。一个对象通常可由三部分组成,分别是对象名、属性和操作(方法)。
程序设计语言(Programming Language)是用于编写计算机程序的语言。语言的基础是一组记号和一组规则,根据规则由记号构成的记号串的总体就是语言。在程序设计语言中,这些记号串就是程序。程序设计语言包含三个方面,即语法、语义和语用。语法表示程序的结构或形式,即表示构成程序的各个记号之间的组合规则,但不涉及这些记号的特定含义,也不涉及使用者。语义表示程序的含义,即表示按照各种方法所表示的各个记号的特定含义,但也不涉及使用者。语用表示程序与使用的关系。
程序设计语言的基本成分有:数据成分,用于描述程序所涉及的数据;运算成分,用以描述程序中所包含的运算;控制成分,用以描述程序中所包含的控制;传输成分,用以表达程序中数据的传输。
程序设计语言按照语言级别可以分为低级语言和高级语言。低级语言有机器语言和汇编语言。低级语言与特定的机器有关、功效高,但使用复杂、繁琐、费时、易出差错。机器语言是表示成数码形式的机器基本指令集,或者是操作码经过符号化的基本指令集。汇编语言是机器语言中地址部分符号化的结果,或进一步包括宏构造。高级语言的表示方法要比低级语言更接近于待解问题的表示方法,其特点是在一定程度上与具体机器无关,易学、易用、易维护。常见的有Java、C、C++、PHP、Python和Delphi等。这类语言与人们使用的自然语言比较接近,大大提高了程序设计的效率。
38. 采用面向对象方法进行系统开发时,以下与新型冠状病毒有关的对象中,存在“一般-特殊’关系的是( )。
A. 确诊病人和治愈病人
B. 确诊病人和疑似病人
C. 医生和病人
D. 发热病人和确诊病人
在计算机系统中,对象是指一组属性及这组属性上的专用操作的封装体。属性可以是一些数据,也可以是另一个对象。每个对象都有它自己的属性值,表示该对象的状态,用户只能看见对象封装界面上的信息,对象的内部实现对用户是隐蔽的。封装的目的是使对象的使用者和生产者分离,使对象的定义和实现分开。一个对象通常可由三部分组成,分别是对象名、属性和操作(方法)。
面向对象方法是当前的主流开发方法,拥有大量不同的方法,主要包括OMT(Object Model Technology,对象建模技术)方法、Coad/Yourdon方法、OOSE(Object-Oriented Software Engineering,面向对象的软件工程)及Booch方法等,而OMT、OOSE及Booch最后可统一成为UML(United Model Language,统一建模语言)。
Coad/Yourdon方法
Coad/Yourdon方法主要由面向对象的分析(Object-Oriented Analysis,OOA)和面向对象的设计(Object-Oriented Design,OOD)构成,特别强调OOA和OOD采用完全一致的概念和表示法,使分析和设计之间不需要表示法的转换。该方法的特点是表示简炼、易学,对于对象、结构、服务的认定较系统、完整,可操作性强。
在Coda/Yourdon方法中,OOA的任务主要是建立问题域的分析模型。分析过程和构造OOA概念模型的顺序由5个层次组成,分别是类与对象层、属性层、服务层、结构层和主题层,它们表示分析的不同侧面。OOA需要经过5个步骤来完成整个分析工作,即标识对象类、标识结构与关联(包括继承、聚合、组合及实例化等)、划分主题、定义属性和定义服务。
OOD中将继续贯穿OOA中的5个层次和5个活动,它由4个部分组成,分别是人机交互部件、问题域部件、任务管理部件和数据管理部件,其主要的活动就是这4个部件的设计工作。
Booch方法
Booch认为软件开发是一个螺旋上升的过程,每个周期包括4个步骤,分别是标识类和对象、确定类和对象的含义、标识关系、说明每个类的接口和实现。Booch方法的开发模型包括静态模型和动态模型,静态模型分为逻辑模型(类图、对象图)和物理模型(模块图、进程图),描述了系统的构成和结构。动态模型包括状态图和时序图。该方法对每一步都做了详细的描述,描述手段丰富而灵活。
Booch不仅建立了开发方法,还提出了设计人员的技术要求,以及不同开发阶段的人力资源配置。Booch方法的基本模型包括类图与对象图,主张在分析和设计中既使用类图,也使用对象图。
OMT方法
OMT作为一种软件工程方法学,支持整个软件生存周期,覆盖了问题构成分析、设计和实现等阶段。OMT方法使用了建模的思想,讨论如何建立一个实际的应用模型。从3个不同而又相关的角度建立了三类模型,分别是对象模型、动态模型和函数模型,OMT为每一个模型提供了图形表示。
(1)对象模型。描述系统中对象的静态结构、对象之间的关系、属性和操作。它表示静态的、结构上的、系统的“数据”特征。主要用对象图来实现对象模型。
(2)动态模型。描述与时间和操作顺序有关的系统特征,如激发事件、事件序列、确定事件先后关系的状态。它表示瞬时、行为上的和系统的“控制”特征。主要用状态图来实现动态模型。
(3)功能模型。描述与值的变换有关的系统特征,包括功能、映射、约束和函数依赖。主要用数据流图来实现功能模型。
在进行OMT建模时,通常包括4个活动,分别是分析、系统设计、对象设计和实现。
(1)分析:建立可理解的现实世界模型。通常从问题陈述入手,通过与客户的不断交互及对现实世界背景知识的了解,对能够反映系统的3个本质特征(对象类及它们之间的关系,动态的控制流,受约束的数据的函数变换)进行分析,构造出现实世界的模型。
(2)系统设计:确定整个系统的架构,形成求解问题和建立解答的高层策略。
(3)对象设计:在分析的基础上,建立基于分析模型的设计模型,并考虑实现细节。其焦点是实现每个类的数据结构及所需的算法。
(4)实现:将对象设计阶段开发的对象类及其关系转换为程序设计语言、数据库或硬件的实现。
OOSE
OOSE在OMT的基础上,对功能模型进行了补充,提出了用例(use case)的概念,最终取代了数据流图来进行需求分析和建立功能模型。
OOSE方法采用5类模型来建立目标系统:
(1)需求模型:获取用户的需求,识别对象。主要的描述手段有用例图、问题域对象模型及用户界面。
(2)分析模型:定义系统的基本结构。将分析模型中的对象分别识别到分析模型中的实体对象、界面对象和控制对象三类对象中。每类对象都有自己的任务、目标并模拟系统的某个方面。实体对象模拟那些在系统中需要长期保存并加以处理的信息。实体对象由使用事件确定,通常与现实生活中的一些概念相符合。界面对象的任务是提供用户与系统之间的双向通信,在使用事件中所指定的所有功能都直接依赖于系统环境,它们都放在界面对象中。控制对象的典型作用是将另外一些对象组合形成一个事件。
(3)设计模型:分析模型只注重系统的逻辑构造,而设计模型需要考虑具体的运行环境,即将在分析模型中的对象定义为模块。
(4)实现模型:用面向对象的语言来实现。
(5)测试模型:测试的重要依据是需求模型和分析模型,测试的方法与8.8节所介绍的方法类似,而底层是对类(对象)的测试。测试模型实际上是一个测试报告。
OOSE的开发活动主要分为三类,分别是分析、构造和测试。其中分析过程分为需求分析和健壮性分析两个子过程,分析活动分别产生需求模型和分析模型。构造活动包括设计和实现两个子过程,分别产生设计模型和实现模型。测试过程包括单元测试、集成测试和系统测试3个过程,共同产生测试模型。
用例是OOSE中的重要概念,在开发各种模型时,它是贯穿OOSE活动的核心,描述了系统的需求及功能。用例实际上是描述系统用户(使用者、执行者)对于系统的使用情况,是从使用者的角度来确定系统的功能。因此,首先必须分析确定系统的使用者,然后进一步考虑使用者的主要任务、使用的方式、识别所使用的事件,即用例。
39. 进行面向对象系统设计时,针对包中的所有类对于同一类性质的变化;一个变化若对一个包产生影响,则将对该包中的所有类产生影响,而对于其他的包不造成任何影响。这属于( )设计原则。
A. 共同重用
B. 开放-封闭
C. 接口分离
D. 共同封闭
防火墙的设计原则如下。
(1)由内到外、由外到内的业务流均要经过防火墙。
(2)只允许本地安全策略认可的业务流通过防火墙,实行默认拒绝原则。
(3)严格限制外部网络的用户进入内部网络。
(4)具有透明性,方便内部网络用户,保证正常的信息通过。
(5)具有抗穿透攻击能力,强化记录、审计和报警。
在计算机系统中,对象是指一组属性及这组属性上的专用操作的封装体。属性可以是一些数据,也可以是另一个对象。每个对象都有它自己的属性值,表示该对象的状态,用户只能看见对象封装界面上的信息,对象的内部实现对用户是隐蔽的。封装的目的是使对象的使用者和生产者分离,使对象的定义和实现分开。一个对象通常可由三部分组成,分别是对象名、属性和操作(方法)。
面向对象系统设计(OOD)阶段对分析阶段给出的问题域模型,用面向对象的方法设计出软件基础架构(概要设计)和完整的类结构(详细设计),以实现业务功能。设计阶段主要包括用例设计、类设计和子系统设计等。
用例设计
用例设计的主要目的如下:
.利用交互改进用例实现。
.调整对设计类的操作需求。
.调整对子系统和(或)它们的接口的操作需求。
.调整对封装体的操作需求。
用例设计通常使用交互(特别是序列图)来说明系统的行为。当系统或者子系统的行为主要通过同步消息传递来说明时,序列图非常有用。由于消息序列通常没有严格的定义,因此,尤其是在事件驱动系统中,异步消息传递更容易利用状态机和协作来进行说明。
