1. 关系型数据库采用( )解决数据并发引起的冲突。
A. 锁机制
B. 表索引
C. 分区表
D. 读写分离
对高级语言源程序进行编译或解释的过程可以分为多个阶段,解释方式不包含(6)。
在基于Web的电子商务应用中,访问存储于数据库中的业务对象的常用方式之一是( )。
算术表达式a+(b-c)*d的后缀式是(10) (-、+、*表示算术的减、加、乘运算,运算符的优先级和结合性遵循惯例)。
数据库(DataBase,DB)是指长期存储在计算机内的、有组织的、可共享的数据集合。数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
系统使用的所有数据存储在一个或几个数据库中。
2. 把模块按照系统设计说明书的要求组合起来进行测试,属于( )。
A. 单元测试
B. 集成测试
C. 确认测试
D. 系统测试
使用白盒测试时,确定测试数据应根据( )指定覆盖准则。
使用白盒测试方法时,应根据(4)和指定的覆盖标准确定测试数据。
以下关于CMM的叙述中,不正确的是( )。
测试工作伴随着整个网络工程的全过程,无论是布线安装还是系统调试,都需要进行反复的测试和确定。
测试计划
测试计划应包括下列5个方面的内容。
1)简要说明
简要说明包括工程的概况和需要达到的主要指标。
2)测试内容
测试内容包括逐项列出的测试步骤、名称、内容和预期达到的目标。
3)测试清单
测试清单是对每项测试内容列出测试的部位和参与测试的单位,包括进度的安排、测试工具和相应的条件(设备和软件等)。
4)测试设计说明
测试设计说明是对每项测试内容的测试设计进行考虑,包括测试的控制方式、输入条件和预期的输出结果。
5)评价准则
评价准则用来说明测试所能检查的范围及其局限性,以及用来判断测试工作是否通过的评价尺度,包括合理的输出结果、测试输出结果与预期输出结果之间容许出现的偏差范围。
测试工作完成后,应提交一份测试分析报告。该报告主要包括下列内容:概要说明、测试结果、结论、原因分析、建议和评价。
网络测试
网络测试是对网络设备、网络系统以及网络对应用的支持进行检测,以展示和证明网络系统能否满足用户在性能、安全性、易用性、可管理性等方面需求的测试。网络测试的实施一般包括以下环节。
◆根据测试目的,确定测试目标。
◆在对相关网络技术和实现细节透彻掌握的基础上,设计测试方案。
◆建立网络负载模型。
◆配置测试环境,包括测试工具的选择及必要的测试工具的研发。
◆采集和整理数据。
◆分析和解释数据。
◆准确、直观、形象地表示测试结果。
网络测试包括网络设备测试、网络系统测试和网络应用测试3个层次。
1)网络设备测试
网络设备测试主要包括以下几个方面:功能测试、可靠性和稳定性测试、一致性测试、互操作性测试和性能测试等。
(1)功能测试用来验证产品是否具有设计的每一项功能。
(2)可靠性和稳定性测试往往通过加重负载的办法来分析和评估系统的可靠性和稳定性。
(3)一致性测试用来验证产品的各项功能是否符合标准。
(4)互操作性测试用来考查一个网络产品是否能在不同厂家的多种网络产品互联的网络环境中很好地工作。网络产品不同于其他产品的最大特点是必须符合标准,不同的网络产品之间要能互操作。
(5)性能测试的主要目标是分析产品在各种不同的配置和负载条件下的容量和对负载的处理能力,如交换机的吞吐量、转发延迟等。
典型的网络设备性能测试方法有两种:第一种是将设备放在一个仿真的网络环境中进行测试,第二种是使用专用的网络测试设备对产品进行测试。
2)网络系统测试和网络应用测试
网络系统测试除了普通意义上的物理连通性、基本功能和一致性的测试以外,主要包括网络系统的规划验证测试、网络系统的性能测试、网络系统的可靠性与可用性的测试与评估、网络流量的测量和模型化等。
(1)网络系统的规划验证测试主要采用的两个基本手段是模拟和仿真。
◆模拟是通过软件的办法,建立网络系统的模型,模拟实际网络的运行。通过设定各种配置和参数模拟系统的行为,对系统的容量、性能以及对应用的支撑程度给出定量的评价。这对于大型网络的规划设计是不可缺少的环节。
◆仿真是指通过建立典型的试验环境,仿真实际的网络系统。规划验证测试的目的在于分析所采用的网络技术的可行性和合理性,网络设计方案的合理性,所选网络设备的功能、性能等是否能够合理地、有效地支持网络系统的设计目标。
(2)网络系统的性能测试是指通过对网络系统的被动测量和主动测量来确定系统中站点的可达性、网络系统的吞吐量、传输速率、带宽利用率、丢包率、服务器和网络设备的响应时间、产生最大网络流量的应用和用户,以及服务质量等。此项工作同时可以发现系统的物理连接和系统配置中的问题,确定网络瓶颈,发现网络问题。测试设备记录一段时间内的网络流量,实时和非实时地分析数据。被动测量不干涉网络的正常工作,不影响网络的性能。主动测量向网络发送特定类型的数据包或网络应用,以便分析系统的行为。
(3)网络系统的可靠性与可用性的测试与评估。系统可用性取决于系统的可靠性(MTTF)及可维护性(MTTR)的高低,其中可靠性是指系统服务多久不中断,可维护性是指服务中断后多久可恢复。三者之间满足如下关系:
System Usability=MTTF/(MTTF+MTTR)*100%
其中,MTTF是指平均无故障时间,MTTR是指平均故障修复时间,MTBF是指平均故障间隔时间。有MTBF=MTTF+MTTR,故
System Usability=MTTF/MTBR*100%
(4)网络流量的测量和模型化。网络流量的测量和模型化对于分析网络性能和带宽的利用率、指导网络流量管理、开发高效的网络应用十分重要。这方面的工作主要有以下几个方面。
◆产生已知特征的流量,使该流量沿网络传播,最后回到测试仪。记录和分析流量特性的任何改变(如延迟漂移)。
◆对链路总体流量的测量和传输时间、吞吐量、带宽利用率等进行分析。
◆分析特定流量的特征和提供的QoS;收集一个时间段内的测量数据进行分析,分析流量沿网络传播过程中流量特征的变化和网络流量的统计行为,建立流量模型。
(5)网络应用层次上的测试则主要体现在测试网络对应用的支持水平,如网络应用的性能和服务质量的测试等。例如,部署基于IP的语音传输VoIP时,最直接的问题是网络中的交换机和路由器设备能否有效地支持语音传输,网络能支持多大的语音流量、多少个语音通道;如果网络支持VoIP,对网络的其他业务特别是关键业务,会产生什么样的影响;网络是否支持服务质量QoS。这些问题都需要通过网络应用测试来回答。
(6)网络系统测试的核心工具是协议分析仪。这是一种专用的网络测试设备,它能够连接到网络上,产生并向网络发送数据,捕捉网络数据,分析数据。协议分析仪一般具有网络监测、故障查找、协议解码和流量产生等功能。
网络设备安全性测试
现在有很多新型网络设备尤其是网络边缘路由器增加了防护功能,阻止了人为、故意的网络攻击。然而,提供的防护会不会对正常数据转发造成影响?有什么样的影响?这些很难从理论上估计,需要进行必要的网络设备安全性测试。
本节提到的测试项,主要是验证网络设备所提供的基本安全功能,并检测这些安全功能项对网络设备运行造成的影响。这些测试项分为访问列表测试和DOS攻击测试两大类。
1)访问列表测试
访问列表测试用于检测边缘路由器的访问列表能否起到防火墙的作用,访问列表测试控制网络传输过滤数据报文,访问列表测试阻止或允许数据报文通过网络接口。过滤依据可以是源地址、目的地址和上层协议号。边缘路由器通过将进入或离开的数据报文与访问列表中的过滤项进行比较,决定允许或阻止数据报文通过。对于边缘路由器能提供的访问列表容量,以及不断变化的访问列表对数据转发的影响都要进行测试。
2)DOS攻击测试
DOS攻击测试用于检测边缘路由设备抵抗"拒绝服务(DOS)攻击"的能力。当设备由于伪造的服务请求和虚假的传输而变得非常繁忙时,就无法响应正常的服务请求,从而造成损失。DOS攻击测试考验网络设备检测并阻止某种特定攻击的能力,并在检测受到某种攻击、设备超负荷运行的情况下,正常传输转发性能所受的影响。
具体的网络设备安全性测试项目如下。
◆访问列表性能测试。
◆虚假源地址攻击测试。
◆LAND攻击检查。
◆SYN风暴检查。
◆Smurf攻击检查。
◆Ping风暴检查。
◆Teardrop攻击检查。
◆Ping to Death检查。
性能测试
性能测试包括可靠性测试、功能/特性测试、吞吐量测试、衰减测试、容量规划测试、响应时间测试、可接受性测试和网络瓶颈测试等。
1)可靠性测试
可靠性测试是使被测网络在较长时间内(通常是24~72小时)经受较大负载,通过监视网络中发生的错误和出现的故障,验证在高强度环境中网络系统的存活能力,也就是它的可靠性。可靠性测试可作为接受性测试的一部分,在产品评估测试中可作为比较测试或作为产品升级进行的衰减测试的一部分。采用的负载模式很重要,越贴近真实负载模式越好。可靠性测试中使用网络分析仪监控网络运行,捕获网络错误。
通常在较长时间段内和持续负载下,不同网络具有不同级别的存活度。如果测试时间足够长、负载足够大,所有可靠性测试最终都会失败。
可靠性测试应用于网络生命周期中的以下3个阶段。
◆计划:作为产品评估测试的一部分,比较不同产品或建立要求规范。
◆开发:验证计划中的要求是否能在系统中完全实现。
◆组建:作为可接受性测试的一部分,在网络运行前进行,核实系统是否达到要求。
2)功能/特性测试
特性测试核实的是单个命令和应用程序功能,通常用较小的负载完成,关注的是用户界面、应用程序的操作以及用户与计算机之间的互操作。特性测试通常由开发人员在他们的工作台上完成,或是在一个小型网络环境下由测试人员完成。
功能测试是面向网络的,核实的是应用程序的多用户特征和在重负载下后台功能是否能正确地执行,关注的是当多个用户正在运行应用程序时,网络和文件系统或数据库服务器之间的交互。功能测试要求网络的配置和负载非常接近于运行环境下的模式。该测试可以在运行网络或独立网络实验室里完成。它只应用于网络生命周期中的以下3个阶段。
◆开发:用于核实在期望的运行模式下,在多用户环境里,应用程序的运行性能是否达到要求。
◆组建:在应用程序安装前完成,可独立进行,也可作为接受性测试的一部分,用于核实在期望的运行模式下,应用程序的运行性能是否达到要求。
◆运行:该阶段测试是在应用程序运行后进行的,如果在运行系统中遇到了问题,该阶段测试用于核实应用程序是否如最初应用时那样工作。
3)吞吐量测试
吞吐量测试和应用程序的响应时间测试相似,但检测的是每秒钟传输数据的字节数和数据报文数,而不是响应时间。它用于检测服务器、磁盘子系统、适配卡/驱动连接、网桥、路由器、集线器、交换器和通信连接。吞吐量测试用于测量网络性能、找到网络瓶颈,以及比较不同产品的性能。
吞吐量测试不使用程序脚本,它借助某些软件对网络服务器执行文件输入/输出操作来产生流量,或通过某些软件在网络上发送专门的数据报文或帧。该测试应用于网络生命周期的以下几个阶段。
◆计划:用于比较网络产品,为模拟网络节点提供运行特征和要求规范。
◆开发:用于核实网络组件以及整个网络是否达到规范要求的水平。
◆组建:可独立进行或作为可接受性测试的一部分,在网络组件或整个网络正式运行之前核实它们是否满足规范的要求。
4)衰减测试
衰减测试是将硬件或软件的新版本与当前版本在性能、可靠性和功能等方面进行比较,同时验证产品升级对网络的性能不会有不良影响。衰减测试混杂了很多为完成其他测试任务要进行的测试。衰减测试的关键是要保证被测组件应是运行网络中最关键或最脆弱的组件。
衰减测试不强调升级版的新特性。新特性测试在衰减测试之前作为功能/特征测试的一部分就已完成。尽管新产品应该解决了当前版本中的错误,但它们也经常存在一些以前没有出现过的错误,如果这些错误发生在产品的关键部分,将会引起严重问题。衰减测试不需要测试产品的所有特性,但网络用户正常运行所依靠的关键功能必须在测试之列。
衰减测试应用于网络生命周期的以下两个阶段。
◆开发:用于核实产品升级版是否能满足性能、互操作性和可靠性的要求。
◆升级:在采用升级版本之前用该项测试来比较升级版和当前版,看升级版是否和当前版一样满足性能、互操作性和可靠性的要求。
5)容量规划测试
容量规划测试用于检测当前网络中是否存在多余的容量空间。当网络承受的总负载超过网络总容量时,网络的性能或吞吐量就有可能下降,所以在网络负载接近这一临界点(网络的最大容量)前,就要根据负载增长的幅度扩充网络资源。
进行该项测试要逐渐增加网络负载,直到网络的运行性能、可接受的水平或吞吐量不断下降,达不到设计所要求的水平为止。网络运行负载和网络最大吞吐量之间的差额就是现有系统的冗余量。
容量规划测试应用于网络生命周期的以下3个阶段。
◆计划:用于估计实施该系统所需要的资源,也可用于成本分析和制定预算。
◆开发:检测系统要求的资源是否满足特定的响应时间和吞吐量的要求。
◆升级:当系统响应时间或吞吐量下降时,重新选取网络组件。
6)响应时间测试
响应时间测试用于检测系统完成一系列任务所需的时间,本项测试是用户最关心的。对于表示层,如微软的Windows,该测试是指在不同桌面之间切换或装载新负载所需的时间。在不同负载即不同实际或模拟用户的数目下运行这一实验,可对每个被测试的应用程序生成一个负载—响应时间曲线。
在应用程序测试中,可执行一系列典型网络动作的命令,如打开、读、写、查找和关闭文件,这些命令提供了最好的负载模拟。例如,对每个进行测试的工作站,检测它在几秒内能完成这些命令。
响应时间测试应用于网络生命周期的以下几个阶段。
◆计划:使用模拟应用程序进行,检测规范要求的各项网络服务。
◆开发:检验规范要求的网络服务是否正在被实现。
◆组建:在接受和组建之前,核实规范要求下的网络服务是否已经被实现。
◆运行:检测网络服务的基准和变化,这可能是针对系统质量的最好测试。
响应时间测试应该包括对系统可靠性的检测。常见的可靠性问题,如在路由器或服务器中大量丢失数据报文或由于网络组件故障引发大量坏数据报文,将严重影响网络的响应时间,因此在整个测试期间都应用网络分析仪监视系统错误。
7)可接受性测试
可接受性测试是在系统正式实施前的"试运行"。它是一个非常有效的方法,可确保新系统能提供良好而稳定的性能。和衰减测试一样,可接受性测试中也包含多项测试,如响应时间测试、稳定性测试和功能/特性测试。
可接受性测试应用于许多领域,但在安装或升级网络前应进行的网络可接受性测试则经常被忽略,而事实上,可接受性测试能为网络购买者在经济和技术上提供有力的保证和参考。
可接受性测试可以仅在新增加的部件上完成,将已存在的负载加上新增程序或新增组件可能产生的负载作为测试使用的负载。
可接受性测试应用于网络生命周期的以下两个阶段。
◆开发:在开发阶段前定期执行,用来核实要求的标准是否可行。
◆组建:在网络投入运行之前应用,用来核实系统是否满足所有要求。
8)网络瓶颈测试
通过网络瓶颈测试可以找到导致系统性能下降的瓶颈。测试中需要测试和计算系统的最大吞吐量,然后再在单个网络组件上进行该项测试,明确各组件的最大吞吐量。通过计算单个组件的最大吞吐量和系统最大吞吐量之间的差额,就能发现系统瓶颈的位置以及哪些组件有多余的容量。
系统瓶颈在不同的测试案例中出现的位置可能有所变化。例如,一个客户业务应用程序测试可能表明服务器是系统的瓶颈,而对一个电子邮件系统的测试则可能表明广域网连接才是网络的限制因素。如果可以在测试的环境中重现引起问题的负载,那么这样的测试结果对解决问题将有很大帮助。
瓶颈测试应用于网络生命周期的以下两个阶段。
◆组建:可以作为容量计划的一部分,用于帮助相关人员明确影响网络性能和响应时间的瓶颈位置。
◆运行:作为故障检测的一部分,帮助相关人员找出影响网络性能或引起系统问题的网络瓶颈。
测试报告
测试报告是整个项目的第一份供大家交流和供领导查阅的报告,人们对工程的满意程度和对工程质量的认可很大程度上来源于这份报告。通常在独立网络测试后,要总结测试数据,并基于此对测试过的同类产品进行排序;而系统内部的测试仅是得出一个简单的结论。
测试报告呈现的内容和采取的表现形式非常重要,测试报告通常包含以下信息。
◆测试目的:用一句或两句话解释本次测试的目的。
◆结论:从测试中得到的信息推荐下一步的行动。
◆测试结果总结:对测试进行总结并由此得出结论。
◆测试内容和方法:简单地描述测试是怎样进行的,应该包括负载模式、测试脚本和数据收集方法,并且要解释采取的测试方法怎样保证测试结果和测试目的的相关性,以及测试结果是否可重现。
◆测试配置:网络测试配置用图形表示出来。
测试报告的形式可以是一个简短的总结(2~4页),也可以是一个很长的书面文档(5~20页)。测试总结可以使用图形表示测试结果,如应用程序的响应时间、吞吐量和产品评估。而系统衰减性测试、配置规模测试和应用程序的功能/特性测试的测试报告还要包括更多的信息。
在非常特殊的情况下,测试报告需要长达50页。它通常包括从项目开始到结束按时间编排的所有活动,以及非常详细的问题信息和解决问题的信息。
网络测试工具
网络测试工具一般包括以下几个。
◆网络管理和监控工具。
◆建模和仿真工具。
◆服务质量和服务级别管理工具。
网络管理和监控工具(如HP公司的OpenView)能够在网络测试运行过程中提示某些问题的网络事件的出现。这些工具可以是驻留在网络设备中的应用软件。
协议分析仪也能被用于监测新设计的网络,帮助分析通信的行为、差错、利用率、效率以及广播和多播分组。
建模工具和仿真工具是更为先进的用来测试验证网络设计的工具。仿真就是在不建立实际网络的情况下,使用软件和数学模型来分析网络行为的过程。利用仿真工具,可以根据所需要测试的目标开发一个网络模型,从而估计网络性能,并对各种网络实现方法之间的差异进行比较。仿真工具使得选择比较的空间变得更大,特别适合于实现和检查一个扩展的原型系统。一个好的仿真工具往往非常昂贵,实现的技术也比较复杂,它要求开发人员不但要精通统计分析和建模技术,而且还要对计算机网络有所了解。
服务级别管理工具是一种比较新型的工具,主要用来分析网络应用的端到端性能。有些工具能够管理服务质量和服务级别,有些工具能够监控实时应用的性能,有些工具能够预测新的应用性能,有些工具可以将上述功能结合起来实现更强大的功能。
A. 主存.辅存
B. 寄存器.Cache
C. 寄存器.主存
D. Cache.主存
计算机上采用的SSD(固态硬盘)实质上是( )存储器。
虚拟存储体系是由(2)两级存储器构成。
计算机中CPU对其访问速度最快的是 (2) 。