类设计
类是设计工作的核心,系统的实际工作其实也是由类执行的。子系统、包、封装体以及协作关系等其他设计元素只是说明了类的组合方式或协同操作方式。
类设计的主要目的如下:
.确保类可为用例实现提供必需的行为。
.确保提供充足的信息来明确无误地实施类。
.处理和类有关的非功能性需求。
.包含用于类的设计机制。
子系统设计
子系统是一种模型元素,它具有包(可包含其他模型元素)和类(具有行为)的语义。子系统的行为由它所包含的类或其他子系统提供。子系统实现一个或多个接口,这些接口定义子系统可执行的行为。
子系统设计的主要目的如下:
.用所包含类的协作来定义在子系统接口中指定的行为。
.记录子系统的内部结构。
.定义子系统接口和包含类之间的实现关系。
.确定对其他子系统的依赖关系。
40. 多态有不同的形式,( )的多态是指同一个名字在不同上下文中所代表的含义不同。
A. 参数
B. 包含
C. 过载
D. 强制
多态性(Polymorphism)同继承性一样,是面向对象程序设计的标志性特征,是一个考查重点。
多态性是考虑在不同层次的类中以及在同一类中,同名的成员函数之间的关系问题。函数的重载和运算符的重载都属于多态性中的编译时的多态性。运行时的多态性是以虚基类为基础的多态性。
1)多态的定义
多态是指同样的消息被不同类型的对象接受时导致不同的行为(不同的实现或调用了不同的函数)。所谓消息,是由"类::方法"(功能)和"方法的实参"(消息数据)共同组成的。
产生多态性的原因是:不同的对象在处理同样的消息时,使用的方法实现(成员函数的函数体)不同。"多态性"是与"类的派生和继承"联系在一起的,是基类中所定义方法的"多态性"。对于在派生类中新增加的方法,是没有多态性的。
2)分类
(1)重载多态:成员函数(运算符)重载。
(2)强制多态:强制类型转换。把一个变量的类型变换成另一种类型,以符合一个函数或者操作的要求。例如,加法运算符在执行浮点数和整数的相加时,首先把整数转换成浮点数,然后再相加。
(3)包含多态:主要通过虚函数来实现。强调不同类中的同名成员函数的多态行为。
(4)参数多态:可通过函数模板和类模板来实现。
在C++中有两种多态性。
(1)编译时的多态性:通过函数的重载和运算符的重载来实现。
(2)运行时的多态性:是指在程序执行前,无法根据函数名和参数来确定该调用哪一个函数,必须在程序执行过程中,根据执行的具体情况来动态地确定。这种多态性是通过类继承关系和虚函数(Virtual Function)来实现的。
3)虚函数
虚函数是前面有virtual关键字的类的成员函数,定义虚函数的格式如下:

注意:virtual关键字只用在类定义里的函数声明中,写函数体时不用。
另外,如果基类中的函数不是虚函数,即没有virtual关键字,即使派生类中写了virtual也没有用,不能实现多态。
使用虚函数时,需要注意以下几点。
(1)派生类中定义虚函数除必须与基类中的虚函数同名外,还必须同参数表、同返回类型。如基类中返回基类指针,派生类中返回派生类指针是允许的。
(2)只有类的成员函数才能说明为虚函数。
(3)静态成员函数不能作为虚函数。
(4)实现动态多态性时,必须使用基类指针或引用,使该指针指向不同派生类的对象,并指向虚函数。
(5)内联函数不能作为虚函数。
(6)析构函数可定义为虚函数,构造函数不能为虚函数。在基类中及其派生类中都有动态分配的内存空间时,必须把析构函数定义为虚函数,实现撤销对象时的多态性。
4)纯虚函数和抽象类
(1)纯虚函数(Pure Virtual Function):指被标明为不具体实现的虚拟成员函数。定义纯虚函数的一般格式为:

例如:

定义纯虚函数必须注意以下几点。
.定义纯虚函数时,不能定义虚函数的实现部分。
."=0"本质上是将指向函数体的指针定义为NULL。
.在派生类中必须有重新定义的纯虚函数的函数体,这样的派生类才能用来定义对象。
(2)抽象类:包含纯虚函数的类。
抽象类只能作为基类来派生新类使用,不能创建抽象类的对象,可声明一个抽象类的指针和引用。
在抽象类的成员函数内可以调用纯虚函数,但是在构造函数或析构函数内部不能调用纯虚函数。因为在构造函数或析构函数内部调用虚函数采用的是静态联编,即编译时就要生成调用该函数的指令,而纯虚函数是没有代码的,所以这样的调用指令无法生成,因此编译会报错。在普通成员函数内可以调用纯虚函数,尽管纯虚函数是没有代码的,但是此时是动态联编,编译时不需要生成调用该函数的指令,所以编译可以通过。在运行时决定到底调用的是自己还是派生类的函数,因为自己是个抽象类,不可能生成对象,所以不可能调用自己的这个纯虚函数。
5)虚析构函数
只要基类的析构函数是虚函数,那么派生类的析构函数不论是否使用virtual关键字,不论是自己定义的还是编译器默认生成的,都自动成为虚函数。
一个类的构造函数会在执行自己代码之前,依派生顺序自动调用它的所有直接基类的构造函数;一个类的析构函数也会在执行完自己的代码之后,以与构造函数调用次序相反的顺序自动调用其所有直接基类的析构函数。一般来说,一个类如果定义了虚函数,则应该将析构函数也定义成虚函数。
41. 某类图如图所示,下列选项错误的是( )。 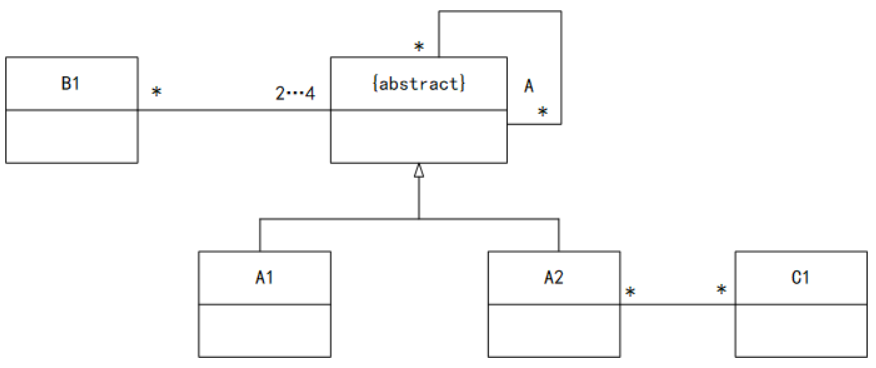
A. 一个A1的对象可能与一个A2的对象关联
B. 一个A的非直接对象可能与一个A1的对象关联
C. 类B1的对象可能通过A2与C1的对象关联
D. 有可能A的直接对象与B1的对象关联
类图(Class Diagram)展现了一组对象、接口、协作及其之间的关系。在面向对象系统的建模中所建立的最常见的图就是类图。
类图给出了系统的静态设计视图,包含主动类的类图给出了系统的静态进程视图。作为模型管理视图还可以含有包或子系统,二者都用于把模型元素聚集成更大的组块。类图用于对系统的静态视图建模。这种视图主要支持系统的功能需求,即系统要提供给最终用户的服务。当对系统的静态设计建模时,通常以下述3种方式之一使用类图:对系统的词汇建模;对简单的协作建模;对逻辑数据库模式建模。
作为静态视图的类图可以包含依赖、关联、泛化、组合、实现关系以及注解和约束等。
(1)依赖关系是两个事物之间的语义关系,其中一个事物发生变化会影响另一个事物的语义。
(2)关联关系是一种结构关系,它描述了一组对象之间的链接关系。其中有一种特殊类型的关联关系,即聚集关系,它描述了整体与部分的结构关系。
(3)泛化关系是一种一般—特殊关系,利用这种关系,子类可以共享父类的结构和行为。
(4)实现关系是类之间的语义关系,其中的一个类制订了另一个类保证执行的契约。实现关系用于两种情况:在接口和实现它们的类或构件之间;在用例和它们的协作之间。
(5)组合是聚集关系的变种,表示元素间更强的组合关系。各种关系图例如下图所示。

各种关系图例
42. UML图中,对象图展现了(42),(43)所示对象图与 下图所示类图不一致。
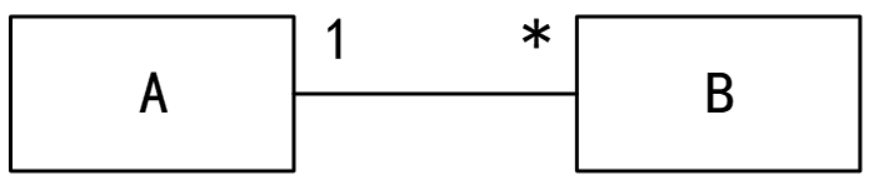
A. 一组对象、接口、协作和它们之间的关系
B. 一组用例、参与者以及它们之间的关系
C. 某一时刻一组对象以及它们之间的关系
D. 以时间顺序组织的对象之间的交互活动
类图(Class Diagram)展现了一组对象、接口、协作及其之间的关系。在面向对象系统的建模中所建立的最常见的图就是类图。
类图给出了系统的静态设计视图,包含主动类的类图给出了系统的静态进程视图。作为模型管理视图还可以含有包或子系统,二者都用于把模型元素聚集成更大的组块。类图用于对系统的静态视图建模。这种视图主要支持系统的功能需求,即系统要提供给最终用户的服务。当对系统的静态设计建模时,通常以下述3种方式之一使用类图:对系统的词汇建模;对简单的协作建模;对逻辑数据库模式建模。
作为静态视图的类图可以包含依赖、关联、泛化、组合、实现关系以及注解和约束等。
(1)依赖关系是两个事物之间的语义关系,其中一个事物发生变化会影响另一个事物的语义。
(2)关联关系是一种结构关系,它描述了一组对象之间的链接关系。其中有一种特殊类型的关联关系,即聚集关系,它描述了整体与部分的结构关系。
(3)泛化关系是一种一般—特殊关系,利用这种关系,子类可以共享父类的结构和行为。
(4)实现关系是类之间的语义关系,其中的一个类制订了另一个类保证执行的契约。实现关系用于两种情况:在接口和实现它们的类或构件之间;在用例和它们的协作之间。
(5)组合是聚集关系的变种,表示元素间更强的组合关系。各种关系图例如下图所示。
各种关系图例
在计算机系统中,对象是指一组属性及这组属性上的专用操作的封装体。属性可以是一些数据,也可以是另一个对象。每个对象都有它自己的属性值,表示该对象的状态,用户只能看见对象封装界面上的信息,对象的内部实现对用户是隐蔽的。封装的目的是使对象的使用者和生产者分离,使对象的定义和实现分开。一个对象通常可由三部分组成,分别是对象名、属性和操作(方法)。
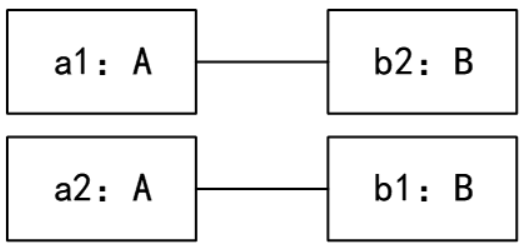
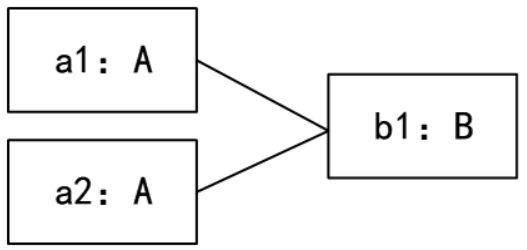
43. UML图中,对象图展现了(42),(43)所示对象图与 下图所示类图不一致。
A.