存储器是计算机的一个重要组成部分,它用来保存计算机工作所必需的程序和数据。正因为有了存储器,计算机才有信息记忆功能。
分类
1)按在计算机中的作用分类
按在计算机中的作用可分为内部存储器、外部存储器和缓冲存储器。
(1)内部存储器简称内存或主存。内存是主机的一个组成部分,它用来容纳当前正在使用的,或者经常要使用的程序或数据,CPU可以直接从内部存储器取指令或存取数据。
(2)外部存储器简称外存或辅存。外存也是用来存储各种信息的,但是CPU要使用这些信息时,必须通过专门的设备将信息先传送到内存中,因此外存存放相对来说不经常使用的程序和数据。另外,外存总是和某个外部设备相关的。
(3)缓冲存储器用于两个工作速度不同的部件之间,在交换信息过程中起缓冲作用。
2)按存储介质分类
按存储介质可分为半导体存储器、磁表面存储器和光电存储器。
3)按存取方式分类
按存取方式可分为随机存储器(RAM)、只读存储器(ROM)和串行访问存储器。
(1)随机存储器(Random Access Memory, RAM)又称为读写存储器,是指通过指令可以随机地、个别地对各个存储单元进行访问。它是易失性存储器,这种存储器一旦去掉其电源,则所保存的信息全部丢失。
(2)只读存储器(Read Only Memory, ROM)是一种对其内容只能读不能写入的存储器。它属于非易失性存储器,当去掉其电源后,所保存的信息仍保持不变。
(3)串行访问存储器(Serial Access Storage, SAS)是指对存储器的信息进行读写时,需要顺序地访问。
主存储器
1)主存储器的种类
主存储器一般由半导体随机存储器(RAM)和只读存储器(ROM)组成,其绝大部分由RAM组成。按所用元件类型来分有双极性和MOS存储器两类。前者存取速度比后者高,但集成度不如后者,价格也高,主要用于小容量存储器,后者主要用于大容量存储器。MOS存储器按存储元件在运行中能否长时间保存信息来分,有静态存储器(SRAM)和动态存储器(DRAM)两种。前者只要不断电,信息就不会丢失,而后者需要不断给电容充电才能使信息保持。由于后者密度大且较便宜,故使用较多。
2)主存储器的主要技术指标
衡量一个主存储器的性能指标主要为主存容量、可直接寻址空间、存储器存取时间、存储周期时间和带宽等。
(1)主存容量是指每个存储芯片所能存储的二进制的位数,也就是存储单元数乘以数据线位数。
(2)可直接寻址空间是由地址线位数确定的。例如,提供32位物理地址的计算机支持对4(232)GB的物理主存空间的访问。
(3)存储器存取时间又称为存储器访问时间,是指从启动一次存储器操作到完成该操作所经历的时间。
(4)存储周期时间是指连续启动两次独立的存储器操作所需间隔的最小时间。
(5)带宽是指存储器的数据传送率,即每秒传送的数据位数。
3)主存储器的构成
主存储器一般由地址寄存器、数据寄存器、存储矩阵、译码电路和控制电路组成。
(1)地址寄存器(MAR)用来存放由地址总线提供的将要访问的存储单元的地址码。
(2)数据寄存器(MDR)用来存放要写入存储矩阵或从存取矩阵中读取的数据。
(3)存储矩阵用来存放程序和数据的存储单元排成的矩阵。
(4)译码电路根据存放在地址寄存器中的地址码,在存储体中找到相应的存储单元。
(5)控制电路根据读写命令控制主存储器的各部分协作完成相应的操作。
4)主存储器的基本操作
要从存储器中取一个信息字,CPU必须指定存储器字地址,并进行"读"操作。CPU把信息字的地址送到MAR,经地址总线送往主存储器,同时CPU应用控制线发一个"读"请求。此后,CPU等待从主存储器发回来的回答信号,通知CPU"读"操作完成,说明存储字内容已经读出并放在数据总线上送入MDR。
为了存一个字到主存,CPU先将信息字在主存中的地址经MAR送到地址总线,并将信息字送到MDR,同时CPU发出"写"命令。此后,CPU等待从主存储器发回来的回答信号,通知CPU"写"操作完成,说明主存从数据总线接收到信息字并按地址总线指定的地址存储。
外存储器
外存储器的特点是容量大、价格低,但是存取速度慢,用于存放暂时不用的程序和数据。外存储器主要有磁盘存储器、磁带存储器和光盘存储器。磁盘是最常用的外存储器,通常分软磁盘和硬磁盘两类。目前,常用的外存储器有软盘、硬盘和光盘存储器。它们和内存一样,存储容量也是以字节为基本单位的。
1)软磁盘存储器
软磁盘是用柔软的聚酯材料制成圆形底片,在两个表面涂有磁性材料。目前,常用软盘的直径为3.5英寸。软磁盘安装在硬塑胶盒中,而且没有裸露部分,因此使盘片得到了更好的保护,信息在磁盘上是按磁道和扇区的形式来存放的。磁道即磁盘上的一组同心圆的信息记录区,它们由外向内编号,一般为0~79道。每条磁道被划成相等的区域,称为扇区。一般每磁道有9、15或18个扇区。每个扇区的容量为512B。一个软盘的存储容量可由下面的公式算出,即
软盘总容量=磁道数×扇区数×扇区字节数(512B)×磁盘面数(2)
例如,3.5英寸软盘有80个磁道,每条磁道18个扇区,每个扇区512B,共有两面,则其存储容量的计算公式为:
软盘容量=80×18×512×2=1 474 560B=1.44MB
扇区是软盘(或硬盘)的基本存储单元,每个扇区记录一个数据块,数据块中的数据按顺序存取。扇区也是磁盘操作的最小可寻址单位,与内存进行信息交换是以扇区为单位进行的。
在进行写入操作时,写保护开关先要对磁盘是否有写保护缺口进行检索,如果检测到有写保护缺口,则允许进行写操作;如果没有或被胶纸黏封,则不能进行写操作。
使用软磁盘应注意防磁、防潮、防污(灰尘和手摸)、防丢信息(写保护和勤复制)和防病毒(常加写保护,不使用来历不明的软磁盘)。
2)硬磁盘存储器
硬磁盘是由涂有磁性材料的铝合金圆盘组成的。目前常用的硬盘是3.5英寸的,这些硬盘通常采用温彻斯特技术,即把磁头、盘片及执行机构都密封在一个整体内,与外界隔绝,所以这种硬盘也称为温彻斯特盘。
硬盘的两个主要性能指标是硬盘的平均寻道时间和内部传输速率。一般来说,转速越高的硬盘寻道的时间越短,而且内部传输速率也越高,不过内部传输速率还受硬盘控制器Cache的影响。目前,市场上硬盘常见的转速有5400r/min、7200r/min,最快的平均寻道时间为8ms,内部传输速率最高为190MB/s。硬盘的每个存储表面被划分成若干个磁道(不同硬盘磁道数不同),每个磁道被划分成若干个扇区(不同的硬盘扇区数不同)。每个存储表面的同一道形成一个圆柱面,称为柱面。柱面是硬盘的一个常用指标。
硬盘的存储容量计算公式为
存储容量=记录面面数×每面磁道数×每扇区字节数×扇区数
例如,某硬盘有记录面15个,磁道数(柱面数)8894个,每道63扇区,每扇区512B,则其存储容量为
15×8894×512×63=4.3GB
使用硬盘应注意避免频繁开关机器电源,应使其处于正常的温度和湿度、无振动、电源稳定的良好环境。
3)光盘存储器
光盘指的是利用光学方式进行信息存储的圆盘。人们把采用非磁性介质进行光存储的技术称为第一代光存储技术,其缺点是不能像磁记录介质那样把内容抹掉后重新写入新的内容。把采用磁性介质进行光存储的技术称为第二代光学存储技术,其主要特点是可擦写。
光盘存储器可分成CD-ROM、CD-R和可擦除型光盘。
CD-ROM(Compact Disc-Read Only Memory),是只读型光盘,这种光盘的盘片是由生产厂家预先将数据或程序写入,出厂后用户只能读取,而不能写入或修改。CD-R(CD-Recordable),即一次性可写入光盘,但必须在专用的光盘刻录机中进行。可擦除型光盘可多次写入。
高速缓冲存储器
计算机的主-辅存层次解决了存储器的大容量和低成本之间的矛盾,但是在速度方面,计算机的主存和CPU一直有很大的差距,这个差距限制了CPU速度潜力的发挥。为了弥合这个差距,设置高速缓冲存储器(Cache)是解决存取速度的重要方法。就是在主存和CPU之间设置一个高速的容量相对较小的存储器,如果当前正在执行的程序和数据存放在这个存储器中,当程序运行时不必从主存取指令和数据,所以提高了程序的运行速度。它具有以下特点。
(1)位于CPU与主存之间。
(2)容量小,一般在几千字节到几兆字节之间。
(3)速度一般比主存快5~10倍,由快速半导体存储器制成。
虚拟存储器
主存的特点是速度快但容量小,CPU可直接访问。外存的特点是容量大和速度慢,CPU不能直接访问。用户的程序和数据通常放在外存中,因此需要经常在主存与外存之间取来送去,由用户来干预调度很不方便。虚拟存储器用来解决这个矛盾,使用户感到他可以直接访问整个内、外存空间,而不需用户干预。因此容量很大的速度较快的外存储器(硬磁盘)成为虚拟存储器主要组成部分。用户程序采用虚地址访问整个虚拟空间,而指令执行时只能访问主存空间。因此,必须进行虚实地址转换,把不在主存的单元内容调入主存某单元,再按转换的实地址进行访问。
计算机中,用于存放程序或数据的存储部件有CPU内部寄存器、高速缓冲存储器(Cache)、主存储器(内存储器、内存)和辅存(外存储器、外存)。它们的存取速度不一样,从快到慢依次为寄存器→Cache→内存→辅存。一般来讲,速度越快,成本就会越高。因为成本高,所以容量就会越小。严格来说,CPU内部寄存器不算存储系统。因此,在计算机的存储系统体系中,Cache是访问速度最快的设备。
主存储器
内存采用的是随机存取方式,因此简称为RAM。如果计算机断电,则RAM中的信息会丢失。内存需对每个数据块进行编码,即每个单元有一个地址,这就是所谓的内存编址问题。内存一般按照字节编址或按照字编址,通常采用的是十六进制表示。例如,假设某内存储器按字节编址,地址从A4000H到CBFFFH,则表示该存储器有(CBFFFA4000)+1个字节(28 000H字节),也就是163 840个字节(160KB)。
编址的基础可以是字节,也可以是字(字是由一个或多个字节组成的),要算地址位数,首先应计算要编址的字或字节数,然后对其求2的对数即可得到。例如,上述内存的容量为160KB,则需要18位地址来表示(217=131 072,218=262 144)。
内存这个知识点的另外一个问题就是求存储芯片的组成问题。实际的存储器总是由一片或多片存储器配以控制电路构成。其容量为W×B,W是存储单元的数量,B表示每个单元由多少位组成。如果某一芯片规格为w×b,则组成W×B的存储器需要用(W/w)×(B/b)块芯片。例如,上述例子中的存储器容量为160KB,若用存储容量为32K×8b的存储芯片构成,因为1B=8b(一个字节由8位组成),则至少需要(160K/32K)×(1B/8)=5块。
高速缓冲存储器
Cache的功能是提高CPU数据输入输出的速率,突破所谓的“冯·诺依曼瓶颈”,即CPU与存储系统间数据传送带宽限制。高速存储器能以极高的速率进行数据的访问,但因其价格高昂,如果计算机的内存完全由这种高速存储器组成,则会大大增加计算机的成本。因此通常在CPU和内存之间设置小容量的高速存储器Cache。Cache容量小但速度快,内存速度较低但容量大,通过优化调度算法,系统的性能会大大改善,就如同其存储系统容量与内存相当而访问速度近似于Cache。
使用Cache改善系统性能的依据是程序的局部性原理。依据局部性原理,把内存中访问概率高的内容存放在Cache中,当CPU需要读取数据时就首先在Cache中查找是否有所需内容。如果有,则直接从Cache中读取;若没有,再从内存中读取该数据,然后同时送往CPU和Cache。如果CPU需要访问的内容大多都能在Cache中找到(称为访问命中),则可以大大提高系统性能。
如果以h代表对Cache的访问命中率(“1-h”称为失效率,或者称为未命中率),t1表示Cache的周期时间,t2表示内存的周期时间,在读操作中使用“Cache+主存储器”的系统的平均周期为t3。则:
t3=t1×h+t2×(1-h)
系统的平均存储周期与命中率有很密切的关系,命中率的提高即使很小也能导致性能上的较大改善。
当CPU发出访存请求后,存储器地址先被送到Cache控制器以确定所需数据是否已在Cache中,若命中则直接对Cache进行访问。这个过程称为Cache的地址映射。常见的映射方法有直接映射、相联映射和组相联映射。
当Cache产生了一次访问未命中之后,相应的数据应同时读入CPU和Cache。但是当Cache已存满数据后,新数据必须淘汰Cache中的某些旧数据。最常用的淘汰算法有随机淘汰法、先进先出淘汰法(FIFO)和近期最少使用淘汰法(LRU)。
因为需要保证缓存在Cache中的数据与内存中的内容一致,相对于读操作而言,Cache的写操作比较复杂,常用的有以下几种方法。
(1)写直达(Write Through)。当要写Cache时,数据同时写回内存,有时也称为写通。
(2)写回(Write Back)。CPU修改Cache的某一行后,相应的数据并不立即写入内存单元,而是当该行从Cache中被淘汰时才把数据写回到内存中。
(3)标记法。对Cache中的每一个数据设置一个有效位,当数据进入Cache后,有效位置1;而当CPU要对该数据进行修改时,数据只需写入内存并同时将该有效位清0。当要从Cache中读取数据时需要测试其有效位:若为1则直接从Cache中取数,否则从内存中取数。
磁盘
本知识点的要点是掌握与磁盘相关的最重要的概念与计算公式。
磁盘是最常见的一种外部存储器,它是由一至多个圆形磁盘组成的,其常见技术指标如下。
(1)磁道数=(外半径-内半径)×道密度×记录面数
说明:硬盘的第一面与最后一面是起保护作用的,一般不用于存储数据,所以在计算的时候要减掉。例如,6个双面的盘片的有效记录面数是6×2-2=10。
(2)非格式化容量=位密度×3.14×最内圈直径×总磁道数
说明:每个磁道的位密度是不相同的,但每个磁道的容量却是相同的。一般来说,0磁道是最外面的磁道,其位密度最小。
(3)格式化容量=总磁道数×每道扇区数×扇区容量
(4)平均数据传输速率=每道扇区数×扇区容量×盘片转速
说明:盘片转速是指磁盘每秒钟转多少圈。
(5)存取时间=寻道时间+等待时间
说明:寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间。显然,寻道时间与磁盘的转速没有关系。
RAID
廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks,RAID)技术旨在缩小日益扩大的CPU速度和磁盘存储器速度之间的差距。其策略是用多个较小的磁盘驱动器替换单一的大容量磁盘驱动器,同时合理地在多个磁盘上分布存放数据以支持同时从多个磁盘进行读写,从而改善了系统的I/O性能。小容量驱动器阵列与大容量驱动器相比,具有成本低、功耗小和性能好等优势;低代价的编码容错方案在保持阵列的速度与容量优势的同时保证了极高的可靠性,同时也较容易扩展容量。但是由于允许多个磁头同时进行操作以提高I/O数据传输速度,因此不可避免地提高了出错的概率。为了补偿可靠性方面的损失,RAID使用存储的校验信息来从错误中恢复数据。最初,inexpensive一词主要针对当时另一种技术(Single Large Expensive Disk,SLED)而言,但随着技术的发展,SLED已是明日黄花,RAID和non-RAID皆采用了类似的磁盘技术。因此RAID现在代表独立磁盘冗余阵列(Redundant Array of Independent Disks),同时用independent来强调RAID技术所带来的性能改善和更高的可靠性。
RAID机制中共分8个级别,RAID应用的主要技术有分块技术、交叉技术和重聚技术。
(1)RAID 0级(无冗余和无校验的数据分块):具有最高的I/O性能和最高的磁盘空间利用率,易管理,但系统的故障率高,属于非冗余系统。它主要应用于那些关注性能、容量和价格而不是可靠性的应用程序。
(2)RAID 1级(磁盘镜像阵列):由磁盘对组成,每一个工作盘都有其对应的镜像盘,上面保存着与工作盘完全相同的数据拷贝,具有最高的安全性,但磁盘空间利用率只有50%。RAID 1主要用于存放系统软件、数据及其他重要文件。它提供了数据的实时备份,一旦发生故障,所有的关键数据即刻就可重新使用。
(3)RAID 2级(采用纠错海明码的磁盘阵列):采用了海明码纠错技术,用户需增加校验盘来提供单纠错和双验错功能。对数据的访问涉及阵列中的每一个盘。大量数据传输时I/O性能较高,但不利于小批量数据传输,因此实际应用中很少使用。
(4)RAID 3级和RAID 4级(采用奇偶校验码的磁盘阵列):把奇偶校验码存放在一个独立的校验盘上。如果有一个盘失效,其上的数据可以通过对其他盘上的数据进行异或运算得到。读数据很快,但因为写入数据时要计算校验位,因此速度较慢。
(5)RAID 5级(无独立校验盘的奇偶校验码磁盘阵列):与RAID 4类似,但没有独立的校验盘,校验信息分布在组内所有盘上,对于大批量和小批量数据的读写性能都很好。RAID4级和RAID 5级使用了独立存取技术,阵列中每一个磁盘都相互独立地操作,所以I/O请求可以并行处理。因此,该技术非常适合于I/O请求率高的应用,而不太适应于要求高数据传输率的应用。与其他方案类似,RAID 4级和RAID 5级也应用了数据分块技术,但块的尺寸相对大一些。
(6)RAID 6级(具有独立的数据硬盘与两个独立的分布式校验方案):在RAID 6级的阵列中设置了一个专用的、可快速访问的异步校验盘。该盘具有独立的数据访问通路,但其性能改进有限,价格却很昂贵。
(7)RAID 7级(具有最优化的异步高I/O速率和高数据传输率的磁盘阵列):是对RAID6级的改进。在这种阵列中的所有磁盘都具有较高的传输速度,有着优异的性能,是目前最高档次的磁盘阵列。
(8)RAID 10级(高可靠性与高性能的组合):由多个RAID等级组合而成,建立在RAID 0级和RAID 1级基础上。RAID 1级是一个冗余的备份阵列,而RAID 0级是负责数据读写的阵列,因此该等级又称为RAID 0+1级。由于利用了RAID 0极高的读写效率和RAID 1级较高的数据保护和恢复能力,使RAID 10级成为了一种性价比较高的等级,目前几乎所有的RAID控制卡都支持这一等级。
4. 下列操作系统中,不是基于linux内核的是( )。
A. AIX
B. CentOS
C. 红旗
D. 中标麒麟
设系统中有R类资源m个,现有n个进程互斥使用。若每个进程对R资源的最大需求为w,那么当m、n、w取下表的值时,对于下表中的a~e五种..
某计算机系统中互斥资源R的可用数为8,系统中有3个进程P1、P2和P3竞争R,且每个进程都需要i个R,该系统可能会发生死锁的最小i值为..
操作系统是裸机上的第一层软件,其他系统软件(如(8)等)和应用软件都是建立在操作系统基础上的。下图①②③分别表示(9)。
..
现代操作系统的基本功能是管理计算机系统的硬件、软件资源,这些管理工作分为处理机管理、存储器管理、设备管理、文件管理、作业和通信事务管理。
操作系统的性能与计算机系统工作的优劣有着密切的联系。评价操作系统的性能指标一般有:
(1)系统的可靠性。
(2)系统的吞吐率(量),是指系统在单位时间内所处理的信息量,以每小时或每天所处理的各类作业的数量来度量。
(3)系统响应时间,是指用户从提交作业到得到计算结果这段时间,又称周转时间;
(4)系统资源利用率,指系统中各个部件、各种设备的使用程度。它用在给定时间内,某一设备实际使用时间所占的比例来度量。
(5)可移植性。
5. 8086微处理器中执行单元负责指令的执行,它主要包括( )。
A. ALU运算器、输入输出控制电路、状态寄存器
B. ALU运算器、通用寄存器、状态寄存器
C. 通用寄存器、输入输出控制电路、状态寄存器
D. ALU运算器、输入输出控制电路、通用寄存器
假设某分时系统采用简单时间片轮转法,当系统中的用户数为n,时间片为q时,系统对每个用户的响应时间T=(10)。
假设系统有n个进程共享资源R,且资源R的可用数为3,其中n≥3。若采用PV操作,则信号量S的取值范围应为(9)。
假设系统中进程的三态模型如下图所示,图中的a、b和c的状态分别为(9)。
指令是指挥计算机完成各种操作的基本命令。
(1)指令格式。计算机的指令由操作码字段和操作数字段两部分组成。
(2)指令长度。指令长度有固定长度的和可变长度的两种。有些RISC的指令是固定长度的,但目前多数计算机系统的指令是可变长度的。指令长度通常取8的倍数。
(3)指令种类。指令有数据传送指令、算术运算指令、位运算指令、程序流程控制指令、串操作指令、处理器控制指令等类型。
6. 使用白盒测试时,确定测试数据应根据( )指定覆盖准则。
A. 程序的内部逻辑
B. 程序的复杂程度
C. 使用说明书
D. 程序的功能
把模块按照系统设计说明书的要求组合起来进行测试,属于( )。
以下关于CMM的叙述中,不正确的是( )。
使用白盒测试方法时,应根据(4)和指定的覆盖标准确定测试数据。
测试工作伴随着整个网络工程的全过程,无论是布线安装还是系统调试,都需要进行反复的测试和确定。
测试计划
测试计划应包括下列5个方面的内容。
1)简要说明
简要说明包括工程的概况和需要达到的主要指标。
2)测试内容
测试内容包括逐项列出的测试步骤、名称、内容和预期达到的目标。
3)测试清单
测试清单是对每项测试内容列出测试的部位和参与测试的单位,包括进度的安排、测试工具和相应的条件(设备和软件等)。
4)测试设计说明
测试设计说明是对每项测试内容的测试设计进行考虑,包括测试的控制方式、输入条件和预期的输出结果。
5)评价准则
评价准则用来说明测试所能检查的范围及其局限性,以及用来判断测试工作是否通过的评价尺度,包括合理的输出结果、测试输出结果与预期输出结果之间容许出现的偏差范围。
测试工作完成后,应提交一份测试分析报告。该报告主要包括下列内容:概要说明、测试结果、结论、原因分析、建议和评价。
网络测试
网络测试是对网络设备、网络系统以及网络对应用的支持进行检测,以展示和证明网络系统能否满足用户在性能、安全性、易用性、可管理性等方面需求的测试。网络测试的实施一般包括以下环节。
◆根据测试目的,确定测试目标。
◆在对相关网络技术和实现细节透彻掌握的基础上,设计测试方案。
◆建立网络负载模型。
◆配置测试环境,包括测试工具的选择及必要的测试工具的研发。
◆采集和整理数据。
◆分析和解释数据。
◆准确、直观、形象地表示测试结果。
网络测试包括网络设备测试、网络系统测试和网络应用测试3个层次。
1)网络设备测试
网络设备测试主要包括以下几个方面:功能测试、可靠性和稳定性测试、一致性测试、互操作性测试和性能测试等。
(1)功能测试用来验证产品是否具有设计的每一项功能。
(2)可靠性和稳定性测试往往通过加重负载的办法来分析和评估系统的可靠性和稳定性。
(3)一致性测试用来验证产品的各项功能是否符合标准。
(4)互操作性测试用来考查一个网络产品是否能在不同厂家的多种网络产品互联的网络环境中很好地工作。网络产品不同于其他产品的最大特点是必须符合标准,不同的网络产品之间要能互操作。
(5)性能测试的主要目标是分析产品在各种不同的配置和负载条件下的容量和对负载的处理能力,如交换机的吞吐量、转发延迟等。
典型的网络设备性能测试方法有两种:第一种是将设备放在一个仿真的网络环境中进行测试,第二种是使用专用的网络测试设备对产品进行测试。
2)网络系统测试和网络应用测试
网络系统测试除了普通意义上的物理连通性、基本功能和一致性的测试以外,主要包括网络系统的规划验证测试、网络系统的性能测试、网络系统的可靠性与可用性的测试与评估、网络流量的测量和模型化等。
(1)网络系统的规划验证测试主要采用的两个基本手段是模拟和仿真。
◆模拟是通过软件的办法,建立网络系统的模型,模拟实际网络的运行。通过设定各种配置和参数模拟系统的行为,对系统的容量、性能以及对应用的支撑程度给出定量的评价。这对于大型网络的规划设计是不可缺少的环节。
◆仿真是指通过建立典型的试验环境,仿真实际的网络系统。规划验证测试的目的在于分析所采用的网络技术的可行性和合理性,网络设计方案的合理性,所选网络设备的功能、性能等是否能够合理地、有效地支持网络系统的设计目标。
(2)网络系统的性能测试是指通过对网络系统的被动测量和主动测量来确定系统中站点的可达性、网络系统的吞吐量、传输速率、带宽利用率、丢包率、服务器和网络设备的响应时间、产生最大网络流量的应用和用户,以及服务质量等。此项工作同时可以发现系统的物理连接和系统配置中的问题,确定网络瓶颈,发现网络问题。测试设备记录一段时间内的网络流量,实时和非实时地分析数据。被动测量不干涉网络的正常工作,不影响网络的性能。主动测量向网络发送特定类型的数据包或网络应用,以便分析系统的行为。
(3)网络系统的可靠性与可用性的测试与评估。系统可用性取决于系统的可靠性(MTTF)及可维护性(MTTR)的高低,其中可靠性是指系统服务多久不中断,可维护性是指服务中断后多久可恢复。三者之间满足如下关系:
System Usability=MTTF/(MTTF+MTTR)*100%
其中,MTTF是指平均无故障时间,MTTR是指平均故障修复时间,MTBF是指平均故障间隔时间。有MTBF=MTTF+MTTR,故
System Usability=MTTF/MTBR*100%
(4)网络流量的测量和模型化。网络流量的测量和模型化对于分析网络性能和带宽的利用率、指导网络流量管理、开发高效的网络应用十分重要。这方面的工作主要有以下几个方面。
◆产生已知特征的流量,使该流量沿网络传播,最后回到测试仪。记录和分析流量特性的任何改变(如延迟漂移)。
◆对链路总体流量的测量和传输时间、吞吐量、带宽利用率等进行分析。
◆分析特定流量的特征和提供的QoS;收集一个时间段内的测量数据进行分析,分析流量沿网络传播过程中流量特征的变化和网络流量的统计行为,建立流量模型。
(5)网络应用层次上的测试则主要体现在测试网络对应用的支持水平,如网络应用的性能和服务质量的测试等。例如,部署基于IP的语音传输VoIP时,最直接的问题是网络中的交换机和路由器设备能否有效地支持语音传输,网络能支持多大的语音流量、多少个语音通道;如果网络支持VoIP,对网络的其他业务特别是关键业务,会产生什么样的影响;网络是否支持服务质量QoS。这些问题都需要通过网络应用测试来回答。
(6)网络系统测试的核心工具是协议分析仪。这是一种专用的网络测试设备,它能够连接到网络上,产生并向网络发送数据,捕捉网络数据,分析数据。协议分析仪一般具有网络监测、故障查找、协议解码和流量产生等功能。
网络设备安全性测试
现在有很多新型网络设备尤其是网络边缘路由器增加了防护功能,阻止了人为、故意的网络攻击。然而,提供的防护会不会对正常数据转发造成影响?有什么样的影响?这些很难从理论上估计,需要进行必要的网络设备安全性测试。
本节提到的测试项,主要是验证网络设备所提供的基本安全功能,并检测这些安全功能项对网络设备运行造成的影响。这些测试项分为访问列表测试和DOS攻击测试两大类。
1)访问列表测试
访问列表测试用于检测边缘路由器的访问列表能否起到防火墙的作用,访问列表测试控制网络传输过滤数据报文,访问列表测试阻止或允许数据报文通过网络接口。过滤依据可以是源地址、目的地址和上层协议号。边缘路由器通过将进入或离开的数据报文与访问列表中的过滤项进行比较,决定允许或阻止数据报文通过。对于边缘路由器能提供的访问列表容量,以及不断变化的访问列表对数据转发的影响都要进行测试。
2)DOS攻击测试
DOS攻击测试用于检测边缘路由设备抵抗"拒绝服务(DOS)攻击"的能力。当设备由于伪造的服务请求和虚假的传输而变得非常繁忙时,就无法响应正常的服务请求,从而造成损失。DOS攻击测试考验网络设备检测并阻止某种特定攻击的能力,并在检测受到某种攻击、设备超负荷运行的情况下,正常传输转发性能所受的影响。
具体的网络设备安全性测试项目如下。
◆访问列表性能测试。
◆虚假源地址攻击测试。
◆LAND攻击检查。
◆SYN风暴检查。
◆Smurf攻击检查。
◆Ping风暴检查。
◆Teardrop攻击检查。
◆Ping to Death检查。
性能测试
性能测试包括可靠性测试、功能/特性测试、吞吐量测试、衰减测试、容量规划测试、响应时间测试、可接受性测试和网络瓶颈测试等。
1)可靠性测试
可靠性测试是使被测网络在较长时间内(通常是24~72小时)经受较大负载,通过监视网络中发生的错误和出现的故障,验证在高强度环境中网络系统的存活能力,也就是它的可靠性。可靠性测试可作为接受性测试的一部分,在产品评估测试中可作为比较测试或作为产品升级进行的衰减测试的一部分。采用的负载模式很重要,越贴近真实负载模式越好。可靠性测试中使用网络分析仪监控网络运行,捕获网络错误。
通常在较长时间段内和持续负载下,不同网络具有不同级别的存活度。如果测试时间足够长、负载足够大,所有可靠性测试最终都会失败。
可靠性测试应用于网络生命周期中的以下3个阶段。
◆计划:作为产品评估测试的一部分,比较不同产品或建立要求规范。
◆开发:验证计划中的要求是否能在系统中完全实现。
◆组建:作为可接受性测试的一部分,在网络运行前进行,核实系统是否达到要求。
2)功能/特性测试
特性测试核实的是单个命令和应用程序功能,通常用较小的负载完成,关注的是用户界面、应用程序的操作以及用户与计算机之间的互操作。特性测试通常由开发人员在他们的工作台上完成,或是在一个小型网络环境下由测试人员完成。
功能测试是面向网络的,核实的是应用程序的多用户特征和在重负载下后台功能是否能正确地执行,关注的是当多个用户正在运行应用程序时,网络和文件系统或数据库服务器之间的交互。功能测试要求网络的配置和负载非常接近于运行环境下的模式。该测试可以在运行网络或独立网络实验室里完成。它只应用于网络生命周期中的以下3个阶段。
◆开发:用于核实在期望的运行模式下,在多用户环境里,应用程序的运行性能是否达到要求。
◆组建:在应用程序安装前完成,可独立进行,也可作为接受性测试的一部分,用于核实在期望的运行模式下,应用程序的运行性能是否达到要求。
◆运行:该阶段测试是在应用程序运行后进行的,如果在运行系统中遇到了问题,该阶段测试用于核实应用程序是否如最初应用时那样工作。
3)吞吐量测试
吞吐量测试和应用程序的响应时间测试相似,但检测的是每秒钟传输数据的字节数和数据报文数,而不是响应时间。它用于检测服务器、磁盘子系统、适配卡/驱动连接、网桥、路由器、集线器、交换器和通信连接。吞吐量测试用于测量网络性能、找到网络瓶颈,以及比较不同产品的性能。