B.
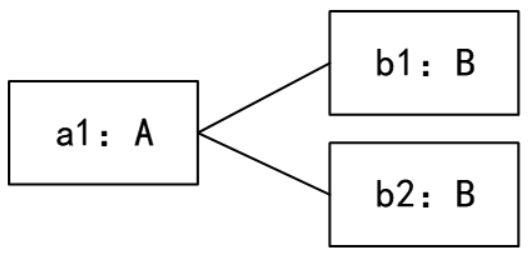
C.
D.
44. 某快餐厅主要制作并出售儿童套餐,一般包括主餐(各类比萨)、饮料和玩具,其餐品种类可能不同,但制作过程相同。前台服务员(Waiter) 调度厨师制作套餐。欲开发一软件,实现该制作过程,设计如下所示类图。该设计采用(44)模式将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。其中,(45)构造一个使用Builder接口的对象。该模式属于(46)模式,该模式适用于(47)的情况。
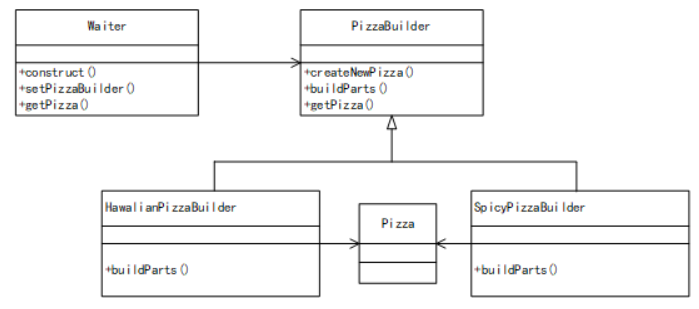
A. 生成器(Builder)
B. 抽象工厂(Abstract Factory)
C. 原型(Prototype)
D. 工厂方法(Factory Method)
类图(Class Diagram)展现了一组对象、接口、协作及其之间的关系。在面向对象系统的建模中所建立的最常见的图就是类图。
类图给出了系统的静态设计视图,包含主动类的类图给出了系统的静态进程视图。作为模型管理视图还可以含有包或子系统,二者都用于把模型元素聚集成更大的组块。类图用于对系统的静态视图建模。这种视图主要支持系统的功能需求,即系统要提供给最终用户的服务。当对系统的静态设计建模时,通常以下述3种方式之一使用类图:对系统的词汇建模;对简单的协作建模;对逻辑数据库模式建模。
作为静态视图的类图可以包含依赖、关联、泛化、组合、实现关系以及注解和约束等。
(1)依赖关系是两个事物之间的语义关系,其中一个事物发生变化会影响另一个事物的语义。
(2)关联关系是一种结构关系,它描述了一组对象之间的链接关系。其中有一种特殊类型的关联关系,即聚集关系,它描述了整体与部分的结构关系。
(3)泛化关系是一种一般—特殊关系,利用这种关系,子类可以共享父类的结构和行为。
(4)实现关系是类之间的语义关系,其中的一个类制订了另一个类保证执行的契约。实现关系用于两种情况:在接口和实现它们的类或构件之间;在用例和它们的协作之间。
(5)组合是聚集关系的变种,表示元素间更强的组合关系。各种关系图例如下图所示。
各种关系图例
接口实际上是一组抽象方法的集合。接口本身的访问控制只能够是public和默认的,不能是private和protected。因为接口的目的就是让其他的类来实现其中的方法或使用其中的常量。因此,接口中的方法永远是public和abstract,而接口中的常量永远是public、final和static。为接口定义方法和常量时,不需要加任何修饰符。
1)接口的定义
接口定义很像类定义,它使用的关键字是interface。下面是一个接口的通用形式:

其中,access要么是public,要么就没有用修饰符。当没有访问修饰符时,则是默认访问范围。当它声明为public时,则接口可以被任何代码使用。name是接口名,它可以是任何合法的标识符。注意定义的方法没有方法体。它们以参数列表后面的分号作为结束。它们本质上是抽象方法;在接口中指定的方法没有默认的实现。每个包含接口的类必须实现所有的方法。接口声明中可以声明变量。它们一般是final和static型的,意思是它们的值不能通过实现类而改变。它们还必须以常量值初始化。如果接口本身定义成public,所有方法和变量都是public。
2)接口的实现
一旦接口被定义,一个或多个类可以实现该接口。为实现一个接口,在类定义中包括implements子句,然后创建接口定义的方法。一个包括implements子句的类的一般形式如下:

同样,access要么是public,要么是没有修饰符的。如果一个类实现多个接口,这些接口被逗号分隔。如果一个类实现两个声明了同样方法的接口,那么相同的方法将被其中任何一个接口客户使用。实现接口的方法必须声明成public。而且实现方法的类型必须严格与接口定义中指定的类型相匹配。
3)接口的继承
接口可以通过运用关键字extends被其他接口继承。语法与继承类是一样的。当一个类实现一个继承了另一个接口的接口时,它必须实现接口继承链表中定义的所有方法。例如:

在计算机系统中,对象是指一组属性及这组属性上的专用操作的封装体。属性可以是一些数据,也可以是另一个对象。每个对象都有它自己的属性值,表示该对象的状态,用户只能看见对象封装界面上的信息,对象的内部实现对用户是隐蔽的。封装的目的是使对象的使用者和生产者分离,使对象的定义和实现分开。一个对象通常可由三部分组成,分别是对象名、属性和操作(方法)。
45. 某快餐厅主要制作并出售儿童套餐,一般包括主餐(各类比萨)、饮料和玩具,其餐品种类可能不同,但制作过程相同。前台服务员(Waiter) 调度厨师制作套餐。欲开发一软件,实现该制作过程,设计如下所示类图。该设计采用(44)模式将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。其中,(45)构造一个使用Builder接口的对象。该模式属于(46)模式,该模式适用于(47)的情况。
A. PizzaBuilder
B. SpicyPizaBuilder
C. Waiter
D. Pizza
46. 某快餐厅主要制作并出售儿童套餐,一般包括主餐(各类比萨)、饮料和玩具,其餐品种类可能不同,但制作过程相同。前台服务员(Waiter) 调度厨师制作套餐。欲开发一软件,实现该制作过程,设计如下所示类图。该设计采用(44)模式将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。其中,(45)构造一个使用Builder接口的对象。该模式属于(46)模式,该模式适用于(47)的情况。
A. 创建型对象
B. 结构型对象
C. 行为型对象
D. 结构型类
47. 某快餐厅主要制作并出售儿童套餐,一般包括主餐(各类比萨)、饮料和玩具,其餐品种类可能不同,但制作过程相同。前台服务员(Waiter) 调度厨师制作套餐。欲开发一软件,实现该制作过程,设计如下所示类图。该设计采用(44)模式将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。其中,(45)构造一个使用Builder接口的对象。该模式属于(46)模式,该模式适用于(47)的情况。
A. 当一个系统应该独立于它的产品创建、构成和表示时
B. 当一个类希望由它的子类来指定它所创建的对象的时候
C. 当要强调一系列相关的产品对象的设计以便进行联合使用时
D. 当构造过程必须允许被构造的对象有不同的表示时
48. 函数foo()、hoo0定义如下,调用函数hoo()时,第-个参数采用传值(call by value)方式,第二个参数采用传引用(call by reference)方式。设有函数调(函数foo(5),那么"print(x)”执行后输出的值为( )。
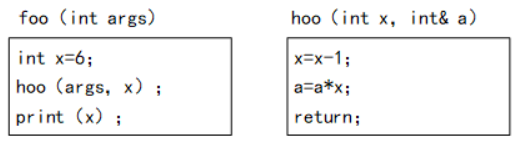
A. 24
B. 25
C. 30
D. 36
函数可以被看作是一个由用户定义的操作。一般来说,函数用一个名字来表示,函数的操作数称为参数(parameter),由一个位于括号中并且用逗号分隔的参数表(Parameter List)指定。函数的结果被称为返回值(Return Value),返回值的类型被称为函数返回类型(Return Type)。不产生值的函数返回类型是void,意思是什么都不返回。函数执行的动作在函数体(body)中指定。函数体包含在花括号中,有时也称为函数块(Function Block)。函数返回类型以及其后的函数名、参数表和函数体构成了函数定义。
函数是C++语言程序的基本功能单元,其重要性不言而喻。函数接口的两个要素是参数和返回值。C语言中,函数的参数和返回值的传递方式有两种:值传递(Pass By Value)和指针传递(Pass by Pointer)。C++语言中多了引用传递(Pass by Reference)。
49. 程序设计语言的大多数语法现象可以用CFG (上 下文无关文法)表示。下面的CFG产生式集用于描述简单算术表达式,其中+、-、*表示加、减、乘运算,id表示单个字母表示的变量,那么符合该文法的表达式为( )。
P:E→E+T|E-T|T
T→T*F|F
F→F|id
A. a+-b-c
B. a*(b+c)
C. a*-b+2
D. -a/b+c
类和继承
1)类
一个类是一些属性和方法的封装体,类的定义用关键字class声明,用关键字public、protected、 private指定类的成员的存取控制属性:private(私有)成员只有类内部的方法才能访问,protected(保护)成员派生类和同一文件夹下的类可以访问,public(公有)成员可以从类的外部访问。默认是public。这体现了面向对象的以下指导思想:尽量将类内部的细节隐藏起来,对类的属性的操作应该通过类的方法来进行。
另外,public还可以用来修饰类,public类能够被其他文件夹下的类访问,非public类只能被同一文件夹下的类访问。一个.java文件中可以包含多个类,会被编译成多个.class文件,但只能有一个public类,而且该类名要和文件名一样。
2)继承
Java中用关键字extends表示类间的继承关系。父类的公有属性和方法成为子类的属性和方法,子类如果有和父类的同名、同参数类型的方法,那么子类对象在调用该方法时,调用的是子类的方法,亦即方法的重置。如果想要调用父类的同名方法,需要用super关键字(属性同理)。
子类的对象可以作为祖先类的对象使用,即所谓类的向上转换,反之则不行。具体表现在:可以用子类对象来对祖先类对象赋值,可以用子类对象作为实参去调用以父类对象为形参的函数。
对象的引用本质
Java中的对象实际上是对象的引用,本质上和C语言中的指针是一样的;但也和C语言指针不尽相同,例如,不能自增、自减,不能强制转换成其他类型。
例如:
构造方法
构造方法就是类的对象生成时会被调用的方法。每个类至少有一个构造方法(Constructor),也称构造函数。构造方法的名字和类名相同,没有任何返回类型。每个类都有一个默认的构造方法,但当用户自定义了构造方法后,默认的构造函数就不再有效了。
重载
同一个类中的两个或两个以上方法,名字相同,而参数个数不同或参数类型不同,称为重载。注意:不能有各方法名字和参数都一样,而仅仅返回值类型不同。
静态属性和静态方法
静态属性和静态方法的声明用关键字static实现,一个类的静态属性只有一份,由所有该类的对象共享。不需要创建对象也能访问类的静态属性和方法,访问方式为"类名.静态属性或静态方法",静态方法与对象无关,因此不能在静态方法中访问非静态属性和调用非静态方法。
this和super关键字
这两个关键字颇为重要。this代表当前对象,super代表当前对象的父类的东西。
this主要用途有以下两个。
(1)一个构造函数调用另一个构造函数,对构造函数的调用必须是第一条语句。
(2)将对象自身作为参数来调用一个函数。
super的用途如下:在子类中调用父类的同名方法,或在子类的构造函数中调用父类的构造函数,此时亦必须是第一条语句。
多态
所谓多态,是指通过基类对象调用一个基类和派生类都有的方法时,在运行时才能确定到底调用的是基类的方法还是派生类的方法。多态的好处是增加了程序的可扩展性。多态是通过动态联编实现的,即编译时不确定,程序运行时才确定调用哪个函数。
抽象类与接口
1)抽象类
抽象类通过关键字abstract实现,抽象类的目的是定义一个框架,规定某些类必须具有的一些共性。
包含抽象方法的类一定是抽象类,所谓抽象方法是指没有函数体的方法。
抽象类的直接派生类必须实现其抽象方法;抽象类只能用于继承,不能创建对象。
2)接口(Interface)
接口用关键字interface声明,只能用于继承。注意:此时关键字为implements(实现)。接口用于替代多继承的概念,能实现多继承的部分特点,又避免了多继承的混乱,还能起到规定程序框架的作用。注意:接口也可以用于多态。
直接继承了接口的类,必须实现接口中的抽象方法;间接的则可以实现,也可以不实现。
3)抽象类与接口的异同
接口和抽象类都不能创建对象。
抽象类不能参与多继承,抽象类可以有非静态的成员变量,可以有非抽象方法;接口可以参与多继承,所有属性都是静态常量,所有方法都是public抽象方法。
异常处理
1)异常概念
异常,即出错,比如0作为除数、找不到类、打开文件错误、数组越界等。异常如果不进行处理,那么程序运行就会结束;如果进行处理,那么会在执行完异常处理代码后继续运行。
Java中所有异常类均继承自类Exception。
Java中的异常类层次结构如下:
此外,还有EOFException、 FileNotFoundException、 MalformedURLException等。
2)捕获异常
异常处理的典型用法如下,将可能出现异常的代码放在try块中,其后由一个或多个catch捕获相应异常进行处理,注意只执行第一个匹配的catch块,忽略后面的。
如果某个方法中所产生的异常该方法自己没有处理,那么可以在调用该方法的方法中进行处理,如果自己处理了,那么调用它的方法就无法得到该异常。
3)抛出异常
异常除了运行中系统产生的之外,也可以主动抛出异常,用关键字throw,如throw new Exception()。注意:throw只能抛出Throwable子类的异常。
4)带throws关键字的方法
带throws关键字的方法声明如下:
强制调用该方法的方法必须处理可能发生的异常,或者将异常重新定向。假定方法A带throws关键字,而方法B中调用了方法A,则方法B中必须有处理方法A中可能产生的异常的语句,或者方法B也带throws关键字,指明调用方法B的方法必须处理异常。
final关键字
用final关键字定义的常量,在其初始化或第一次赋值后,其值不能被改变。常量必须先有值,然后才能使用。对于常量的第一次赋值只能在构造函数中进行。
final对象的值不能被改变,指的是该对象不能再指向其他对象,而不是指不能改变当前对象内部的属性值。
函数参数声明为final后,函数中不能改变其值。
final方法是不能被重置的方法。
final类不能被继承,其所有方法都是final的,但属性可以不是final的。
程序设计语言(Programming Language)是用于编写计算机程序的语言。语言的基础是一组记号和一组规则,根据规则由记号构成的记号串的总体就是语言。在程序设计语言中,这些记号串就是程序。程序设计语言包含三个方面,即语法、语义和语用。语法表示程序的结构或形式,即表示构成程序的各个记号之间的组合规则,但不涉及这些记号的特定含义,也不涉及使用者。语义表示程序的含义,即表示按照各种方法所表示的各个记号的特定含义,但也不涉及使用者。语用表示程序与使用的关系。
程序设计语言的基本成分有:数据成分,用于描述程序所涉及的数据;运算成分,用以描述程序中所包含的运算;控制成分,用以描述程序中所包含的控制;传输成分,用以表达程序中数据的传输。
程序设计语言按照语言级别可以分为低级语言和高级语言。低级语言有机器语言和汇编语言。低级语言与特定的机器有关、功效高,但使用复杂、繁琐、费时、易出差错。机器语言是表示成数码形式的机器基本指令集,或者是操作码经过符号化的基本指令集。汇编语言是机器语言中地址部分符号化的结果,或进一步包括宏构造。高级语言的表示方法要比低级语言更接近于待解问题的表示方法,其特点是在一定程度上与具体机器无关,易学、易用、易维护。常见的有Java、C、C++、PHP、Python和Delphi等。这类语言与人们使用的自然语言比较接近,大大提高了程序设计的效率。
50. 某有限自动机的状态转换图如下图所示,该自动机可识别( )。

A. 1001
B. 1100
C. 1010
D. 0101
51. 某高校信息系统设计的分E-R图中,人力部门定义的职工实体具有属性:职工号、姓名、性别和出生日期;教学部门定义的教师实体具有属性:教师号、姓名和职称。这种情况属于(51),在合并E-R图时,(52)解决这一冲突。
A. 属性冲突
B. 命名冲突
C. 结构冲突
D. 实体冲突
实体是现实世界中可以区别于其他对象的"事件"或"物体"。每个实体由一组特性(属性)来表示,其中的某一部分属性可以唯一表示实体。实体集是具有相同属性的实体集合。
信息系统是用于收集、处理、存储、分发信息的相互关联的组件的集合,其作用在于支持组织的决策与控制。
信息系统包括三项活动,如下图所示。
信息系统的三项活动
.输入活动:从组织或外部环境中获取或收集原始数据。
.处理活动:将输入的原始数据转换为更有意义的形式。
.输出活动:将处理后形成的信息传递给人或者需要此信息的活动。
反馈是把输出信息返回到组织内相应成员中,组织成员借助反馈信息来评测或纠正输入阶段的活动。
信息系统的组成包含七大部分:
.计算机硬件系统。
.计算机软件系统。
.数据及存储介质。
.通信系统。
.非计算机系统的信息收集、处理设备。
.规章制度。
.工作人员。
从用途类型来划分,信息系统一般可分为电子商务系统、事务处理系统、管理信息系统、生产制造系统、电子政务系统和决策支持系统等。
信息系统集成是采用现代管理理论(例如软件工程、项目管理等)作为计划、设计、控制的方法论,将硬件、软件、数据库、网络等部件按照规划的结构和秩序,有机地整合到一个有清晰边界的信息系统中,以达到既定系统目标的过程。
信息系统设计是开发阶段的重要内容,其主要任务是从信息系统的总体目标出发,根据系统逻辑功能要求,并结合经济、技术条件、运行环境和进度等要求,确定系统的总体架构和系统各组成部分的技术方案,合理选择计算机、通信及存储的软硬件设备,制订系统的实施计划。
方案设计
系统方案设计包括总体设计和各部分的详细设计。
.系统总体设计:包括系统的总体架构方案设计、软件系统的总体架构设计、数据存储的总体设计、计算机和网络系统的方案设计等。
.系统详细设计:包括代码设计、数据库设计、人机界面设计、处理过程设计等。
系统架构
系统架构是将系统整体分解为更小的子系统和组件,从而形成不同的逻辑层或服务,然后进一步确定各层的接口,层与层相互之间的关系。
对整个系统的分解,既需要进行“纵向”分解,也需要对同一逻辑层进行“横向”分解,系统的分解可参考“架构模式”进行。系统的选型主要取决于系统架构。
设备、DBMS及技术选型
在系统设计中进行设备、DBMS及技术选型时,不仅要考虑系统的功能要求,还要考虑系统实现的内外环境和主客观条件。在选型时,需要权衡各种可供选择的计算机硬件技术、软件技术、数据管理技术、数据通信技术和计算机网络技术及相关产品;同时也要考虑用户的使用要求、系统运行环境、现行的信息管理和信息技术标准、规范和有关法律制度等。