吞吐量测试不使用程序脚本,它借助某些软件对网络服务器执行文件输入/输出操作来产生流量,或通过某些软件在网络上发送专门的数据报文或帧。该测试应用于网络生命周期的以下几个阶段。
◆计划:用于比较网络产品,为模拟网络节点提供运行特征和要求规范。
◆开发:用于核实网络组件以及整个网络是否达到规范要求的水平。
◆组建:可独立进行或作为可接受性测试的一部分,在网络组件或整个网络正式运行之前核实它们是否满足规范的要求。
4)衰减测试
衰减测试是将硬件或软件的新版本与当前版本在性能、可靠性和功能等方面进行比较,同时验证产品升级对网络的性能不会有不良影响。衰减测试混杂了很多为完成其他测试任务要进行的测试。衰减测试的关键是要保证被测组件应是运行网络中最关键或最脆弱的组件。
衰减测试不强调升级版的新特性。新特性测试在衰减测试之前作为功能/特征测试的一部分就已完成。尽管新产品应该解决了当前版本中的错误,但它们也经常存在一些以前没有出现过的错误,如果这些错误发生在产品的关键部分,将会引起严重问题。衰减测试不需要测试产品的所有特性,但网络用户正常运行所依靠的关键功能必须在测试之列。
衰减测试应用于网络生命周期的以下两个阶段。
◆开发:用于核实产品升级版是否能满足性能、互操作性和可靠性的要求。
◆升级:在采用升级版本之前用该项测试来比较升级版和当前版,看升级版是否和当前版一样满足性能、互操作性和可靠性的要求。
5)容量规划测试
容量规划测试用于检测当前网络中是否存在多余的容量空间。当网络承受的总负载超过网络总容量时,网络的性能或吞吐量就有可能下降,所以在网络负载接近这一临界点(网络的最大容量)前,就要根据负载增长的幅度扩充网络资源。
进行该项测试要逐渐增加网络负载,直到网络的运行性能、可接受的水平或吞吐量不断下降,达不到设计所要求的水平为止。网络运行负载和网络最大吞吐量之间的差额就是现有系统的冗余量。
容量规划测试应用于网络生命周期的以下3个阶段。
◆计划:用于估计实施该系统所需要的资源,也可用于成本分析和制定预算。
◆开发:检测系统要求的资源是否满足特定的响应时间和吞吐量的要求。
◆升级:当系统响应时间或吞吐量下降时,重新选取网络组件。
6)响应时间测试
响应时间测试用于检测系统完成一系列任务所需的时间,本项测试是用户最关心的。对于表示层,如微软的Windows,该测试是指在不同桌面之间切换或装载新负载所需的时间。在不同负载即不同实际或模拟用户的数目下运行这一实验,可对每个被测试的应用程序生成一个负载—响应时间曲线。
在应用程序测试中,可执行一系列典型网络动作的命令,如打开、读、写、查找和关闭文件,这些命令提供了最好的负载模拟。例如,对每个进行测试的工作站,检测它在几秒内能完成这些命令。
响应时间测试应用于网络生命周期的以下几个阶段。
◆计划:使用模拟应用程序进行,检测规范要求的各项网络服务。
◆开发:检验规范要求的网络服务是否正在被实现。
◆组建:在接受和组建之前,核实规范要求下的网络服务是否已经被实现。
◆运行:检测网络服务的基准和变化,这可能是针对系统质量的最好测试。
响应时间测试应该包括对系统可靠性的检测。常见的可靠性问题,如在路由器或服务器中大量丢失数据报文或由于网络组件故障引发大量坏数据报文,将严重影响网络的响应时间,因此在整个测试期间都应用网络分析仪监视系统错误。
7)可接受性测试
可接受性测试是在系统正式实施前的"试运行"。它是一个非常有效的方法,可确保新系统能提供良好而稳定的性能。和衰减测试一样,可接受性测试中也包含多项测试,如响应时间测试、稳定性测试和功能/特性测试。
可接受性测试应用于许多领域,但在安装或升级网络前应进行的网络可接受性测试则经常被忽略,而事实上,可接受性测试能为网络购买者在经济和技术上提供有力的保证和参考。
可接受性测试可以仅在新增加的部件上完成,将已存在的负载加上新增程序或新增组件可能产生的负载作为测试使用的负载。
可接受性测试应用于网络生命周期的以下两个阶段。
◆开发:在开发阶段前定期执行,用来核实要求的标准是否可行。
◆组建:在网络投入运行之前应用,用来核实系统是否满足所有要求。
8)网络瓶颈测试
通过网络瓶颈测试可以找到导致系统性能下降的瓶颈。测试中需要测试和计算系统的最大吞吐量,然后再在单个网络组件上进行该项测试,明确各组件的最大吞吐量。通过计算单个组件的最大吞吐量和系统最大吞吐量之间的差额,就能发现系统瓶颈的位置以及哪些组件有多余的容量。
系统瓶颈在不同的测试案例中出现的位置可能有所变化。例如,一个客户业务应用程序测试可能表明服务器是系统的瓶颈,而对一个电子邮件系统的测试则可能表明广域网连接才是网络的限制因素。如果可以在测试的环境中重现引起问题的负载,那么这样的测试结果对解决问题将有很大帮助。
瓶颈测试应用于网络生命周期的以下两个阶段。
◆组建:可以作为容量计划的一部分,用于帮助相关人员明确影响网络性能和响应时间的瓶颈位置。
◆运行:作为故障检测的一部分,帮助相关人员找出影响网络性能或引起系统问题的网络瓶颈。
测试报告
测试报告是整个项目的第一份供大家交流和供领导查阅的报告,人们对工程的满意程度和对工程质量的认可很大程度上来源于这份报告。通常在独立网络测试后,要总结测试数据,并基于此对测试过的同类产品进行排序;而系统内部的测试仅是得出一个简单的结论。
测试报告呈现的内容和采取的表现形式非常重要,测试报告通常包含以下信息。
◆测试目的:用一句或两句话解释本次测试的目的。
◆结论:从测试中得到的信息推荐下一步的行动。
◆测试结果总结:对测试进行总结并由此得出结论。
◆测试内容和方法:简单地描述测试是怎样进行的,应该包括负载模式、测试脚本和数据收集方法,并且要解释采取的测试方法怎样保证测试结果和测试目的的相关性,以及测试结果是否可重现。
◆测试配置:网络测试配置用图形表示出来。
测试报告的形式可以是一个简短的总结(2~4页),也可以是一个很长的书面文档(5~20页)。测试总结可以使用图形表示测试结果,如应用程序的响应时间、吞吐量和产品评估。而系统衰减性测试、配置规模测试和应用程序的功能/特性测试的测试报告还要包括更多的信息。
在非常特殊的情况下,测试报告需要长达50页。它通常包括从项目开始到结束按时间编排的所有活动,以及非常详细的问题信息和解决问题的信息。
网络测试工具
网络测试工具一般包括以下几个。
◆网络管理和监控工具。
◆建模和仿真工具。
◆服务质量和服务级别管理工具。
网络管理和监控工具(如HP公司的OpenView)能够在网络测试运行过程中提示某些问题的网络事件的出现。这些工具可以是驻留在网络设备中的应用软件。
协议分析仪也能被用于监测新设计的网络,帮助分析通信的行为、差错、利用率、效率以及广播和多播分组。
建模工具和仿真工具是更为先进的用来测试验证网络设计的工具。仿真就是在不建立实际网络的情况下,使用软件和数学模型来分析网络行为的过程。利用仿真工具,可以根据所需要测试的目标开发一个网络模型,从而估计网络性能,并对各种网络实现方法之间的差异进行比较。仿真工具使得选择比较的空间变得更大,特别适合于实现和检查一个扩展的原型系统。一个好的仿真工具往往非常昂贵,实现的技术也比较复杂,它要求开发人员不但要精通统计分析和建模技术,而且还要对计算机网络有所了解。
服务级别管理工具是一种比较新型的工具,主要用来分析网络应用的端到端性能。有些工具能够管理服务质量和服务级别,有些工具能够监控实时应用的性能,有些工具能够预测新的应用性能,有些工具可以将上述功能结合起来实现更强大的功能。
白盒测试也称为结构测试,根据程序的内部结构和逻辑来设计测试用例,对程序的路径和过程进行测试,检查是否满足设计的需要。
7. 以下关于RISC指令系统基本概念的描述中,错误的是( )。
A. 选取使用频率低的一些复杂指令,指令条数多
B. 指令长度固定
C. 指令功能简单
D. 指令运行速度快
若CPU要执行的指令为:MOV R1, #45 (即将数值45传送到寄存器R1中),则该指令中采用的寻址方式为(4)。
下列关于流水线方式执行指令的叙述中,不正确的是( )。
以下关于RISC(精简指令系统计算机)技术的叙述中,错误的是( )。
指令
指令是指挥计算机完成各种操作的基本命令。
(1)指令格式。计算机的指令由操作码字段和操作数字段两部分组成。
(2)指令长度。指令长度有固定长度的和可变长度的两种。有些RISC的指令是固定长度的,但目前多数计算机系统的指令是可变长度的。指令长度通常取8的倍数。
(3)指令种类。指令有数据传送指令、算术运算指令、位运算指令、程序流程控制指令、串操作指令、处理器控制指令等类型。
寻址方式
寻址方式有以下几种。
(1)立即寻址。立即寻址是指操作数作为指令的一部分而直接写在指令中,这种操作数称为立即数。
(2)寄存器寻址。寄存器寻址是指指令所要的操作数已存储在某寄存器中,或把目标操作数存入寄存器。
(3)直接寻址。直接寻址是指指令所要的操作数存放在内存中,在指令中直接给出该操作数的有效地址。
(4)寄存器间接寻址。寄存器间接寻址是指操作数在存储器中,操作数的有效地址用SI、DI、BX、BP这4个寄存器之一来指定。
(5)寄存器相对寻址。寄存器相对寻址是指操作数在存储器中,其有效地址是一个基址寄存器(BX、BP)或变址寄存器(SI、DI)的内容和指令中的8位/16位偏移量之和。
(6)基址加变址寻址。基址加变址寻址是指操作数在存储器中,其有效地址是一个基址寄存器(BX、BP)和一个变址寄存器(SI、DI)的内容之和。
(7)相对基址加变址寻址。相对基址加变址寻址是指操作数在存储器中,其有效地址是一个基址寄存器(BX、BP)的值、一个变址寄存器(SI、DI)的值和指令中的8位/16位偏移量之和。
复杂指令集计算机
在计算机发展的早期,计算机技术水平较低,硬件较为简单,由硬件实现的指令系统的功能也就简单,一般只有定点的加减及逻辑运算、数据传送和程序转移等数十条最基本的指令。随着计算机逻辑元件的迅猛发展,特别是超大规模集成电路的发展,机器的造价、体积、功耗及可靠性等方面都有了长足的发展;同时,随着计算机应用领域日益广泛,对指令系统功能的要求越来越高,使指令系统逐渐发展到几百种,寻址方式也更加灵活多样,具备这种指令系统的计算机称为复杂指令集计算机(Complex Instruction Set Computer, CISC)。
精简指令集计算机
在指令系统中只有大约20%的最简单的指令被经常使用,其使用频度达80%。若只保留20%的最简单的指令,使指令尽可能简单,从而设计一种硬件结构十分简单、执行速度很高的CPU,这就是精简指令集计算机(RISC)。
指令是指挥计算机完成各种操作的基本命令。
(1)指令格式。计算机的指令由操作码字段和操作数字段两部分组成。
(2)指令长度。指令长度有固定长度的和可变长度的两种。有些RISC的指令是固定长度的,但目前多数计算机系统的指令是可变长度的。指令长度通常取8的倍数。
(3)指令种类。指令有数据传送指令、算术运算指令、位运算指令、程序流程控制指令、串操作指令、处理器控制指令等类型。
关于系统可靠性的基本概念如下。
(1)系统的可靠性。系统的可靠性是指从系统开始运行(t=0)到某时刻t这段时间内能正常运行的概率,用R(t)表示。
(2)失效率。失效率是指单位时间内失效的元件数与元件总数的比例,通常用λ表示。当λ为常数时,可靠性与失效率的关系为R(t)=e-λt。
(3)平均无故障时间(MTBF)。平均无故障时间是指两次故障之间系统能正常工作的时间的平均值。它与失效率的关系为MTBF=1/λ。
(4)平均失效前时间(MTTF)。平均失效前时间是指从故障发生到机器修复平均所需要的时间。通常用平均修复时间(MTTR)来表示计算机的可维修性,即计算机的维修效率。
(5)可用性。可用性是指计算机的使用效率,它以系统在执行任务的任意时刻能正常工作的概率A来表示,即A=MTBF/(MTBF+MTTR)。
8. 计算机上采用的SSD(固态硬盘)实质上是( )存储器。
A. Flash
B. 磁盘
C. 磁带
D. 光盘
内存按字节编址,地址从AOOOOH到CFFFFH,共有(3)字节。若用存储容量为64K×8bit的存储器芯片构成该内存空间,至少需要(4)片。..
位于CPU与主存之间的高速缓冲存储器(Cache)用于存放部分主存数据的拷贝, 主存地址与Cache地址之间的转换工作由(1)完成。
在输入输出控制方法中,采用 (1) 可以使得设备与主存间的数据块传送无需CPU干预。
存储器是计算机的一个重要组成部分,它用来保存计算机工作所必需的程序和数据。正因为有了存储器,计算机才有信息记忆功能。
分类
1)按在计算机中的作用分类
按在计算机中的作用可分为内部存储器、外部存储器和缓冲存储器。
(1)内部存储器简称内存或主存。内存是主机的一个组成部分,它用来容纳当前正在使用的,或者经常要使用的程序或数据,CPU可以直接从内部存储器取指令或存取数据。
(2)外部存储器简称外存或辅存。外存也是用来存储各种信息的,但是CPU要使用这些信息时,必须通过专门的设备将信息先传送到内存中,因此外存存放相对来说不经常使用的程序和数据。另外,外存总是和某个外部设备相关的。
(3)缓冲存储器用于两个工作速度不同的部件之间,在交换信息过程中起缓冲作用。
2)按存储介质分类
按存储介质可分为半导体存储器、磁表面存储器和光电存储器。
3)按存取方式分类
按存取方式可分为随机存储器(RAM)、只读存储器(ROM)和串行访问存储器。
(1)随机存储器(Random Access Memory, RAM)又称为读写存储器,是指通过指令可以随机地、个别地对各个存储单元进行访问。它是易失性存储器,这种存储器一旦去掉其电源,则所保存的信息全部丢失。
(2)只读存储器(Read Only Memory, ROM)是一种对其内容只能读不能写入的存储器。它属于非易失性存储器,当去掉其电源后,所保存的信息仍保持不变。
(3)串行访问存储器(Serial Access Storage, SAS)是指对存储器的信息进行读写时,需要顺序地访问。
主存储器
1)主存储器的种类
主存储器一般由半导体随机存储器(RAM)和只读存储器(ROM)组成,其绝大部分由RAM组成。按所用元件类型来分有双极性和MOS存储器两类。前者存取速度比后者高,但集成度不如后者,价格也高,主要用于小容量存储器,后者主要用于大容量存储器。MOS存储器按存储元件在运行中能否长时间保存信息来分,有静态存储器(SRAM)和动态存储器(DRAM)两种。前者只要不断电,信息就不会丢失,而后者需要不断给电容充电才能使信息保持。由于后者密度大且较便宜,故使用较多。
2)主存储器的主要技术指标
衡量一个主存储器的性能指标主要为主存容量、可直接寻址空间、存储器存取时间、存储周期时间和带宽等。
(1)主存容量是指每个存储芯片所能存储的二进制的位数,也就是存储单元数乘以数据线位数。
(2)可直接寻址空间是由地址线位数确定的。例如,提供32位物理地址的计算机支持对4(232)GB的物理主存空间的访问。
(3)存储器存取时间又称为存储器访问时间,是指从启动一次存储器操作到完成该操作所经历的时间。
(4)存储周期时间是指连续启动两次独立的存储器操作所需间隔的最小时间。
(5)带宽是指存储器的数据传送率,即每秒传送的数据位数。
3)主存储器的构成
主存储器一般由地址寄存器、数据寄存器、存储矩阵、译码电路和控制电路组成。
(1)地址寄存器(MAR)用来存放由地址总线提供的将要访问的存储单元的地址码。
(2)数据寄存器(MDR)用来存放要写入存储矩阵或从存取矩阵中读取的数据。
(3)存储矩阵用来存放程序和数据的存储单元排成的矩阵。
(4)译码电路根据存放在地址寄存器中的地址码,在存储体中找到相应的存储单元。
(5)控制电路根据读写命令控制主存储器的各部分协作完成相应的操作。
4)主存储器的基本操作
要从存储器中取一个信息字,CPU必须指定存储器字地址,并进行"读"操作。CPU把信息字的地址送到MAR,经地址总线送往主存储器,同时CPU应用控制线发一个"读"请求。此后,CPU等待从主存储器发回来的回答信号,通知CPU"读"操作完成,说明存储字内容已经读出并放在数据总线上送入MDR。
为了存一个字到主存,CPU先将信息字在主存中的地址经MAR送到地址总线,并将信息字送到MDR,同时CPU发出"写"命令。此后,CPU等待从主存储器发回来的回答信号,通知CPU"写"操作完成,说明主存从数据总线接收到信息字并按地址总线指定的地址存储。
外存储器
外存储器的特点是容量大、价格低,但是存取速度慢,用于存放暂时不用的程序和数据。外存储器主要有磁盘存储器、磁带存储器和光盘存储器。磁盘是最常用的外存储器,通常分软磁盘和硬磁盘两类。目前,常用的外存储器有软盘、硬盘和光盘存储器。它们和内存一样,存储容量也是以字节为基本单位的。
1)软磁盘存储器
软磁盘是用柔软的聚酯材料制成圆形底片,在两个表面涂有磁性材料。目前,常用软盘的直径为3.5英寸。软磁盘安装在硬塑胶盒中,而且没有裸露部分,因此使盘片得到了更好的保护,信息在磁盘上是按磁道和扇区的形式来存放的。磁道即磁盘上的一组同心圆的信息记录区,它们由外向内编号,一般为0~79道。每条磁道被划成相等的区域,称为扇区。一般每磁道有9、15或18个扇区。每个扇区的容量为512B。一个软盘的存储容量可由下面的公式算出,即
软盘总容量=磁道数×扇区数×扇区字节数(512B)×磁盘面数(2)
例如,3.5英寸软盘有80个磁道,每条磁道18个扇区,每个扇区512B,共有两面,则其存储容量的计算公式为:
软盘容量=80×18×512×2=1 474 560B=1.44MB
扇区是软盘(或硬盘)的基本存储单元,每个扇区记录一个数据块,数据块中的数据按顺序存取。扇区也是磁盘操作的最小可寻址单位,与内存进行信息交换是以扇区为单位进行的。
在进行写入操作时,写保护开关先要对磁盘是否有写保护缺口进行检索,如果检测到有写保护缺口,则允许进行写操作;如果没有或被胶纸黏封,则不能进行写操作。
使用软磁盘应注意防磁、防潮、防污(灰尘和手摸)、防丢信息(写保护和勤复制)和防病毒(常加写保护,不使用来历不明的软磁盘)。
2)硬磁盘存储器
硬磁盘是由涂有磁性材料的铝合金圆盘组成的。目前常用的硬盘是3.5英寸的,这些硬盘通常采用温彻斯特技术,即把磁头、盘片及执行机构都密封在一个整体内,与外界隔绝,所以这种硬盘也称为温彻斯特盘。
硬盘的两个主要性能指标是硬盘的平均寻道时间和内部传输速率。一般来说,转速越高的硬盘寻道的时间越短,而且内部传输速率也越高,不过内部传输速率还受硬盘控制器Cache的影响。目前,市场上硬盘常见的转速有5400r/min、7200r/min,最快的平均寻道时间为8ms,内部传输速率最高为190MB/s。硬盘的每个存储表面被划分成若干个磁道(不同硬盘磁道数不同),每个磁道被划分成若干个扇区(不同的硬盘扇区数不同)。每个存储表面的同一道形成一个圆柱面,称为柱面。柱面是硬盘的一个常用指标。
硬盘的存储容量计算公式为
存储容量=记录面面数×每面磁道数×每扇区字节数×扇区数
例如,某硬盘有记录面15个,磁道数(柱面数)8894个,每道63扇区,每扇区512B,则其存储容量为
15×8894×512×63=4.3GB
使用硬盘应注意避免频繁开关机器电源,应使其处于正常的温度和湿度、无振动、电源稳定的良好环境。
3)光盘存储器
光盘指的是利用光学方式进行信息存储的圆盘。人们把采用非磁性介质进行光存储的技术称为第一代光存储技术,其缺点是不能像磁记录介质那样把内容抹掉后重新写入新的内容。把采用磁性介质进行光存储的技术称为第二代光学存储技术,其主要特点是可擦写。
光盘存储器可分成CD-ROM、CD-R和可擦除型光盘。
CD-ROM(Compact Disc-Read Only Memory),是只读型光盘,这种光盘的盘片是由生产厂家预先将数据或程序写入,出厂后用户只能读取,而不能写入或修改。CD-R(CD-Recordable),即一次性可写入光盘,但必须在专用的光盘刻录机中进行。可擦除型光盘可多次写入。
高速缓冲存储器
计算机的主-辅存层次解决了存储器的大容量和低成本之间的矛盾,但是在速度方面,计算机的主存和CPU一直有很大的差距,这个差距限制了CPU速度潜力的发挥。为了弥合这个差距,设置高速缓冲存储器(Cache)是解决存取速度的重要方法。就是在主存和CPU之间设置一个高速的容量相对较小的存储器,如果当前正在执行的程序和数据存放在这个存储器中,当程序运行时不必从主存取指令和数据,所以提高了程序的运行速度。它具有以下特点。
(1)位于CPU与主存之间。
(2)容量小,一般在几千字节到几兆字节之间。
(3)速度一般比主存快5~10倍,由快速半导体存储器制成。
虚拟存储器
主存的特点是速度快但容量小,CPU可直接访问。外存的特点是容量大和速度慢,CPU不能直接访问。用户的程序和数据通常放在外存中,因此需要经常在主存与外存之间取来送去,由用户来干预调度很不方便。虚拟存储器用来解决这个矛盾,使用户感到他可以直接访问整个内、外存空间,而不需用户干预。因此容量很大的速度较快的外存储器(硬磁盘)成为虚拟存储器主要组成部分。用户程序采用虚地址访问整个虚拟空间,而指令执行时只能访问主存空间。因此,必须进行虚实地址转换,把不在主存的单元内容调入主存某单元,再按转换的实地址进行访问。
9. 信息安全强调信息/数据本身的安全属性,下面( )不属于信息安全的属性。
A. 信息的秘密性
B. 信息的完整性
C. 信息的可用性
D. 信息的实时性
以下关于网络安全设计原则的说法,错误的是(39)。
代理ARP是指(22)。
下列网络攻击行为中,属于DoS攻击的是(42)。
信息系统安全是指确保以电磁信号为主要形式的在信息网络系统进行通信、处理和使用的信息内容,在各个物理位置、逻辑区域、存储和传输介质中处于动态和静态过程中的保密性、完整性和可用性,以及与人、网络、环境有关的技术安全、结构安全和管理安全的综合。
总的来说,信息系统安全就是要保证信息系统的用户在允许的时间内、从允许的地点、通过允许的方法,对允许范围内的信息进行被允许的处理。完整地构建信息系统的安全体系框架后,信息系统安全体系应当由技术体系、组织结构体系和管理体系共同构建。
信息系统安全属性分为3个方面,分别是可用性、保密性和完整性。任何对于信息可用性、保密性和完整性的破坏与攻击事件都有可能会引起信息安全事故或事件。
可用性是信息系统工程能够在规定条件下和规定的时间内完成规定的功能的特性。
保密性是信息不被泄露给非授权的用户、实体或过程,信息只为授权用户使用的特性。
完整性定义为保护信息及其处理方法的准确性和完整性。信息完整性一方面是指信息在利用、传输、存储等过程中不被删除、修改、伪造、乱序、重放和插入等,另一方面是指信息处理方法的正确性。
A. 国家版权局
B. 国家新闻出版署
C. 国家知识产权局
D. 地方知识产权局
李某受非任职单位委托,利用该单位实验室、实验材料和技术资料开发了一项软件产品。对该软件的权利归属,表达正确的是( )。
王某是一名软件设计师,按公司规定编写软件文档,并上交公司存档。这些软件文档属于职务作品,且(7)。
甲公司购买了一个工具软件,并使用该工具软件开发了新的名为“恒友”的软件,甲公司在销售新软件的同时,向客户提供工具软件的复..
根据《计算机软件保护条例》规定,软件著作权人对其创作的软件产品享有以下9种权利。
(1)发表权:即决定软件是否公之于众的权利。
(2)署名权:即表明开发者身份,在软件上署名的权利。
(3)修改权:即对软件进行增补、删节,或者改变指令、语句顺序的权利。
(4)复制权:即将软件制作一份或者多份的权利。
(5)发行权:即以出售或者赠与方式向公众提供软件的原件或复制件的权利。
(6)出租权:即有偿许可他人临时使用软件的权利。
(7)信息网络传播权:即以信息网络方式向公众提供软件的权利。
(8)翻译权:即将原软件从一种自然语言文字转换成另一种自然语言文字的权利。
(9)使用许可权、获得报酬权、转让权。
软件著作权自软件开发完成之日起生效。
(1)著作权属于公民。著作权的保护期为作者终生及其死亡后的50年(第50年的12月31日)。对于合作开发的,则以最后死亡的作者为准。值得注意的是,在1991实施的上一版条例中,保护期限是25年,而在最新的条例中,已经改为了50年。在作者死亡后,将根据继承法转移除了署名权之外的著作权。
(2)著作权属于单位。著作权的保护期为50年(首次发表后第50年的12月31日),若50年内未发表的,不予保护。单位变更、终止后,其著作权由承受其权利义务的单位享有。
当得到软件著作权人的许可,获得了合法的计算机软件复制品后,复制品的所有人享有以下权利。
(1)根据使用的需求,将该计算机软件安装到设备中(计算机、PDA等信息设备)。
(2)制作复制品的备份,以防止复制品损坏,但这些复制品不得通过任何方式转给其他人使用。
(3)根据实际的应用环境,对其进行功能、性能等方面的修改。但未经软件著作权人许可,不得向任何第三方提供修改后的软件。
如果使用者只是为了学习、研究软件中包含的设计思想、原理,而以安装、显示和存储软件等方式使用软件,可以不经软件著作权人的许可,不向其支付报酬。
根据著作权法及实施条例规定,著作权人对作品享有5种权利:
(1)发表权:即决定作品是否公之于众的权利。
(2)署名权:即表明作者身份,在作品上署名的权利。
(3)修改权:即修改或授权他人修改作品的权利。
(4)保护作品完整权:即保护作品不受歪曲、篡改的权利。
(5)使用权、使用许可权和获取报酬权、转让权:即以复制、表演、播放、展览、发行、摄制电影、电视、录像,或者改编、翻译、注释和编辑等方式使用作品的权利,以及许可他人以上述方式使用作品,并由此获得报酬的权利。
根据著作权法的相关规定,著作权的保护是有一定期限的。
(1)著作权属于公民。署名权、修改权、保护作品完整权的保护期没有任何限制,永远属于保护范围。而发表权、使用权和获得报酬权的保护期为作者终生及其死亡后的50年(第50年的12月31日)。作者死亡后,著作权依照继承法进行转移。
(2)著作权属于单位。发表权、使用权和获得报酬权的保护期为50年(首次发表后的第50年的12月31日),若50年内未发表的,不予保护。但单位变更、终止后,其著作权由承受其权利义务的单位享有。
当第三方需要使用时,需得到著作权人的使用许可,双方应签订相应的合同。合同中应包括许可使用作品的方式,是否专有使用,许可的范围与时间期限,报酬标准与方法,以及违约责任等。若合同未明确许可的权力,需再次经著作权人许可。合同的有效期限不超过10年,期满时可以续签。
对于出版者、表演者、录音录像制作者、广播电台、电视台而言,在下列情况下使用作品,可以不经著作权人许可、不向其支付报酬。但应指明作者姓名、作品名称,不得侵犯其他著作权。
(1)为个人学习、研究或欣赏,使用他人已经发表的作品。
(2)为介绍、评论某一个作品或说明某一个问题,在作品中适当引用他人已经发表的作品。
(3)为报道时事新闻,在报纸、期刊、广播、电视节目或新闻纪录影片中引用已经发表的作品。
(4)报纸、期刊、广播电台、电视台刊登或播放其他报纸、期刊、广播电台、电视台已经发表的社论、评论员文章。
(5)报纸、期刊、广播电台、电视台刊登或者播放在公众集会上发表的讲话,但作者声明不许刊登、播放的除外。
(6)为学校课堂教学或科学研究,翻译或者少量复制已经发表的作品,供教学或科研人员使用,但不得出版发行。
(7)国家机关为执行公务使用已经发表的作品。
(8)图书馆、档案馆、纪念馆、博物馆和美术馆等为陈列或保存版本的需要,复制本馆收藏的作品。
(9)免费表演已经发表的作品。
(10)对设置或者陈列在室外公共场所的艺术作品进行临摹、绘画、摄影及录像。
(11)将已经发表的汉族文字作品翻译成少数民族文字在国内出版发行。
(12)将已经发表的作品改成盲文出版。
11. 8条模拟信道采用TDM复用成1条数字信道,TDM帧的结构为8字节加1比特同步开销(每条模拟信道占1个字节)。若模拟信号频率范围为10~16kHz. 样本率至少为(11)样本/秒,此时数字信道的数据速率为(12)Mbps。
A. 8k
B. 10k
C. 20k
D. 32k
传输信道频率范围为10MHz~16MHz,采用QPSK调制,支持的最大速率为( )Mbps。
电话信道的频率为0~4kHZ ,若信噪比为30dB,则信道容量为(12)kb/s ,要达到此容量,至少需要(13)个信号状态。
设信道带宽为1000Hz,信噪比为30dB,则信道的最大数据速率约为( )b/s.
DM(Delta Modulation)即增量调制,又称ΔM调制,是最简单的有损预测编码方法,早期在数字电话中被采用,是一种最简单的差值脉冲编码。实际的采样信号与预测的采样信号的差的极性若为正,则用1表示,反之则用0表示。由于DM编码只用1位对声音信号进行编码,所以DM系统又称1位系统。
软件复用是指将已有的软件及其有效成分用于构造新的软件或系统。构件技术是软件复用实现的关键。
信号是当一个事件发生时产生的软中断,它将信号接收者从其正常的执行路径移开并触发相关的异步处理。本质上,信号通知其他任务或ISR运行期间发生的事件,与正常中断类似,这些事件与被通知的任务是异步的。信号的编号和类型依赖于具体的嵌入式系统的实现。通常,嵌入式系统均提供信号设施,任务可以为每个希望处理的信号提供一个信号处理程序,或是使用内核提供的默认处理程序,也可以将一个信号处理程序用于多种类型的信号。信号可以有被忽略、挂起、处理或阻塞等4种不同的响应处理。
信道是数据传输的通路,在计算机网络中信道分为物理信道和逻辑信道。
(1)物理信道。物理信道指用于传输数据信号的物理通路,由传输介质与有关通信设备组成。物理信道还可根据传输介质的不同而分为有线信道和无线信道,也可按传输数据类型的不同分为数字信道和模拟信道。
(2)逻辑信道。逻辑信道指在物理信道的基础上,发送与接收数据信号的双方通过中间结点所实现的逻辑联系,由此为传输数据信号形成的逻辑通路。逻辑信道可以是有连接的,也可以是无连接的。
信道传输按信息传送的方向与时间可以分为单工、半双工、全双工三种传输方式。
(1)单工通信。单工通信就是单向传输,传统的电视、电台就是单工传输。单工传输能够节约传输的成本,但是没有了交互性。现在传统的电视向可以点播的电视方向发展,这使得必须对原来的单工传输的有线电视网络进行改造才能支持点播。
(2)半双工通信。半双工通信可以传输两个方向的数据,但是在一段时间内只能接受一个方向的数据传输,许多对讲机使用的就是半双工方式,当一方按下按钮说话时,不能听见对方的声音。这种方式也称为“双向交替”。对于数字通道,如果只有一条独立的传输通道,那么就只能进行半双工传输。对于模拟通道,如果接收和发送使用同样的载波频率,那么它也只能使用半双工的传输方式。
(3)全双工通信。全双工通信意味着两个方向的传输能够同时进行,电话是典型的全双工通信。要实现全双工通信,对于数字通道,必须有两个独立的传输路径。对于模拟通道,如果没有两条独立的路径,双方使用的载波频率不同,那么也能实现。另外还有一种“回声抵消”的方法,也能实现全双工通信。下图所示是单工、半双工和全双工示意图。
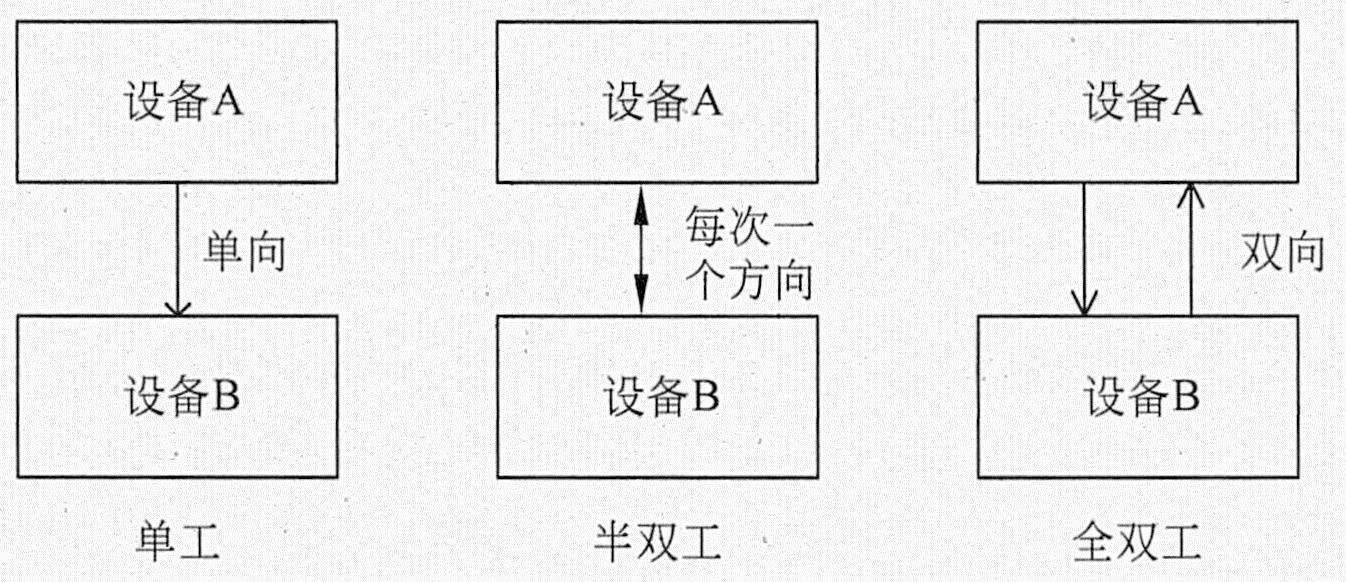
传输方式比较示意图
在电话通信中,电话线上传送的电信号是模拟用户声音大小的变化而变化的。这个变化的电信号无论在时间上或是在幅度上都是连续的,这种信号称为模拟信号。
模拟信号的优点就是直观、容易实现,但有两个明显的缺点,即保密性差和抗干扰能力差。
电信号在沿线路的传输过程中会受到外界和通信系统内部的各种噪声干扰,噪声和信号混合后难以分开,从而使通信质量下降。线路越长,噪声的积累也就越多。
12. 8条模拟信道采用TDM复用成1条数字信道,TDM帧的结构为8字节加1比特同步开销(每条模拟信道占1个字节)。若模拟信号频率范围为10~16kHz. 样本率至少为(11)样本/秒,此时数字信道的数据速率为(12)Mbps。
A. 0.52
B. 0.65
C. 130
D. 2.08
设信道带宽为3000Hz,信噪比为30dB,则信道可达到的最大数据速率约为(15) b/s。
设信道带宽为4000Hz,信噪比为30dB,按照香农定理,信道容量为(15)。
传输信道频率范围为10MHz~16MHz,采用QPSK调制,支持的最大速率为( )Mbps。
13. 在异步传输中,1位起始位,7位数据位,2位停止位,1位校验位,每秒传输200字符,采用曼彻斯特编码,有效数据速率是(13)kb/s, 最大波特率为(14)Baud。
A. 1.2
B. 1.4
C. 2.2
D. 2.4
设信道带宽为3400Hz,采用PCM编码,采样周期为125us,每个样本量化为128个等级,则信道的数据速率为(19).