52. 某高校信息系统设计的分E-R图中,人力部门定义的职工实体具有属性:职工号、姓名、性别和出生日期;教学部门定义的教师实体具有属性:教师号、姓名和职称。这种情况属于(51),在合并E-R图时,(52)解决这一冲突。
A. 职工和教师实体保持各自属性不变
B. 职工实体中加入职称属性,删除教师实体
C. 教师也是学校的职工,故直接将教师实体删除
D. 将教师实体所有属性并入职工实体,删除教师实体
53. 假设关系R, U={A,B,C,D,E}, F= {A→BC,AC→D,B→D},那么在关系R中( )。
A. 不存在传递依赖,候选关键字A
B. 不存在传递依赖,候选关键字AC
C. 存在传递依赖A→D,候选关键字A
D. 存在传递依赖B→D,候选关键字C
54. 关系R、S如下表所示,的结果集为(54),R、S的左外联接、右外联接和完全外联接的元组个数分别为(55)。
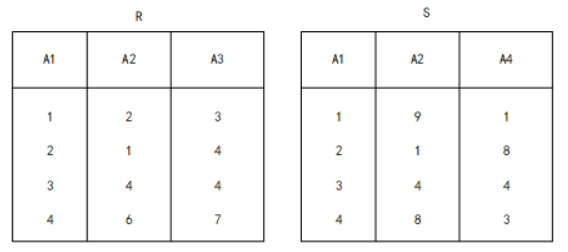
A. { (2,1,4),(3,4,4)}
B. { (2,1,4,8),(3,4,4,4)}
C. { (C,1.4.2,1.8).(3.4.4.3,4,4)}
D. { (1,2,3,1,9,1),(2,1,4,2,1,8),(3,4,4,3,4,4).(4,6,7.4,8,3)}
55. 关系R、S如下表所示,的结果集为(54),R、S的左外联接、右外联接和完全外联接的元组个数分别为(55)。
A. 2,2,4
B. 2,2,6
C. 4,4,4
D. 4,4,6
56. 某企业信息系统采用分布式数据库系统。”当某一场地故障时,系统可以使用其他场地上的副本而不至于使整个系统瘫痪"称为分布式数据库的( )。
A. 共享性
B. 自治性
C. 可用性
D. 分布性
数据库(DataBase,DB)是指长期存储在计算机内的、有组织的、可共享的数据集合。数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
系统使用的所有数据存储在一个或几个数据库中。
分布式DBMS包括物理上分布、逻辑上集中的分布式数据库结构和物理上分布、逻辑上分布的分布式数据库结构两种。前者的指导思想是把单位的数据模式(称为全局数据模式)按数据来源和用途,合理分布在系统的多个节点上,使大部分数据可以就地或就近存取。数据在物理上分布后,由系统统一管理,使用户不感到数据的分布。后者一般由两部分组成:一是本节点的数据模式;二是本节点共享的其他节点上有关的数据模式。节点间的数据共享由双方协商确定。这种数据库结构有利于数据库的集成、扩展和重新配置。
简单地说,数据库系统就是基于数据库的计算机应用系统。这样一个系统包括以下内容。
①以数据为主体的数据库。
②管理数据库的系统(DBMS)。
③支持数据库系统的计算机硬件环境和操作系统环境。
④管理和使用数据库系统的人——数据库管理员。
1)数据库的定义和特征
数据库,顾名思义就是存放数据的仓库,这种想当然的理解是不准确的。数据库对应的英文单词是DataBase,如果直译则是数据基地;而数据仓库则另有其词DataWarehouse。所以数据库和数据仓库不是同义词,数据仓库是在数据库技术的基础上发展起来的又一新的应用领域。
数据库技术发展到今天已经是一门成熟的技术,但却没有一个被普遍接受的、严格的定义。数据库是相互关联数据的集合,这是大家公认的数据库的基本特征之一。下面一段话概括了数据库应该具备的一些特征,也可以把它作为数据库的定义。
数据库是相互关联数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
(1)相互关联的数据集合。数据库中的数据不是孤立的,数据与数据之间是相互关联的。也就是说,在数据库中不仅要能够表示数据本身,还要能够表示数据与数据之间的联系。比如在学籍管理中,有学生和课程两类数据,在数据库中除了要存放这两类数据之外,还要存放哪些学生选修了哪些课程或哪些课程由哪些学生选修这样的信息,这就反映了学生数据和课程数据之间的联系。
(2)用综合的方法组织数据。数据库能够根据不同的需要按不同的方法组织数据,如可以用顺序组织方法、索引组织方法、聚集(Cluster)组织方法等。
(3)低冗余与数据共享。由于在数据库技术之前,数据文件都是独立的,所以任何数据文件都必须含有满足某应用的全部数据。比如,人事部门有一个职工文件,教育部门也有一个职工文件,两个部门的职工文件中都有"职工基本情况"的数据,也就是说这一部分数据是重复存储的,如果还有第三、第四个部门也有类似的职工文件,那么重复存储所造成的空间浪费是很大的。在数据库中,可以共享类似"职工基本情况"这样的共用数据,从而降低数据的冗余度。
(4)数据具有较高的独立性。数据独立性是指数据的组织和存储方式与应用程序互不依赖、彼此独立的特性。在数据库技术之前,数据文件的组织方式和应用程序是密切相关的,当改变数据结构时,相应的应用程序也必须随之修改,这样就大大增加了应用程序的开发代价和维护代价。而数据库技术却可以使数据的组织和存储方法与应用程序互不依赖,从而大大降低应用程序的开发代价和维护代价。
(5)保证数据的安全、可靠。数据库技术要能够保证数据库中的数据是安全、可靠的。数据库要有一套安全机制,以便可以有效地防止数据库中的数据被非法使用或非法修改;数据库还要有一套完整的备份和恢复机制,以便保证当数据遭到破坏时(软件或硬件故障引起的),能立刻将数据完全恢复,从而保证系统能够连续、可靠地运行。
(6)最大限度地保证数据的正确性。保证数据正确的特性在数据库中称为数据完整性。在数据库中可以通过建立一些约束条件保证数据库中的数据是正确的。比如输入年龄小于0或者大于200时,数据库能够主动拒绝这类错误。
(7)数据可以并发使用并能同时保证数据的一致性。数据库中的数据是共享的,并且允许多个用户同时使用同一数据,这就要求数据库能够协调一致,保证各个用户之间对数据的操作不发生矛盾和冲突,即在多个用户同时使用数据库的情况下,能够保证数据的一致性和正确性。
2)数据库管理系统
数据库的各种功能和特性,并不是数据库中的数据所固有的,而是靠管理或支持数据库的系统软件——数据库管理系统(DataBase Management System, DBMS)提供的。一个完备的数据库管理系统应该具备上一节提到的各种功能,其任务就是对数据资源进行管理,并且使之能为多个用户共享,同时还能保证数据的安全性、可靠性、完整性、一致性,并要保证数据的高度独立性。一个数据库管理系统应该具备以下功能。
(1)数据库定义功能。可以定义数据库的结构和数据库的存储结构,可以定义数据库中数据之间的联系,可以定义数据的完整性约束条件和保证完整性的触发机制等。
(2)数据库操纵功能。可以完成对数据库中数据的操纵,可以装入、删除、修改数据,可以重新组织数据库的存储结构,可以完成数据库的备份和恢复等操作。
(3)数据库查询功能。可以以各种方式提供灵活的查询功能,可以使用户方便地使用数据库中的数据。
(4)数据库控制功能。可以完成对数据库的安全性控制、完整性控制、多用户环境下的并发控制等各方面的控制。
(5)数据库通信功能。在分布式数据库或提供网络操作功能的数据库中还必须提供数据库的通信功能。
3)数据库管理员
从事数据库管理工作的人员称为数据库管理员(DataBase Administrator, DBA)。DBA有大量的工作要做,既有技术方面的工作,又有管理方面的工作,要参加数据库开发和使用的全部工作。总体来说,DBA的工作可以概括如下。
(1)在数据库规划阶段要参与选择和评价与数据库有关的计算机软件和硬件,要与数据库用户共同确定数据库系统的目标和数据库应用需求,要确定数据库的开发计划。
(2)在数据库设计阶段要负责数据库标准的制定和共用数据字典的研制,要负责各级数据库模式的设计,要负责数据库安全、可靠方面的设计。
(3)在数据库运行阶段首先要负责对用户进行数据库方面的培训;要负责数据库的转储和恢复;要负责对数据库中的数据进行维护;要负责监视数据库的性能,并调整、改善数据库的性能,提高系统的效率;要继续负责数据库安全系统的管理;要在运行过程中发现问题、解决问题。
4)数据库的发展
数据库的核心任务是数据管理,它包括数据的分类、组织、编码、存储、检索和维护等。数据管理经历了以下3个阶段。
(1)人工管理阶段。人工管理阶段是指计算机诞生的初期(20世纪50年代中期以前)。这个时期的计算机技术,从硬件看还没有磁盘这样的可直接存取的存储设备,从软件看没有操作系统,更没有管理数据的软件。这个时期数据管理的特点如下。
①数据不保存。因为计算机主要用于科学计算,一般也不需要长期保存数据,只是在完成某一个计算或课题时才将数据输入,然后不仅原始数据不保存,计算结果也不保存。
②没有文件的概念。这个时期的数据组织必须由每个程序的程序员自行组织和安排。
③一组数据对应一个程序。每组数据只对应一个应用,即使两个程序用到相同的数据,也必须各自定义、各自组织,数据无法共享、无法相互利用和互相参照。因此,程序和程序之间有大量的数据重复。
④没有形成完整的数据管理的概念。由于以上几个特点及没有对数据进行管理的软件系统,所以这个时期的每个程序都要包括数据存取方法、输入输出方法和数据组织方法等。因为程序是直接面向存储结构的,所以存储结构的任何一点修改,都会导致程序的修改,程序与数据不具有独立性。