在各种xDSL技术中,能提供上下行信道非对称传输的是(18),
xDSL技术中,能提供上下行信道非对称传输的是(39)。
曼彻斯特编码是一种双相码。上图中,用高电平到低电平的转换边表示0;用低电平到高电平的转换边表示1;位中间的电平转换边既表示数据代码,也作为定时信号使用。这种编码用在以太网中。
编码是指将量化后的样本值变成相应的二进制代码。通常,当量化级为N时,二进制位数为log2N。
例如,对声音数字化时,由于话音的最高频率是4kHz,所以采样速率是8kHz。对话音样本的量化用128个等级,因而每个样本用7位二进制数字表示。在数字信道上传输的速率是7×8000=56kb/s。
异步传输意味着传输的双方不需要使用某种方式来“对时”,所以它并不适合传送很长的数据,数据是按单个的字符传送的,每个字符被加上开始位和停止位,有时还会加上校验位。在不传输字符时,线路为空闲状态。传输时,这些位按照次序经过媒体,接收方在线路空闲时收到开始位,就开始了接收数据的过程。当收到停止位,意味着线路再次空闲,等待下一个字符的到来。
异步传输最重要的特点是简单而廉价,由于有开始位和停止位的存在,对双方的时钟精确度要求并不高。计算机的串口就是典型的异步传输的应用。
异步传输中发送和接收时钟不一致导致常常会引发差错,其中差错的示意图如下图所示。
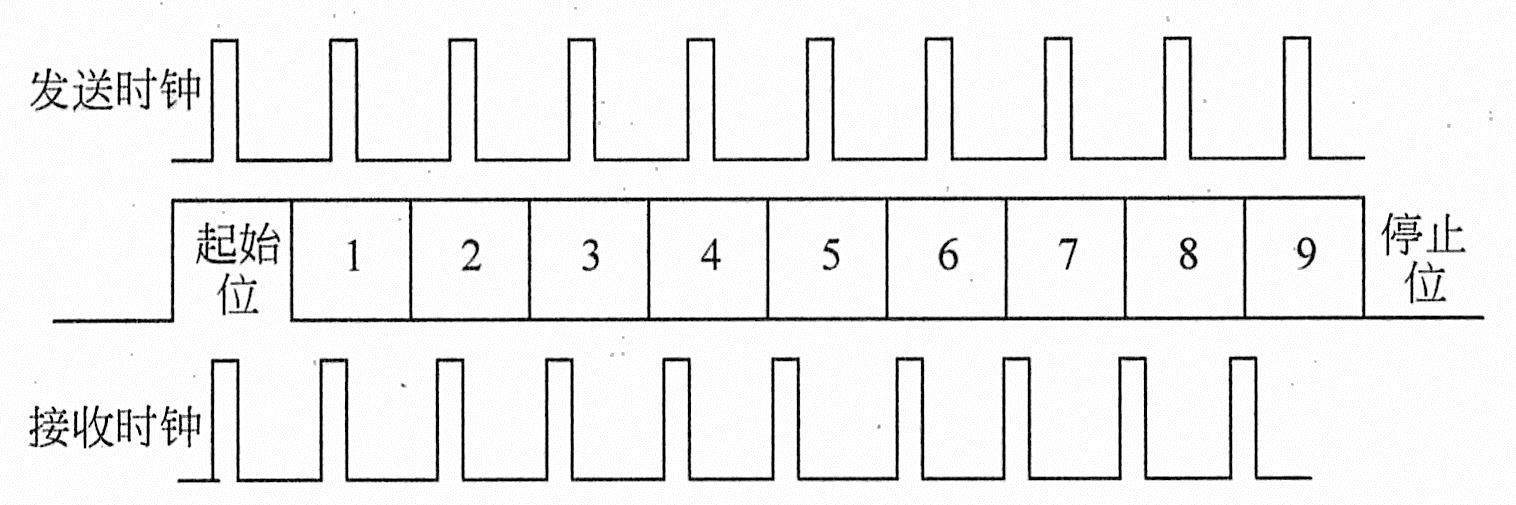
异步传输发送和接收时钟不一致导致差错的示意图
因此可以看出异步传输很重要的工作之一,就是进行数据同步,这也是异步传输的主要缺点。由于异步传输额外的开销比较大,在没有校验位的情况下,用于同步的数据也要占传输总数据的20%,不利于进行高速、大量的数据传输。
14. 在异步传输中,1位起始位,7位数据位,2位停止位,1位校验位,每秒传输200字符,采用曼彻斯特编码,有效数据速率是(13)kb/s, 最大波特率为(14)Baud。
A. 700
B. 2200
C. 1400
D. 4400
设信号的波特率为1000Baud,信道支持的最大数据速率为2000b/s,则信道采用的调制技术为( )。
在地面上相隔2000km的两地之间通过卫星信道传送4000比特长的数据包,如果数据速率为64kb/s,则从开始发送到接收完成需要的时间是..
在相隔2000km的两地间通过电缆以4800b/s的速率传送3000比特长的数据包,从开始发送到接收完数据需要的时间是(19),如果用50Kb/s的..
A. 停等ARQ
B. 后退N帧ARQ
C. 选择重发ARQ
D. 最大限额ARQ
在采用CRC校验时,若生成多项式为G(X)=X5+X2+X+1,传输数据为1011110010101时,生成的帧检验序列为(28..
循环冗余校验标准CRC-16的生成多项式为G(x)=x16+x15+x2+1,它产生的校验码是(13)位。接收端发现..
一对有效码字之间的海明距离是(15)。如果信息为10位,要求纠正1位错,按照海明编码规则,最少需要增加的校验位是(16)位。
利用差错检测技术自动地对丢失帧和错误帧请求重发的技术称为ARQ(Automatic Repeat reQuest)技术。
1)停等ARQ协议
停等ARQ协议是停等流控技术和自动请求重发技术的结合。发送站发送一帧后必须等待应答信号,收到肯定应答信号ACK后继续发送下一帧;收到否定应答信号NAK后重发该帧;在一定的时间间隔内没有收到应答信号也必须重发。
2)连续ARQ协议
连续ARQ协议是滑动窗口技术和自动请求重发技术的结合。由于窗口尺寸开到足够大时,帧在线路上可以连续地流动,因此又称其为连续ARQ协议。根据出错帧和丢失帧处理上的不同,连续ARQ协议又分选择重发ARQ协议和后退N帧ARQ协议。
选择重发ARQ协议只重发出错的帧,其后面的帧被缓存。采用ARQ协议时,窗口的最大值应为帧编号数的一半,即W发=W收≤2k-1。
后退N帧ARQ协议是从出错处重发已发过的N个帧。窗口的大小限制为W≤2k-1。
微波技术通常要求在视距范围之内,而卫星通信技术则可以有效地解决这一问题。从某种意义上说,可以将通信卫星想象为天空中的一个大的微波中继器。
在通信卫星上,通常包含了几个异频发射应答器,它们分别监听频谱中的一部分,并对接收到的信号进行放大,然后在另一个频率上将放大的信号重新发射出去(防止与接收的信号发生干扰)。由于地球是球面的,因此卫星离地球越近,其覆盖范围也就越小,要实现覆盖全球的卫星总数也就越多。可以安全放置卫星的区域包括三类,如下表所示。

可以安全放置卫星的区域类型
下面就逐一简要地进行说明。
(1)地球同步轨道卫星(Geosynchronous Orbit,GEO)。
.轨道槽位:ITU分配,即卫星运行的轨道。
.频率:这也是争夺最激烈的部分,如下表所示。
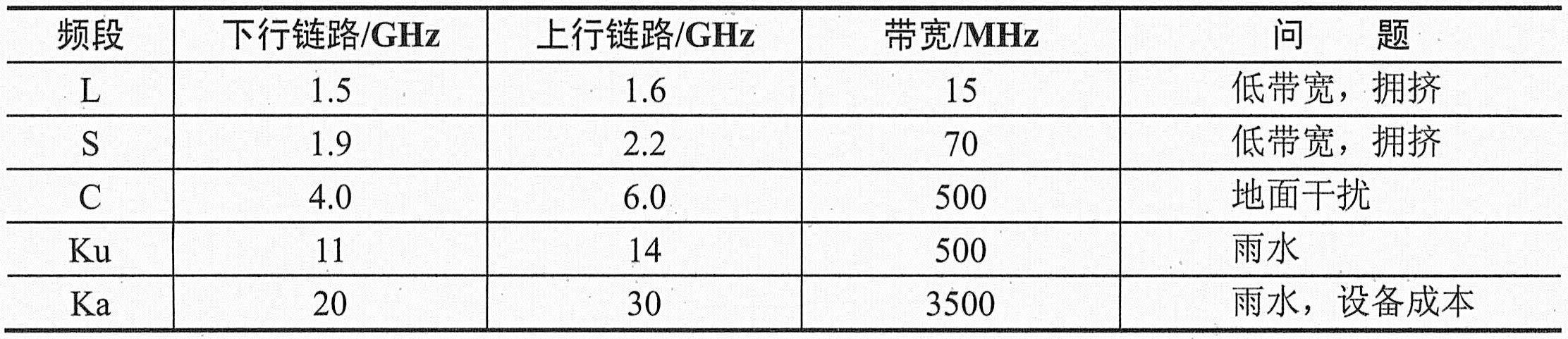
GEO频率
.典型系统:VSAT(小孔终端,低成本的微型站),将通过中心站进行数据的转发例如,VSAT-2要发信息给VSAT-4,则先通过通信卫星站发到中心站,然后再由中心站通过卫星发送给VSAT-4,如下图所示。

使用中心站的卫星通信
(2)中间轨道卫星(Middle Earth Orbit,MEO):最典型的应用是由24颗卫星组成的全球卫星定位系统,很少用于通信领域。
(3)低轨道卫星(Least Earth Orbit,LEO):优点是延迟时间短,缺点则是卫星需要较多,最有代表性的LEO通信卫星系统有三个。
.铱星计划:由66颗卫星组成(原计划是77颗),覆盖全球的语音通信系统,轨道位于750 km上。
.Globalstar:由48颗卫星组成,它的最大特点是不仅可以通过地区交换,还可以通过卫星直接进行交换,它也是一个语音通信系统。
.Teledesic:定位于提供全球化、高带宽的Internet服务,计划达到为成千上百万的并发用户提供上行100Mb/s,下行720Mb/s的带宽,而每个用户则使用一个小、固定、VSAT类型的天线完成。它的设计是使用288颗卫星(现在实际上是使用30颗),排列成为12个平面,轨道位于1350 km。
16. 以下千兆以太网标准中,支持1000m以上传输距离的是( )。
A. 1000BASE-T
B. 1000BASE-CX
C. 100BASE-SX
D. 1000BASELX
在以太网中出于对( )的考虑,需设置数据帧的最小帧。
在快速以太网物理层标准中,使用两对5类无屏蔽双绞线的是(60)。
采用CSMA/CD协议的基带总线,其段长为1000m,中间没有中继器,数据速率为10Mb/s,信号传播速度为200m/μs,为了保证在发送期间能..
1000Mb/s以太网的传输速率更快,作为主干网提供无阻塞的数据传输服务。1996年3月,IEEE成立了802.3z工作组,最终制定的1Gb/s的以太网标准包括以下内容。
.1000Base-CX:使用两对STP和9芯D型连接器,最大段长为25m。
.1000Base-LX:使用一对62.5μm或50μm多模光纤,最大段长为550m;或使用9μm的单模光纤,最大段长为5km。
.1000Base-SX:使用一对62.5μm的多模光纤,最大段长为550m;或使用一对50μm的多模光纤,最大段长为525m。
.1000Base-TX:使用一对五类UTP,最大段长为100m。
实现1000Mb/s的数据速率,需要采用许多新的数据处理技术。首先是最小帧长需要扩展,以便在半双工的情况下增加跨距。另外,802.3z还定义了一种帧突发方式(Frame Bursting),使得一个站可以连续发送多个帧。最后物理层编码也采用了与10Mb/s不同的编码方式,即4B/5B或8B/9B编码法。
以太网是最早使用的局域网,也是目前使用最广泛的网络产品。以太网有10Mb/s、100Mb/s、1000Mb/s、10Gb/s等多种速率。
以太网传输介质
以太网比较常用的传输介质包括同轴电缆、双绞线和光纤三种,以IEEE 802.3委员会习惯用类似于10Base-T的方式进行命名。这种命名方式由三个部分组成:
(1)10:表示速率,单位是Mb/s。
(2)Base:表示传输机制,Base代表基带,Broad代表宽带。
(3)T:传输介质,T表示双绞线、F表示光纤、数字代表铜缆的最大段长。
传输介质的具体命名方案如下表所示,了解这些知识是十分必要的。

以太网传输介质表

以太网时隙
时间被分为离散的区间称为时隙(Slot Time)。帧总是在时隙开始的一瞬间开始发送。一个时隙内可能发送0,1或多个帧,分别对应空闲时隙、成功发送和发生冲突的情况。
设置时隙理由
在以太网规则中,若发生冲突,则必须让网上每个主机都检测到。信号传播整个介质需要一定的时间。考虑极限情况,主机发送的帧很小,两冲突主机相距很远。在A发送的帧传播到B的前一刻,B开始发送帧。这样,当A的帧到达B时,B检测到了冲突,于是发送阻塞信号。B的阻塞信号还没有传输到A,A的帧已发送完毕,那么A就检测不到冲突,而误认为已发送成功,不再发送。由于信号的传播时延,检测到冲突需要一定的时间,所以发送的帧必须有一定的长度。这就是时隙需要解决的问题。
在最坏情况下,检测到冲突所需的时间
若A和B是网上相距最远的两个主机,设信号在A和B之间传播时延为τ,假定A在t时刻开始发送一帧,则这个帧在t+τ时刻到达B,若B在t+τ-ε时刻开始发送一帧,则B在t+τ时就会检测到冲突,并发出阻塞信号。阻塞信号将在t+2τ时到达A。所以A必须在t+2τ时仍在发送才可以检测到冲突,所以一帧的发送时间必须大于2τ。
按照标准,10Mb/s以太网采用中继器时,连接最大长度为2500m,最多经过4个中继器,因此规定对于10Mb/s以太网规定一帧的最小发送时间必须为51.2μs。51.2μs也就是512位数据在10Mb/s以太网速率下的传播时间,常称为512位时。这个时间定义为以太网时隙。512位=64字节,因此以太网帧的最小长度为64字节。
冲突发生的时段
(1)冲突只能发生在主机发送帧的最初一段时间,即512位时的时段。
(2)当网上所有主机都检测到冲突后,就会停发帧。
(3)512位时是主机捕获信道的时间,如果某主机发送一个帧的512位时,而没有发生冲突,以后也就不会再发生冲突了。
提高传统以太网带宽的途径
以往被淘汰、传统的以太网是以10Mb/s速率半双工方式进行数据传输的。随着网络应用的迅速发展,网络的带宽限制已成为进一步提高网络性能的瓶颈。提高传统以太网带宽的方法主要有以下3种。
交换以太网
以太网使用的CSMA/CD是一种竞争式的介质访问控制协议,因此从本质上说它在网络负载较低时性能不错,但如果网络负载很大时,冲突会很常见,因此导致网络性能的大幅下降。为了解决这一瓶颈问题,“交换式以太网”应运而生,这种系统的核心是使用交换机代替集线器。交换机的特点是,其每个端口都分配到全部10Mb/s的以太网带宽。若交换机有8个端口或16个端口,那么它的带宽至少是共享型的8倍或16倍(这里不包括由于减少碰撞而获得的带宽)。
交换以太网能够大幅度的提高网络性能的主要原因是:
.减少了每个网段中的站点的数量;
.同时支持多个并发的通信连接。
网络交换机有三种交换机制:直通(Cut through)、存储转发(Store and forward)和碎片直通(Fragment free Cut through)。
交换式以太网具有几个优点:第一,它保留现有以太网的基础设施,保护了用户的投资;第二,提高了每个站点的平均拥有带宽和网络的整体带宽;第三,减少了冲突,提高了网络传输效率。
全双工以太网
全双工技术可以提供双倍于半双工操作的带宽,即每个方向都支持10Mb/s,这样就可以得到20Mb/s的以太网带宽。当然这还与网络流量的对称度有关。
全双工操作吸引人的另一个特点是它不需要改变原来10Base-T网络中的电缆布线,可以使用和10Base-T相同的双绞线布线系统,不同的是它使用一对双绞线进行发送,而使用另一对进行接收。这个方法是可行的,因为一般10Base-T布线是有冗余的(共4对双绞线)。
高速服务器连接
众多的工作站在访问服务器时可能会在服务器的连接处出现瓶颈,通过高速服务器连接可以解决这个问题。使用带有高速端口的交换机(如24个10Mb/s端口,1个100Mb/s或1000Mb/s高速端口),然后再把服务器接在高速端口上并使用全双工操作。这样服务器就可以实现与网络200Mb/s或2000Mb/s的连接。
以太网的帧格式
以太网帧的格式如下图所示,包含的字段有前导码、目的地址、源地址、数据类型、发送的数据,以及帧校验序列等。这些字段中除了数据字段是变长以外,其余字段的长度都是固定的。

以太网的帧结构
注:字段的长度以字节为单位
前导码(P)字段占用8字节。
目的地址(DA)字段和源地址(SA)字段都是占用6字节的长度。目的地址用于标识接收站点的地址,它可以是单个的地址,也可以是组地址或广播地址,当地址中最高字节的最低位设置为1时表示该地址是一个多播地址,用十六进制数可表示为01:00:00:00:00:00,假如全部48位(每字节8位,6字节即48位)都是1时,该地址表示是一个广播地址。源地址用于标识发送站点的地址。
类型(Type)字段占用两字节,表示数据的类型,如0x0800表示其后的数据字段中的数据包是一个IP包,而0x0806表示ARP数据包,0x8035表示RARP数据包。
数据(Data)字段占用46~1500个不等长的字节数。以太网要求最少要有46字节的数据,如果数据不够长度,必须在不足的空间插入填充字节来补充。
帧校验序列(FCS)字段是32位(即4字节)的循环冗余码。
17. 综合布线系统中,用于连接各层配线室,并连接主配线室的子系统为( )。
A. 工作区子系统
B. 水平子系统
C. 垂直子系统
D. 管理子系统
建筑物综合布线系统中工作区子系统是指(56)。
EIA/TIA-568标准规定,在综合布线时,如果信息插座到网卡之间使用无屏蔽双绞,布线距离最大为(67) m。
建筑物综合布线系统中的干线子系统是(66),水平子系统是(67)。
综合布线系统(Premises Distributed System,PDS)是一种集成化通用传输系统,是在楼宇和园区范围内,利用双绞线或光缆来传输信息,可以连接电话、计算机、会议电视和监视电视等设备的结构化信息传输系统。
综合布线系统使用标准的双绞线和光纤,支持高速率的数据传输。这种系统使用物理分层星型拓扑结构,积木式、模块化设计,遵循统一标准,使系统的集中管理成为可能,也使每个信息点的故障、改动或增删不影响其他的信息点,使安装、维护、升级和扩展都非常方便,并节省了费用。
综合布线系统可分为6个独立的系统(模块),如下图所示。

综合布线系统
(1)工作区子系统。工作区子系统由终端设备连接到信息插座之间的设备组成,包括信息插座、插座盒、连接跳线和适配器。
(2)水平区子系统(水平干线子系统、水平子系统)。水平区子系统应由工作区用的信息插座,以及楼层分配线设备至信息插座的水平电缆、楼层配线设备和跳线等组成。一般情况下,水平电缆应采用4对双绞线电缆。在水平子系统有高速率应用的场合,应采用光缆,即光纤到桌面。水平子系统根据整个综合布线系统的要求,应在二级交接间、交接间或设备间的配线设备上进行连接,以构成电话、数据、电视系统和监视系统,并方便进行管理。
(3)管理间子系统。管理间子系统设置在楼层分配线设备的房间内。管理间子系统应由交接间的配线设备,以及输入输出设备等组成,也可应用于设备间子系统中。管理间子系统应采用单点管理双交接。交接场的结构取决于工作区、综合布线系统规模和所选用的硬件。在管理规模大、复杂、有二级交接间时才设置双点管理双交接。在管理点,应根据应用环境用标记插入条来标出各个端接场。
(4)垂直干线子系统(垂直子系统、干线子系统)。通常是由主设备间(如计算机房、程控交换机房)提供建筑中最重要的铜线或光纤线主干线路,是整个大楼的信息交通枢纽。一般它提供位于不同楼层的设备间和布线框间的多条连接路径,也可连接单层楼的大片地区。
(5)设备间子系统。设备间是在每一幢大楼的适当地点设置进线设备,进行网络管理及管理人员值班的场所。设备间子系统应由综合布线系统的建筑物进线设备、电话、数据、计算机和不间断电源等各种主机设备及其保安配线设备等组成。
(6)建筑群子系统(楼宇子系统)。建筑群子系统将一栋建筑的线缆延伸到建筑群内的其他建筑的通信设备和设施。它包括铜线、光纤,以及防止其他建筑电缆的浪涌电压进入本建筑的保护设备。在设计建筑群子系统时,应考虑地下管道铺设的问题。
在综合布线系统的技术指标和质量参数方面,要遵循《综合布线系统工程设计规范》(GB50311—2007)和《综合布线系统工程验收规范》(GB50312—2007)的要求。考生要熟记这两个规范里的技术要求和参数。软考在线教育软考学院(www.csairk.com)的法律法规栏目有该规范的完整文本,在此不再转载。
1.概念及相关标准
综合布线系统(Premises Distribution System,PDS)是楼宇和园区范围内,在统一的传输介质上建立的可以连接电话、计算机、会议电视和监视电视等设备的结构化信息传输系统。
目前在综合布线领域被广泛遵循的标准是EIA/TIA-568A。在此标准中把综合布线系统分为6个子系统:建筑群子系统、设备间子系统、垂直干线子系统、管理子系统、水平子系统和工作区子系统,如下图所示。
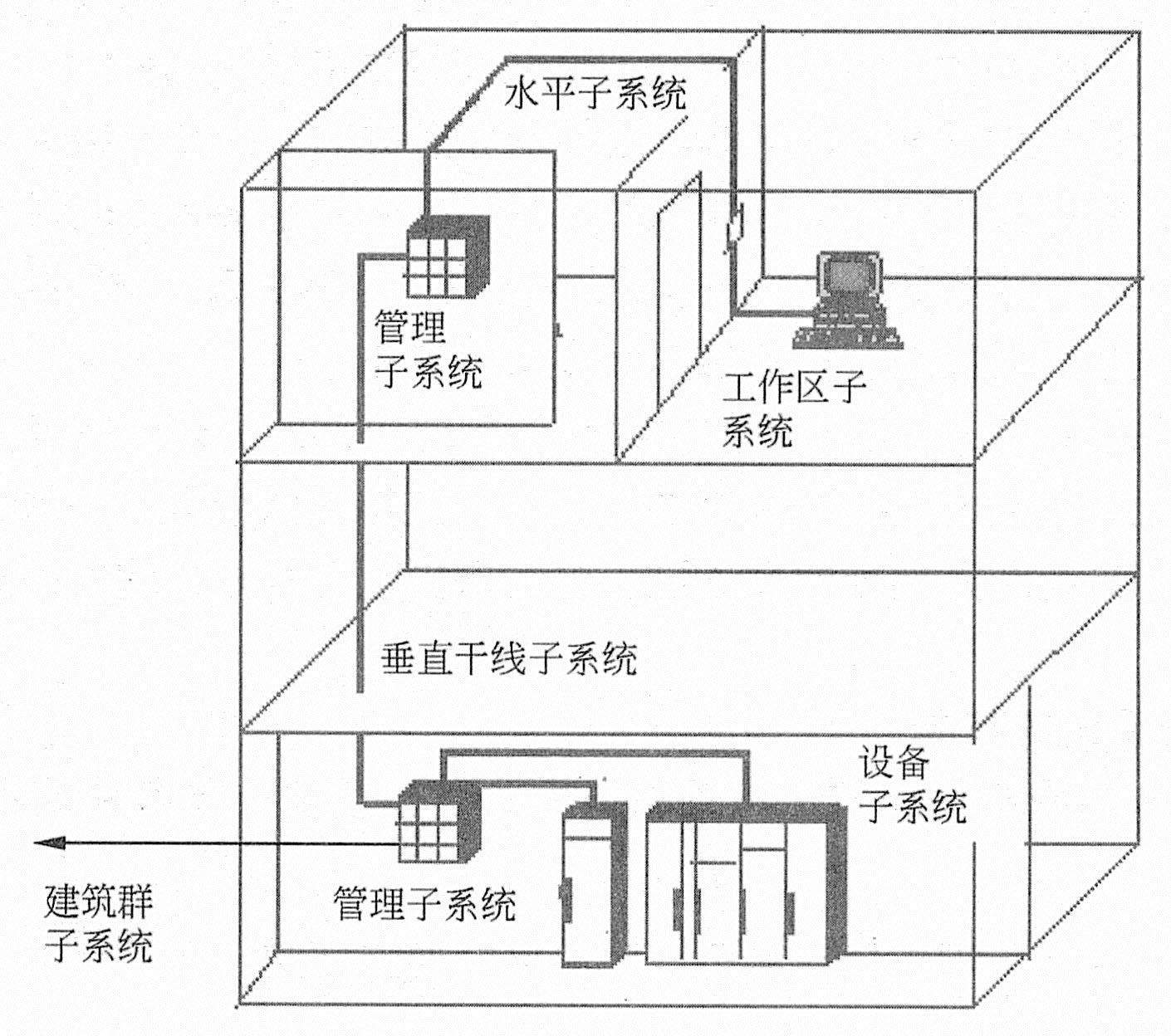
EIA/TIA-568A标准中描述的综合布线系统
各子系统的功能如下:
.工作区子系统:实现工作区终端设备与水平子系统之间的连接,由终端设备连接到信息插座的连接线缆组成。工作区常用设备是计算机、网络集散器(Hub或Mau)、电话、报警探头、摄像机、监视器和音响等。
.水平子系统:实现信息插座和管理子系统(跳线架)间的连接,将用户工作区引至管理子系统:系统中常用的传输介质是4对UTP(非屏蔽双绞线),它能支持大多数现代通信设备。如果需要某些宽带应用时,可以采用光缆。信息出口采用插孔为ISDN8芯(RJ45)的标准插口,每个信息插座都可灵活地运用,并根据实际应用要求可随意更改用途。
.管理子系统:由交连、互连配线架组成。管理点为连接其他子系统提供连接手段。交连和互连允许将通信线路定位或重定位到建筑物的不同部分,以便能更容易地管理通信线路,使在移动终端设备时能方便地进行插拔。互连配线架根据不同的连接硬件分为楼层配线架(箱)IDF和总配线架(箱)MDF,IDF可安装在各楼层的干线接线间,MDF一般安装在设备机房。
.垂直干线子系统:实现计算机设备、程控交换机(PBX)、控制中心与各管理子系统间的连接,是建筑物干线电缆的路由。该子系统通常是两个单元之间,特别是在位于中央点的公共系统设备处提供多个线路设施。系统由建筑物内所有的垂直干线多对数电缆及相关支撑硬件组成,以提供设备间总配线架与干线间楼层配线架之间的干线路由。常用介质是大对数双绞线电缆和光缆。
.设备子系统:由设备间中的电缆、连接器和有关的支撑硬件组成,作用是将计算机、PBX、摄像头、监视器等弱电设备互连起来并连接到主配线架上。设备包括计算机系统、网络集线器(Hub)、网络交换机(Switch)、程控交换机(PBX)、音响输出设备、闭路电视控制装置和报警控制中心等。
.建筑群子系统:将一个建筑物的电缆延伸到建筑群的另外一些建筑物中的通信设备和装置上,是结构化布线系统的一部分,支持提供楼群之间通信所需的硬件。它由电缆、光缆和入楼处的过流过压电气保护设备等相关硬件组成,常用介质是光缆。
2.综合布线系统的范围
综合布线的范围应根据建筑工程项目范围来定,主要有单幢建筑和建筑群体两种范围。
.单幢建筑:一般是指在整幢建筑内部敷设的通信线路,还应包括引出建筑物的通信线路。
.建筑群体:综合布线系统工程范围除包括每幢建筑内的通信线路外,还需包括各幢建筑之间相互连接的通信线路。
上述范围是从基本建设和工程管理的要求考虑的,与今后的业务管理和维护职责等的划分范围有可能不同。因此,综合布线系统的具体范围应根据网络结构、设备布置和维护办法等因素来划分。
3.综合布线系统的适用场合和服务对象
综合布线系统的适用场合和服务对象有以下几类:
.商业贸易类型:如商务贸易中心、金融机构、高级宾馆饭店、股票证券市场和高级商城大厦等高层建筑。
.综合办公类型:如政府机关、群众团体、公司总部等办公大厦以及办公、贸易和商业兼有的综合业务楼和租赁大楼。
.交通运输类型:如航空港、火车站、长途汽车客运枢纽站、江海港区城市公共交通指挥中心等。
.新闻机构类型:如广播电台、电视台和新闻通信及报社业务楼等。
.其他重要建筑类型:如医院、急救中心、科学研究机构、高等院校和工业企业及气象中心的高科技业务楼等。
A. 信号反射引起的衰减
B. 传输距离引起的发射端的能量与接收端的能量差
C. 光信号通过活动连接器之后功率的减少
D. 传输数据时线对间信号的相互泄漏
以下关于光纤的说法中,错误的是( )。
以下关于光纤通信的叙述中,正确的是(13)。
关于单模光纤,下面的描述中错误的是( )。
测试工作伴随着整个网络工程的全过程,无论是布线安装还是系统调试,都需要进行反复的测试和确定。
测试计划
测试计划应包括下列5个方面的内容。
1)简要说明
简要说明包括工程的概况和需要达到的主要指标。
2)测试内容
测试内容包括逐项列出的测试步骤、名称、内容和预期达到的目标。
3)测试清单
测试清单是对每项测试内容列出测试的部位和参与测试的单位,包括进度的安排、测试工具和相应的条件(设备和软件等)。
4)测试设计说明
测试设计说明是对每项测试内容的测试设计进行考虑,包括测试的控制方式、输入条件和预期的输出结果。
5)评价准则
评价准则用来说明测试所能检查的范围及其局限性,以及用来判断测试工作是否通过的评价尺度,包括合理的输出结果、测试输出结果与预期输出结果之间容许出现的偏差范围。
测试工作完成后,应提交一份测试分析报告。该报告主要包括下列内容:概要说明、测试结果、结论、原因分析、建议和评价。
网络测试
网络测试是对网络设备、网络系统以及网络对应用的支持进行检测,以展示和证明网络系统能否满足用户在性能、安全性、易用性、可管理性等方面需求的测试。网络测试的实施一般包括以下环节。
◆根据测试目的,确定测试目标。
◆在对相关网络技术和实现细节透彻掌握的基础上,设计测试方案。
◆建立网络负载模型。
◆配置测试环境,包括测试工具的选择及必要的测试工具的研发。
◆采集和整理数据。
◆分析和解释数据。
◆准确、直观、形象地表示测试结果。
网络测试包括网络设备测试、网络系统测试和网络应用测试3个层次。
1)网络设备测试
网络设备测试主要包括以下几个方面:功能测试、可靠性和稳定性测试、一致性测试、互操作性测试和性能测试等。
(1)功能测试用来验证产品是否具有设计的每一项功能。
(2)可靠性和稳定性测试往往通过加重负载的办法来分析和评估系统的可靠性和稳定性。
(3)一致性测试用来验证产品的各项功能是否符合标准。
(4)互操作性测试用来考查一个网络产品是否能在不同厂家的多种网络产品互联的网络环境中很好地工作。网络产品不同于其他产品的最大特点是必须符合标准,不同的网络产品之间要能互操作。
(5)性能测试的主要目标是分析产品在各种不同的配置和负载条件下的容量和对负载的处理能力,如交换机的吞吐量、转发延迟等。
典型的网络设备性能测试方法有两种:第一种是将设备放在一个仿真的网络环境中进行测试,第二种是使用专用的网络测试设备对产品进行测试。
2)网络系统测试和网络应用测试