(2)文件系统阶段。文件系统阶段是指20世纪50年代后期到60年代中期这一阶段。从那时起,计算机不仅大量用于科学计算,也开始大量用于信息管理。像磁盘这样的直接存取存储设备也已经出现,在软件方面也有了操作系统和高级语言,还有了专门用于数据管理的软件,即文件系统(或操作系统的文件管理部分)。这个阶段的数据管理具有以下特点。
①数据可以长期保存在磁盘上,也可以反复使用,即可以经常对文件进行查询、修改、插入和删除等操作。
②操作系统提供了文件管理功能和访问文件的存取方法,程序和数据之间有了数据存取的接口,程序开始通过文件名和数据打交道,可以不再关心数据的物理存放位置。因此,这时也有了数据的物理结构和数据的逻辑结构的区别。程序和数据之间有了一定的独立性。
③文件的形式已经多样化。由于有了磁盘这样的直接存取存储设备,文件也就不再局限于顺序文件,也有了索引文件、链表文件等。因而,对文件的访问可以是顺序访问,也可以是直接访问。但文件之间是独立的,它们之间的联系要通过程序去构造,文件的共享性还比较差。
④有了存储文件以后,数据就不再仅仅属于某个特定的程序,而是可以由多个程序反复使用。但文件结构的设计仍然是基于特定的用途,程序仍然是基于特定的物理结构和存取方法编制的。因此,数据的存储结构和程序之间的依赖关系并未根本改变。
⑤数据的存取基本上以记录为单位。
(3)数据库系统阶段。数据库系统阶段从20世纪60年代后期开始,数据库技术的诞生既有计算机技术的发展做依托,又有数据管理的需求做动力。数据库的数据不再是面向某个应用或某个程序,而是面向整个企业(组织)或整个应用。
信息系统是用于收集、处理、存储、分发信息的相互关联的组件的集合,其作用在于支持组织的决策与控制。
信息系统包括三项活动,如下图所示。
信息系统的三项活动
.输入活动:从组织或外部环境中获取或收集原始数据。
.处理活动:将输入的原始数据转换为更有意义的形式。
.输出活动:将处理后形成的信息传递给人或者需要此信息的活动。
反馈是把输出信息返回到组织内相应成员中,组织成员借助反馈信息来评测或纠正输入阶段的活动。
信息系统的组成包含七大部分:
.计算机硬件系统。
.计算机软件系统。
.数据及存储介质。
.通信系统。
.非计算机系统的信息收集、处理设备。
.规章制度。
.工作人员。
从用途类型来划分,信息系统一般可分为电子商务系统、事务处理系统、管理信息系统、生产制造系统、电子政务系统和决策支持系统等。
信息系统集成是采用现代管理理论(例如软件工程、项目管理等)作为计划、设计、控制的方法论,将硬件、软件、数据库、网络等部件按照规划的结构和秩序,有机地整合到一个有清晰边界的信息系统中,以达到既定系统目标的过程。
57. 以下关于Huffman (哈夫曼)树的叙述中,错误的是( )。
A. 权值越大的叶子离根结点越近
B. Huffman (哈夫曼)树中不存在只有一个子树的结点
C. Huffman (哈夫曼)树中的结点总数一定为奇数
D. 权值相同的结点到树根的路径长度一定相同
1)定义
树型结构是一类重要的非线性数据结构,其中以树和二叉树最为常用。
树是由一个或多个节点组成的有限集T,它满足以下两个条件:有一个特定的节点称为根节点;其余的节点分成m个互不相交的有限集T1, T2, …, Tm,其中每个集又都是一棵树,称T1, T2, …, Tm为根节点的子树。
可见树的定义是递归的,即一棵树由子树构成,子树又由更小的子树构成。
2)相关概念
.一个节点的子树数目称为该节点的度。
.树中各节点的度的最大值称为树的度。
.树中节点的最大层次称为树的深度。
若将树中节点的各子树看成是从左到右具有次序的,即不能交换,则称该树为有序树,否则称为无序树。
3)树的遍历
在应用树结构时,常要求按某种次序获得树中全部节点的信息,这可通过树的遍历操作来实现,常用的遍历方法如下。
.前序:先访问根节点,然后从左到右遍历根节点的各棵子树。
.后序:先从左到右遍历根节点的各棵子树,然后访问根节点。
.层序:先访问处于1层上的节点,然后从左到右依次访问处于2层、3层上的节点,即从上到下、从左到右逐层访问树中各层上的节点。
58. 通过元素在存储空间中的相对位置来表示数据元素之间的逻辑关系,是( )的特点。
A. 顺序存储
B. 链表存储
C. 索引存储
D. 哈希存储
A. 顺序存储,元素随机排列
B. 双向链表存储,元素随机排列
C. 顺序存储,元素有序排列
D. 双向链表存储,元素有序排列
线性表的定义
线性表是n个元素的有限序列,通常记为(a1,a2,…,an)。其特点如下。
.存在唯一的一个称为"第一个"的元素。
.存在唯一的一个称为"最后一个"的元素。
.除了表头外,表中的每一个元素均只有唯一的直接前驱。
.除了表尾外,表中的每一个元素均只有唯一的直接后继。
线性表的存储结构
1)顺序存储
线性表的顺序存储是用一组地址连续的存储单元依次存储线性表中的数据元素,从而使得逻辑关系相邻的两个元素在物理位置上也相邻。在这种存储方式下,存储逻辑关系无须占用额外的存储空间。其优点是可以随机存取表中的元素,缺点是插入和删除操作需要移动大量的元素。
一般地,在线性表的顺序存储结构中,第i个元素ai的存储位置为
LOC(ai)=LOC(a1)+(i-1)×L
式中,LOC(a1)为表中第一个元素的存储位置;L为表中每个元素所占空间的大小。
2)链式存储
线性表的链式存储是指用节点来存储数据元素,节点的空间可以是连续的,也可以是不连续的,因此存储数据元素的同时必须存储元素之间的逻辑关系。节点空间只有在需要的时候才申请,无须事先分配。最基本的节点结构如下图所示。
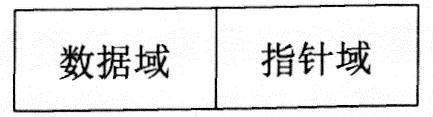
最基本的节点结构
其中,数据域用于存储数据元素的值,指针域则存储当前元素的直接前驱或直接后继信息,指针域中的信息称为指针(链)。n个节点通过指针连成一个链表,若节点中只有一个指针域,则称为线性链表(单链表)。
线性表采用链表作为存储结构时,不能进行数据元素的随机访问,但其优点是插入和删除操作不需要移动元素。以下是几种其他链表结构。
(1)双向链表。每个节点包含两个指针,指明直接前驱和直接后继元素,可在两个方向上遍历链表。
(2)循环链表。表尾节点的指针指向表中的第一个节点,可在任何位置上开始遍历整个链表。
(3)静态链表。借助数组来描述线性表的链式存储结构。
在链式存储结构中,只需要一个指针(头指针)指向第一个节点,就可以顺序访问到表中的任意一个元素。为了简化对链表状态的判定和处理,特别引入一个不存储数据元素的节点,称为头节点,将其作为链表的第一个节点并令头指针指向该节点。
线性表的插入和删除运算
1)基于顺序存储结构的运算
插入元素前要移动元素以挪出空的存储单元,然后再插入元素;删除元素时同样需要移动元素,以填充被删除的存储单元。在等概率下平均移动元素的次数分别是
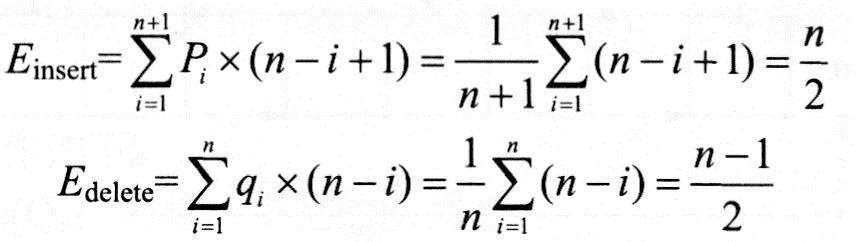
2)基于链式存储结构的运算
在链式存储结构下进行插入和删除,其实质都是对相关指针的修改。
(1)在单向链表中插入节点时,指针的变化情况如下图所示。
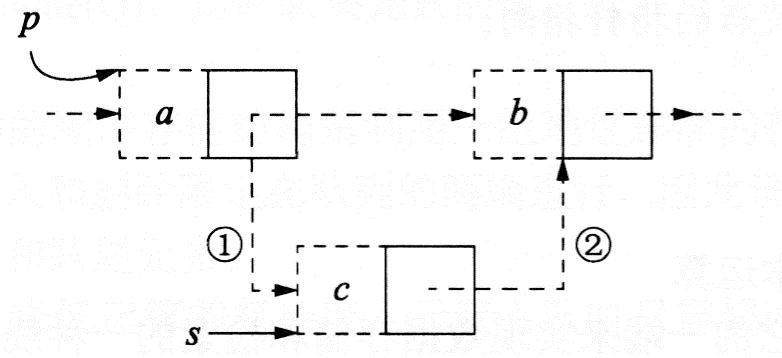
单向链表插入节点时的指针变化情况
(2)在单向链表中删除节点时,指针的变化情况如下图所示。
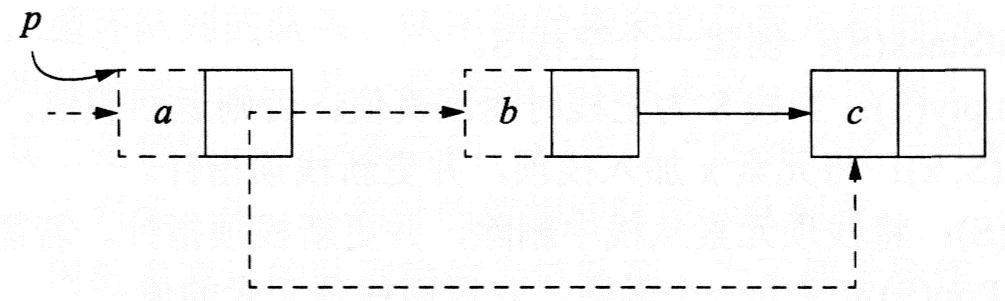
单向链表删除节点时的指针变化情况
(3)在双向链表中插入节点时,指针的变化情况如下图所示。
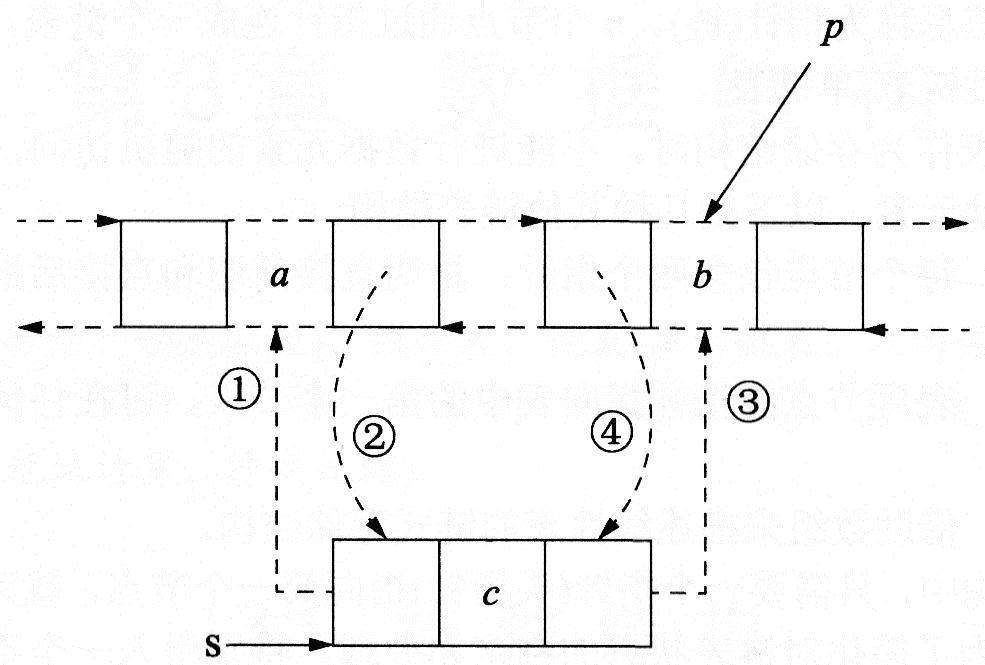
双向链表插入节点时的指针变化情况
(4)在双向链表中删除节点时,指针的变化情况如下图所示。

双向链表删除节点时的指针变化情况

1)顺序查找
顺序查找又称线性查找,顺序查找的过程是从线性表的一端开始,依次逐个与表中元素的关键字值进行比较,如果找到其关键字与给定值相等的元素,则查找成功;若表中所有元素的关键字与给定值比较都不成功,则查找失败。
2)折半查找
折半查找的过程是先将给定值与有序线性表中间位置上元素的关键字进行比较,若两者相等,则查找成功;若给定值小于该元素的关键字,那么选取中间位置元素关键字值小的那部分元素作为新的查找范围,然后继续进行折半查找;如果给定值大于该元素的关键字,那么选取比中间位置元素关键字值大的那部分元素作为新的查找范围,然后继续进行折半查找,直到找到关键字与给定值相等的元素或查找范围中的元素数量为零时结束。
3)分块查找
在分块查找过程中,首先将表分成若干块,每一块中关键字不一定有序,但块之间是有序的。此外,还建立了一个索引表,索引表按关键字有序。分块查找过程需分两步进行:先确定待查记录所在的块;然后在块中顺序查找。
4)哈希表及其查找
根据设定的哈希函数H(key)和处理冲突的方法,将一组关键字映射到一个有限的连续地址集上,并以关键字在地址集中的像作为记录在表中的存储位置,这种表称为哈希表,也称散列表。这一过程所得到的存储位置称为散列地址,由此形成的查找方法称为散列查找。
60. 某有向图如下所示,从顶点v1出发对其进行深度优先遍历,可能能得到的遍历序列是(60); 从顶点v1出发对其进行广度优先遍历,可能得到的遍历序列是(61)。
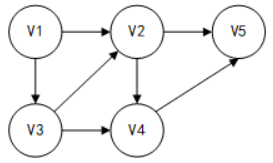
①v1 v2v3 v4 v5
②v1 v3 v4v5v2
③v1 v3v2v4 v5
④v1 v2v4v5 v3
A. ①②③
B. ①③④
C. ①②④
D. ②③④
从图G中任一个顶点v出发,深度优先遍历(DFS)的算法步骤如下。
(1)设立搜索指针p,使p指向顶点v。
(2)访问p顶点,并使p指向与p顶点相邻接的且尚未被访问过的顶点。
(3)若p不空,则重复步骤(2);否则执行步骤(4)。
(4)沿着刚才访问的次序、方向回溯到一个尚有邻接顶点且未被访问过的顶点,并使p指向这个未被访问的邻接顶点,然后重复步骤(2),直至所有的顶点均被访问为止。
这个算法的特点是尽可能先对纵深方向搜索,因此可以很容易得到其遍历的递归算法。
深度优先遍历图的过程实质上是对某个顶点查找其邻接节点的过程,其耗费的时间取决于所采用的存储结构。当图用邻接矩阵表示时,查找所有顶点的邻接点所需时间为O(n2)。若以邻接表作为图的存储结构,则需要O(e)的时间复杂度查找所有顶点的邻接点。因此,当以邻接表作为存储结构时,深度优先搜索遍历图的时间复杂度为O(n+e)。
61. 某有向图如下所示,从顶点v1出发对其进行深度优先遍历,可能能得到的遍历序列是(60); 从顶点v1出发对其进行广度优先遍历,可能得到的遍历序列是(61)。
①v1 v2v3 v4 v5
②v1 v3 v4v5v2
③v1 v3v2v4 v5
④v1 v2v4v5 v3
A. ①②
B. ①③
C. ②③
D. ③④
62. 对数组A=(2,8,7,1,3,5,6,4)用快速排序算法的划分方法进行一趟划分后得到的数组A为(62)(非递减排序, 以最后一个元素为基准元素)。进行一趟划分的计算时间为(63)。
A. (1,2,8,7,3,5,6,4)
B. (1,2,3,4,8,7,5,6)
C. (2,3,1,4,7,5,6,8)
D. (2,1,3,4,8,7,5,6)
数组的定义及基本运算
n维数组是一种"同构"的数据结构,其每个元素类型相同、结构一致。数组是定长线性表在维数上的扩张,即线性表中的元素又是一个线性表。
数组结构的特点是:数据元素数目固定;数据元素具有相同的类型;数据元素的下标关系具有上下界的约束且下标有序。
对数组进行的基本运算有以下两种。
(1)给定一组下标,存取相应的数据元素。
(2)给定一组下标,修改相应的数据元素中某个数据项的值。
数组的顺序存储
一旦定义了数组,结构中的数据元素个数和元素之间的关系就不再发生变动,因此数组适合于采用顺序存储结构。
由于计算机的内存结构是一维线性的,因此存储多维数组时必须按照某种方式进行降维处理,即将数组元素排成一个线性序列,这就产生了次序约定问题。对二维数组有两种存储方式:一种是以列为主序的存储方式;另一种是以行为主序的存储方式。
设每个数据元素占用L个单元,m、n为数组的行数和列数,那么以行为主序优先存储的地址计算公式为
Loc(aij)=Loc(a11)+((i-1)n+(j-1))L
同样的,以列为主序优先存储的地址计算公式为
Loc(aij)=Loc(a11)+((j-1)m+(i-1))L
快速排序的基本思想是:通过一趟排序将待排的记录分割为独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,然后再分别对这两部分记录继续进行排序,以达到整个序列有序。
具体做法是:附设两个指针low和high,它们的初值分别指向文件的第一个记录和最后一个记录。设枢轴记录的关键字为Pivotkey,则首先从high所指位置起向前搜索,找到第一个关键字小于Pivotkey的记录并与枢轴记录互相交换,然后从low所指位置起向后搜索,找到第一个关键字大于Pivotkey的记录并与枢轴记录相互交换,重复这两步直至low=high为止。
在所有同数量级(O(nlog2n))的排序方法中,快速排序被认为是平均性能最好的一种,但是,若初始记录序列按关键字有序或基本有序时,快速排序将退化为冒泡排序,此时算法的时间复杂度为O(n2)。
算法是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或多个操作。一个算法具有下列5个重要特性。
.有穷性。一个算法必须总是在执行有穷步之后结束,且每一步都可在有穷时间内完成。
.确定性。算法中的每一条指令必须有确切的含义,读者理解时不会产生二义性,并且在任何条件下,算法只有唯一的一条执行路径,即对于相同的输入只能得出相同的输出。
.可行性。一个算法是可行的,即算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现的。
.输入。一个算法有零个或多个输入,这些输入取自某个特定对象的集合。
.输出。一个算法有一个或多个输出,这些输出是同输入有着某些特定关系的量。
1)简单排序
简单排序包括直接插入排序、冒泡排序、简单选择排序等。
2)希尔排序
希尔排序的基本思想是:先将整个待排记录序列分割成若干序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
3)快速排序
快速排序是对冒泡排序的一种改进。先通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,然后分别对这两部分记录继续进行排序,以达到整个序列有序。
4)堆排序
堆排序的基本思想(小根堆)是:对一组待排序记录的关键字,首先把它们按堆的定义排成一个堆序列,从而输出堆顶的最小关键字;然后将剩余的关键字再调整成新堆,便得到次小的关键字,如此反复进行,直到全部关键字排成有序序列。
5)归并排序
归并排序是不断将多个小而有序的序列合成一个大而有序的序列的过程。
6)基数排序
基数排序的思想是按组成关键字的各个数位的值进行排序,它是分配排序的一种。
简单排序
简单排序包括直接插入排序、冒泡排序、简单选择排序等方法。
1)直接插入排序
直接插入排序的基本操作是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增1的有序表。
2)冒泡排序
首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序(即 r[1].key>r[2].key),则交换两个记录,接着比较第二个记录和第三个记录的关键字。依次类推,直至第n-1个记录和第n个记录的关键字进行过比较为止。这个过程称为第一趟冒泡排序,使得关键字最大的记录被安置到最后一个记录的位置上。然后进行第二趟冒泡排序,对前n-1个记录进行同样的操作,结果是使关键字次大的记录被安置到第n-1个记录的位置上。当进行完第n-1趟冒泡排序时,所有记录都已有序排列。
3)简单选择排序
简单选择排序的基本思想是:在进行每趟排序时,从无序的记录中选择出关键字最小(或最大)的记录,将其插入到有序序列(初始时为空)的尾部。
希尔排序
希尔排序又称"缩小增量排序",是对直接插入排序方法的改进。希尔排序的基本思想是:先将整个待排记录序列分割成若干序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
快速排序
快速排序是对冒泡排序的一种改进。先通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,然后分别对这两部分记录继续进行排序,使得整个序列有序。
堆排序
1)堆的概念
对于n个元素的关键字序列{k1,k2,…,kn},当且仅当所有关键字都满足下列关系时称其为堆:
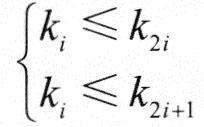
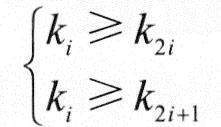
从序列元素间的关系来看,堆是一棵完全二叉树的层次序列。显然,堆顶元素为序列中n个元素的最小值(或最大值)。若堆顶为最小元素,则称为小根堆;若堆顶为最大元素,则称为大根堆。
2)堆排序的基本思想(小根堆)
对一组待排序记录的关键字,首先把它们按堆的定义排成一个堆序列,从而输出堆顶的最小关键字,然后将剩余的关键字再调整成新堆,便得到次小的关键字,如此反复进行,直到全部关键字排成有序序列。
归并排序
归并排序是不断将多个小而有序的序列合成一个大而有序的序列的过程。其中最常用的归并排序是二路归并排序,它是将整个序列中的元素进行分组,相邻的两个元素为一组,然后分别为每个小组进行排序,随后将两个相邻的小组合成一个组,继续进行组内排序;直到所有元素被合并成一个组内,并使组内元素有序,此时排序结束。
基数排序
基数排序的思想是按组成关键字的各个数位的值进行排序,它是分配排序的一种。基数排序把一个关键字Ki看成一个d元组,即
其中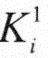
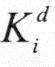
基数排序的基本思想是:设立r个队列(r为基数),队列的编号为0, 1, 2, …,r-1。首先按最低有效位的值,把n个关键字分配到这r个队列中;然后从小到大将各队列中的关键字再依次收集起来;接着再按次低有效位的值把刚收集起来的关键字再分配到r个队列中。重复上述收集过程,直至最高位有效。这样得到了一个从小到大有序的关键字序列。
63. 对数组A=(2,8,7,1,3,5,6,4)用快速排序算法的划分方法进行一趟划分后得到的数组A为(62)(非递减排序, 以最后一个元素为基准元素)。进行一趟划分的计算时间为(63)。
A. O(1)
B. O(Ign)
C. O(n)
D. O(nlgn)
64. 某简单无向连通图G的顶点数为n,则图G最少和最多分别有( )条边。
A. n,n2/2
B. n-1,n*(n-1)/2
C. n,n*(n-1)/2
D. n-1,n2/2
65. 根据渐进分析,表达式序列:n4, lgn, 2n, 1000n, n2/3, n!从低到高排序为( )。
A. Ign,1000n, n2/3, n4, n!, 2n
B. n2/3,1000n, lgn, n4, n!, 2n
C. lgn,1000n, n2/3, 2n, n4, n!
D. Ign, n2/3, 1000n, n4, 2n, n!
1)简单排序
简单排序包括直接插入排序、冒泡排序、简单选择排序等。
2)希尔排序
希尔排序的基本思想是:先将整个待排记录序列分割成若干序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
3)快速排序
快速排序是对冒泡排序的一种改进。先通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,然后分别对这两部分记录继续进行排序,以达到整个序列有序。
4)堆排序
堆排序的基本思想(小根堆)是:对一组待排序记录的关键字,首先把它们按堆的定义排成一个堆序列,从而输出堆顶的最小关键字;然后将剩余的关键字再调整成新堆,便得到次小的关键字,如此反复进行,直到全部关键字排成有序序列。
5)归并排序
归并排序是不断将多个小而有序的序列合成一个大而有序的序列的过程。
6)基数排序
基数排序的思想是按组成关键字的各个数位的值进行排序,它是分配排序的一种。
66. 采用DHCP动态分配IP地址,如果某主机开机后没有得到DHCP服务器的响应。则该主机获取的IP地址属于网络( )。
A. 202.117.0.0/24
B. 192.168.1.0/24
C. 172.16.0.0/16
D. 169.254.0.0/16
(1)A类:网络地址占11B,最高位为0;主机地址占3B。子网掩码为255.0.0.0。
(2)B类:网络地址占2B,最高位为10;主机地址占2B。子网掩码为255.255.0.0。
(3)C类:网络地址占3B,最高位为110;主机地址占1B。子网掩码为255.255.255.0。
(4)D类:用于组播。最高位为1110。
(5)E类:实验保留。最高位为1111。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
67. 在浏览器的地址栏中输入xxxyftp.abc.can.cn,在该URL中( )是要访问的主机名。
A. xxxftp
B. abc
C. can
D. cn
WWW浏览器是用来浏览因特网资源的工具软件。浏览器一般由一组客户、一组解释器和一个管理它们的控制器所组成。现在使用最多的浏览器软件是Microsoft公司的Internet Explorer(IE)和Netscape公司的Communicator。
统一资源定位器(URL)是在WWW中标识某一特定信息资源所在位置的字符串,称为Web地址(网址)。URL通常用来指明所使用的计算机资源位置及查询信息的类型。URL由协议、主机域名、端口号(任选)、目录路径(任选)和一个文件名(任选)组成。例如,某高校网址http://www.xaiu.edu.cn/ index.htm的含义如下图所示。

某高校网址含义
68. 当修改邮件时,客户与POP3服务器之间通过(68)建立连接,所使用的端口是(69)。
A. HTTP
B. TCP
C. UDP
D. HTTPS
邮局协议(Post Office Protocol, POP)第3版是目前使用最广泛的邮件服务。P0P3的功能是邮件的存储和管理,能为用户提供账号、密码和身份验证功能,与SMTP服务配合,提供完整的邮件服务。
在TCP/IP网络中,传输层的所有服务都包含端口号,它们可以唯一区分每个数据包包含哪些应用协议。端口系统利用这种信息来区分包中的数据,尤其是端口号使一个接收端计算机系统能够确定它所收到的IP包类型,并把它交给合适的高层软件。
端口号和设备IP地址的组合通常称作插口(socket)。任何TCP/IP实现所提供的服务都用知名的1~1023之间的端口号。这些知名端口号由Internet号分配机构(Internet Assigned Numbers Authority,IANA)来管理。例如,SMTP所用的TCP端口号是25,POP3所用的TCP端口号是110,DNS所用的UDP端口号为53,WWW服务使用的TCP端口号为80。FTP在客户与服务器的内部建立两条TCP连接,一条是控制连接,端口号为21;另一条是数据连接,端口号为20。
256~1023之间的端口号通常由Unix系统占用,以提供一些特定的UNIX服务。也就是说,提供一些只有UNIX系统才有的、其他操作系统可能不提供的服务。
在实际应用中,用户可以改变服务器上各种服务的保留端口号,但要注意,在需要服务的客户端也要改为同一端口号。
69. 当修改邮件时,客户与POP3服务器之间通过(68)建立连接,所使用的端口是(69)。
A. 52
B. 25
C. 1100
D. 110
70. 因特网中的域名系统(Domain Name System)是一个分层的域名,在根域下面是顶级域,以下顶级域中,( )属于国家顶级域。
A. NET
B. EDU
C. COM
D. UK
一个完整、通用的层次型主机域名由4部分组成,即计算机主机名.本机名.组名.最高层域名。
域表示一个区域或者范围。域内可以容纳许多主机,因此并非每一台接入因特网的主机都必须具有一个域名地址,但是每一台主机都必须属于某个域,即通过该域的服务器可以查询和访问到这台主机。通常,该域服务器称为域名服务器(DNS)。对应因特网的层次结构,域采用嵌套结构与之对应。域名地址由一系列"子域名"组成,子域名的个数通常不超过5个,并且子域名之间用句点"."分隔,从左到右子域的级别升高,高一级的子域包含低一级的子域。这种嵌套的域名结构形成一棵域名树,树中的子节点和树叶标识分别表示不同的域,树叶被其上级的子节点或者树根所包含。这种域名结构也十分类似常用的通信地址(仅和我国表示地址的顺序有所不同),符合人类表达的习惯。
因特网域名的取值遵守一定的规则。第一级域名通常分配给主干网节点,取值为国家名;第二级域名对应为次级节点,通常表示组网的部门或组织。二级域以下的域名由组网部门分配和管理。
71. Regardless of how well designed, constructed, and tested a system or application may be, errors or bugs will inevitably occur. Once a system has been(71),it enters operations and support.
Systems support is the ongoing technical support for user, as well as the maintenance required to fix any errors, omissions,or new requirements that may arise. Before an information system can be(72), it must be in operation. System operation is the day-to-day, week-to-week, month-to-month, and year-t-year(73)of an information system's business processes and application programs.
Unlike systems analysis, design, and implementation, systems support cannot sensibly be(74)into actual phases that a support project must perform. Rather, systems support consists of four ongoing activities that are program maintenance, system recovery, technical support, and system enhancement.Each activity is a type of support project that is(75)by a particular problem,event, or opportunity encountered with the implemented system.
A. designed
B. implemented
C. investigated
D. analyzed
72. Regardless of how well designed, constructed, and tested a system or application may be, errors or bugs will inevitably occur. Once a system has been(71),it enters operations and support.
Systems support is the ongoing technical support for user, as well as the maintenance required to fix any errors, omissions,or new requirements that may arise. Before an information system can be(72), it must be in operation. System operation is the day-to-day, week-to-week, month-to-month, and year-t-year(73)of an information system's business processes and application programs.
Unlike systems analysis, design, and implementation, systems support cannot sensibly be(74)into actual phases that a support project must perform. Rather, systems support consists of four ongoing activities that are program maintenance, system recovery, technical support, and system enhancement.Each activity is a type of support project that is(75)by a particular problem,event, or opportunity encountered with the implemented system.
A. supported
B. tested
C. implemented
D. constructed
73. Regardless of how well designed, constructed, and tested a system or application may be, errors or bugs will inevitably occur. Once a system has been(71),it enters operations and support.
Systems support is the ongoing technical support for user, as well as the maintenance required to fix any errors, omissions,or new requirements that may arise. Before an information system can be(72), it must be in operation. System operation is the day-to-day, week-to-week, month-to-month, and year-t-year(73)of an information system's business processes and application programs.
Unlike systems analysis, design, and implementation, systems support cannot sensibly be(74)into actual phases that a support project must perform. Rather, systems support consists of four ongoing activities that are program maintenance, system recovery, technical support, and system enhancement.Each activity is a type of support project that is(75)by a particular problem,event, or opportunity encountered with the implemented system.
A. construction
B. maintenance
C. execution
D. implementation
74. Regardless of how well designed, constructed, and tested a system or application may be, errors or bugs will inevitably occur. Once a system has been(71),it enters operations and support.
Systems support is the ongoing technical support for user, as well as the maintenance required to fix any errors, omissions,or new requirements that may arise. Before an information system can be(72), it must be in operation. System operation is the day-to-day, week-to-week, month-to-month, and year-t-year(73)of an information system's business processes and application programs.
Unlike systems analysis, design, and implementation, systems support cannot sensibly be(74)into actual phases that a support project must perform. Rather, systems support consists of four ongoing activities that are program maintenance, system recovery, technical support, and system enhancement.Each activity is a type of support project that is(75)by a particular problem,event, or opportunity encountered with the implemented system.
A. broke
B. formed
C. composed
D. decomposed
75. Regardless of how well designed, constructed, and tested a system or application may be, errors or bugs will inevitably occur. Once a system has been(71),it enters operations and support.
Systems support is the ongoing technical support for user, as well as the maintenance required to fix any errors, omissions,or new requirements that may arise. Before an information system can be(72), it must be in operation. System operation is the day-to-day, week-to-week, month-to-month, and year-t-year(73)of an information system's business processes and application programs.
Unlike systems analysis, design, and implementation, systems support cannot sensibly be(74)into actual phases that a support project must perform. Rather, systems support consists of four ongoing activities that are program maintenance, system recovery, technical support, and system enhancement.Each activity is a type of support project that is(75)by a particular problem,event, or opportunity encountered with the implemented system.
A. triggered
B. leaded
C. caused
D. produced
获取标准答案和详细的答案解析请阅读全文