网络系统测试除了普通意义上的物理连通性、基本功能和一致性的测试以外,主要包括网络系统的规划验证测试、网络系统的性能测试、网络系统的可靠性与可用性的测试与评估、网络流量的测量和模型化等。
(1)网络系统的规划验证测试主要采用的两个基本手段是模拟和仿真。
◆模拟是通过软件的办法,建立网络系统的模型,模拟实际网络的运行。通过设定各种配置和参数模拟系统的行为,对系统的容量、性能以及对应用的支撑程度给出定量的评价。这对于大型网络的规划设计是不可缺少的环节。
◆仿真是指通过建立典型的试验环境,仿真实际的网络系统。规划验证测试的目的在于分析所采用的网络技术的可行性和合理性,网络设计方案的合理性,所选网络设备的功能、性能等是否能够合理地、有效地支持网络系统的设计目标。
(2)网络系统的性能测试是指通过对网络系统的被动测量和主动测量来确定系统中站点的可达性、网络系统的吞吐量、传输速率、带宽利用率、丢包率、服务器和网络设备的响应时间、产生最大网络流量的应用和用户,以及服务质量等。此项工作同时可以发现系统的物理连接和系统配置中的问题,确定网络瓶颈,发现网络问题。测试设备记录一段时间内的网络流量,实时和非实时地分析数据。被动测量不干涉网络的正常工作,不影响网络的性能。主动测量向网络发送特定类型的数据包或网络应用,以便分析系统的行为。
(3)网络系统的可靠性与可用性的测试与评估。系统可用性取决于系统的可靠性(MTTF)及可维护性(MTTR)的高低,其中可靠性是指系统服务多久不中断,可维护性是指服务中断后多久可恢复。三者之间满足如下关系:
System Usability=MTTF/(MTTF+MTTR)*100%
其中,MTTF是指平均无故障时间,MTTR是指平均故障修复时间,MTBF是指平均故障间隔时间。有MTBF=MTTF+MTTR,故
System Usability=MTTF/MTBR*100%
(4)网络流量的测量和模型化。网络流量的测量和模型化对于分析网络性能和带宽的利用率、指导网络流量管理、开发高效的网络应用十分重要。这方面的工作主要有以下几个方面。
◆产生已知特征的流量,使该流量沿网络传播,最后回到测试仪。记录和分析流量特性的任何改变(如延迟漂移)。
◆对链路总体流量的测量和传输时间、吞吐量、带宽利用率等进行分析。
◆分析特定流量的特征和提供的QoS;收集一个时间段内的测量数据进行分析,分析流量沿网络传播过程中流量特征的变化和网络流量的统计行为,建立流量模型。
(5)网络应用层次上的测试则主要体现在测试网络对应用的支持水平,如网络应用的性能和服务质量的测试等。例如,部署基于IP的语音传输VoIP时,最直接的问题是网络中的交换机和路由器设备能否有效地支持语音传输,网络能支持多大的语音流量、多少个语音通道;如果网络支持VoIP,对网络的其他业务特别是关键业务,会产生什么样的影响;网络是否支持服务质量QoS。这些问题都需要通过网络应用测试来回答。
(6)网络系统测试的核心工具是协议分析仪。这是一种专用的网络测试设备,它能够连接到网络上,产生并向网络发送数据,捕捉网络数据,分析数据。协议分析仪一般具有网络监测、故障查找、协议解码和流量产生等功能。
网络设备安全性测试
现在有很多新型网络设备尤其是网络边缘路由器增加了防护功能,阻止了人为、故意的网络攻击。然而,提供的防护会不会对正常数据转发造成影响?有什么样的影响?这些很难从理论上估计,需要进行必要的网络设备安全性测试。
本节提到的测试项,主要是验证网络设备所提供的基本安全功能,并检测这些安全功能项对网络设备运行造成的影响。这些测试项分为访问列表测试和DOS攻击测试两大类。
1)访问列表测试
访问列表测试用于检测边缘路由器的访问列表能否起到防火墙的作用,访问列表测试控制网络传输过滤数据报文,访问列表测试阻止或允许数据报文通过网络接口。过滤依据可以是源地址、目的地址和上层协议号。边缘路由器通过将进入或离开的数据报文与访问列表中的过滤项进行比较,决定允许或阻止数据报文通过。对于边缘路由器能提供的访问列表容量,以及不断变化的访问列表对数据转发的影响都要进行测试。
2)DOS攻击测试
DOS攻击测试用于检测边缘路由设备抵抗"拒绝服务(DOS)攻击"的能力。当设备由于伪造的服务请求和虚假的传输而变得非常繁忙时,就无法响应正常的服务请求,从而造成损失。DOS攻击测试考验网络设备检测并阻止某种特定攻击的能力,并在检测受到某种攻击、设备超负荷运行的情况下,正常传输转发性能所受的影响。
具体的网络设备安全性测试项目如下。
◆访问列表性能测试。
◆虚假源地址攻击测试。
◆LAND攻击检查。
◆SYN风暴检查。
◆Smurf攻击检查。
◆Ping风暴检查。
◆Teardrop攻击检查。
◆Ping to Death检查。
性能测试
性能测试包括可靠性测试、功能/特性测试、吞吐量测试、衰减测试、容量规划测试、响应时间测试、可接受性测试和网络瓶颈测试等。
1)可靠性测试
可靠性测试是使被测网络在较长时间内(通常是24~72小时)经受较大负载,通过监视网络中发生的错误和出现的故障,验证在高强度环境中网络系统的存活能力,也就是它的可靠性。可靠性测试可作为接受性测试的一部分,在产品评估测试中可作为比较测试或作为产品升级进行的衰减测试的一部分。采用的负载模式很重要,越贴近真实负载模式越好。可靠性测试中使用网络分析仪监控网络运行,捕获网络错误。
通常在较长时间段内和持续负载下,不同网络具有不同级别的存活度。如果测试时间足够长、负载足够大,所有可靠性测试最终都会失败。
可靠性测试应用于网络生命周期中的以下3个阶段。
◆计划:作为产品评估测试的一部分,比较不同产品或建立要求规范。
◆开发:验证计划中的要求是否能在系统中完全实现。
◆组建:作为可接受性测试的一部分,在网络运行前进行,核实系统是否达到要求。
2)功能/特性测试
特性测试核实的是单个命令和应用程序功能,通常用较小的负载完成,关注的是用户界面、应用程序的操作以及用户与计算机之间的互操作。特性测试通常由开发人员在他们的工作台上完成,或是在一个小型网络环境下由测试人员完成。
功能测试是面向网络的,核实的是应用程序的多用户特征和在重负载下后台功能是否能正确地执行,关注的是当多个用户正在运行应用程序时,网络和文件系统或数据库服务器之间的交互。功能测试要求网络的配置和负载非常接近于运行环境下的模式。该测试可以在运行网络或独立网络实验室里完成。它只应用于网络生命周期中的以下3个阶段。
◆开发:用于核实在期望的运行模式下,在多用户环境里,应用程序的运行性能是否达到要求。
◆组建:在应用程序安装前完成,可独立进行,也可作为接受性测试的一部分,用于核实在期望的运行模式下,应用程序的运行性能是否达到要求。
◆运行:该阶段测试是在应用程序运行后进行的,如果在运行系统中遇到了问题,该阶段测试用于核实应用程序是否如最初应用时那样工作。
3)吞吐量测试
吞吐量测试和应用程序的响应时间测试相似,但检测的是每秒钟传输数据的字节数和数据报文数,而不是响应时间。它用于检测服务器、磁盘子系统、适配卡/驱动连接、网桥、路由器、集线器、交换器和通信连接。吞吐量测试用于测量网络性能、找到网络瓶颈,以及比较不同产品的性能。
吞吐量测试不使用程序脚本,它借助某些软件对网络服务器执行文件输入/输出操作来产生流量,或通过某些软件在网络上发送专门的数据报文或帧。该测试应用于网络生命周期的以下几个阶段。
◆计划:用于比较网络产品,为模拟网络节点提供运行特征和要求规范。
◆开发:用于核实网络组件以及整个网络是否达到规范要求的水平。
◆组建:可独立进行或作为可接受性测试的一部分,在网络组件或整个网络正式运行之前核实它们是否满足规范的要求。
4)衰减测试
衰减测试是将硬件或软件的新版本与当前版本在性能、可靠性和功能等方面进行比较,同时验证产品升级对网络的性能不会有不良影响。衰减测试混杂了很多为完成其他测试任务要进行的测试。衰减测试的关键是要保证被测组件应是运行网络中最关键或最脆弱的组件。
衰减测试不强调升级版的新特性。新特性测试在衰减测试之前作为功能/特征测试的一部分就已完成。尽管新产品应该解决了当前版本中的错误,但它们也经常存在一些以前没有出现过的错误,如果这些错误发生在产品的关键部分,将会引起严重问题。衰减测试不需要测试产品的所有特性,但网络用户正常运行所依靠的关键功能必须在测试之列。
衰减测试应用于网络生命周期的以下两个阶段。
◆开发:用于核实产品升级版是否能满足性能、互操作性和可靠性的要求。
◆升级:在采用升级版本之前用该项测试来比较升级版和当前版,看升级版是否和当前版一样满足性能、互操作性和可靠性的要求。
5)容量规划测试
容量规划测试用于检测当前网络中是否存在多余的容量空间。当网络承受的总负载超过网络总容量时,网络的性能或吞吐量就有可能下降,所以在网络负载接近这一临界点(网络的最大容量)前,就要根据负载增长的幅度扩充网络资源。
进行该项测试要逐渐增加网络负载,直到网络的运行性能、可接受的水平或吞吐量不断下降,达不到设计所要求的水平为止。网络运行负载和网络最大吞吐量之间的差额就是现有系统的冗余量。
容量规划测试应用于网络生命周期的以下3个阶段。
◆计划:用于估计实施该系统所需要的资源,也可用于成本分析和制定预算。
◆开发:检测系统要求的资源是否满足特定的响应时间和吞吐量的要求。
◆升级:当系统响应时间或吞吐量下降时,重新选取网络组件。
6)响应时间测试
响应时间测试用于检测系统完成一系列任务所需的时间,本项测试是用户最关心的。对于表示层,如微软的Windows,该测试是指在不同桌面之间切换或装载新负载所需的时间。在不同负载即不同实际或模拟用户的数目下运行这一实验,可对每个被测试的应用程序生成一个负载—响应时间曲线。
在应用程序测试中,可执行一系列典型网络动作的命令,如打开、读、写、查找和关闭文件,这些命令提供了最好的负载模拟。例如,对每个进行测试的工作站,检测它在几秒内能完成这些命令。
响应时间测试应用于网络生命周期的以下几个阶段。
◆计划:使用模拟应用程序进行,检测规范要求的各项网络服务。
◆开发:检验规范要求的网络服务是否正在被实现。
◆组建:在接受和组建之前,核实规范要求下的网络服务是否已经被实现。
◆运行:检测网络服务的基准和变化,这可能是针对系统质量的最好测试。
响应时间测试应该包括对系统可靠性的检测。常见的可靠性问题,如在路由器或服务器中大量丢失数据报文或由于网络组件故障引发大量坏数据报文,将严重影响网络的响应时间,因此在整个测试期间都应用网络分析仪监视系统错误。
7)可接受性测试
可接受性测试是在系统正式实施前的"试运行"。它是一个非常有效的方法,可确保新系统能提供良好而稳定的性能。和衰减测试一样,可接受性测试中也包含多项测试,如响应时间测试、稳定性测试和功能/特性测试。
可接受性测试应用于许多领域,但在安装或升级网络前应进行的网络可接受性测试则经常被忽略,而事实上,可接受性测试能为网络购买者在经济和技术上提供有力的保证和参考。
可接受性测试可以仅在新增加的部件上完成,将已存在的负载加上新增程序或新增组件可能产生的负载作为测试使用的负载。
可接受性测试应用于网络生命周期的以下两个阶段。
◆开发:在开发阶段前定期执行,用来核实要求的标准是否可行。
◆组建:在网络投入运行之前应用,用来核实系统是否满足所有要求。
8)网络瓶颈测试
通过网络瓶颈测试可以找到导致系统性能下降的瓶颈。测试中需要测试和计算系统的最大吞吐量,然后再在单个网络组件上进行该项测试,明确各组件的最大吞吐量。通过计算单个组件的最大吞吐量和系统最大吞吐量之间的差额,就能发现系统瓶颈的位置以及哪些组件有多余的容量。
系统瓶颈在不同的测试案例中出现的位置可能有所变化。例如,一个客户业务应用程序测试可能表明服务器是系统的瓶颈,而对一个电子邮件系统的测试则可能表明广域网连接才是网络的限制因素。如果可以在测试的环境中重现引起问题的负载,那么这样的测试结果对解决问题将有很大帮助。
瓶颈测试应用于网络生命周期的以下两个阶段。
◆组建:可以作为容量计划的一部分,用于帮助相关人员明确影响网络性能和响应时间的瓶颈位置。
◆运行:作为故障检测的一部分,帮助相关人员找出影响网络性能或引起系统问题的网络瓶颈。
测试报告
测试报告是整个项目的第一份供大家交流和供领导查阅的报告,人们对工程的满意程度和对工程质量的认可很大程度上来源于这份报告。通常在独立网络测试后,要总结测试数据,并基于此对测试过的同类产品进行排序;而系统内部的测试仅是得出一个简单的结论。
测试报告呈现的内容和采取的表现形式非常重要,测试报告通常包含以下信息。
◆测试目的:用一句或两句话解释本次测试的目的。
◆结论:从测试中得到的信息推荐下一步的行动。
◆测试结果总结:对测试进行总结并由此得出结论。
◆测试内容和方法:简单地描述测试是怎样进行的,应该包括负载模式、测试脚本和数据收集方法,并且要解释采取的测试方法怎样保证测试结果和测试目的的相关性,以及测试结果是否可重现。
◆测试配置:网络测试配置用图形表示出来。
测试报告的形式可以是一个简短的总结(2~4页),也可以是一个很长的书面文档(5~20页)。测试总结可以使用图形表示测试结果,如应用程序的响应时间、吞吐量和产品评估。而系统衰减性测试、配置规模测试和应用程序的功能/特性测试的测试报告还要包括更多的信息。
在非常特殊的情况下,测试报告需要长达50页。它通常包括从项目开始到结束按时间编排的所有活动,以及非常详细的问题信息和解决问题的信息。
网络测试工具
网络测试工具一般包括以下几个。
◆网络管理和监控工具。
◆建模和仿真工具。
◆服务质量和服务级别管理工具。
网络管理和监控工具(如HP公司的OpenView)能够在网络测试运行过程中提示某些问题的网络事件的出现。这些工具可以是驻留在网络设备中的应用软件。
协议分析仪也能被用于监测新设计的网络,帮助分析通信的行为、差错、利用率、效率以及广播和多播分组。
建模工具和仿真工具是更为先进的用来测试验证网络设计的工具。仿真就是在不建立实际网络的情况下,使用软件和数学模型来分析网络行为的过程。利用仿真工具,可以根据所需要测试的目标开发一个网络模型,从而估计网络性能,并对各种网络实现方法之间的差异进行比较。仿真工具使得选择比较的空间变得更大,特别适合于实现和检查一个扩展的原型系统。一个好的仿真工具往往非常昂贵,实现的技术也比较复杂,它要求开发人员不但要精通统计分析和建模技术,而且还要对计算机网络有所了解。
服务级别管理工具是一种比较新型的工具,主要用来分析网络应用的端到端性能。有些工具能够管理服务质量和服务级别,有些工具能够监控实时应用的性能,有些工具能够预测新的应用性能,有些工具可以将上述功能结合起来实现更强大的功能。
光纤全称“光导纤维”。光纤是由前香港中文大学校长高锟提出并发明的。1970年美国康宁公司首先研制出衰减为20dB/km的单模光纤,从此以后,世界各国纷纷开展光纤研制和光纤通信的研究,并得到了广泛的应用。
光纤是一种由玻璃或塑料制成的纤维,利用光的全反射原理而进行光传导的介质。是一种外包了一层保护层的、横截面积非常小的双层同心圆柱体。光纤结构如下图所示。
光纤剖面图
通常光纤与光缆两个名词会被混淆,多数光纤在使用前必须由几层保护结构包覆,包覆后的缆线即被称为光缆。
光纤传输的优点
与其他传输介质相比,光纤传输的主要优点如下:
(1)传输频带宽、通信容量大。频带的宽窄代表传输容量的大小。载波的频率越高,可以传输信号的频带宽度就越大。载波频率为48.5~300MHz的VHF(Very high frequency,甚高频)频段,带宽约250MHz。可见光的频率达100THz,比VHF频段高出一百多万倍。尽管由于光纤对不同频率的光有不同的损耗,使频带宽度受到影响,但在最低损耗区的频带宽度也可达30THz。目前单个光源的带宽只占了其中很小的一部分(多模光纤的频带约几百兆赫,好的单模光纤可达10GHz以上),采用先进的相干光通信可以在30THz范围内安排2000个光载波,进行波分复用,传输频带更宽。
(2)损耗低。在同轴电缆组成的系统中,最好的电缆在传输800MHz信号时,每公里的损耗都在40dB以上。相比之下,光导纤维的损耗则要小得多,传输1.31μm的光,每公里损耗在0.5dB以下,若传输1.55μm的光,每公里损耗更小,可达0.2dB以下。这就是同轴电缆的功率损耗的亿分之一倍,使其能传输的距离要远得多。此外,光纤传输损耗还有两个特点,一是在全部有线电视频道内具有相同的损耗,不需要像电缆干线那样必须引人均衡器进行均衡;二是其损耗几乎不随温度而变,不用担心因环境温度变化而造成干线电平的波动。
(3)电磁绝缘性能好。光纤线缆传输的是光束,而光束是不受外界电磁干扰影响的,而且光纤本身也不向外辐射信号,也不容易窃听,因此它适用于长距离的信息传输以及要求高安全的场合。
(4)中继器的间距距离大。整个通道的中继器数目可以减少,可以降低成本。根据贝尔实验室的测试,光纤线路中当数据速率为420Mb/s且距离为119km无中继器,误码率可以达到10-8。
(5)重量轻。因为光纤非常细,单模光纤芯线直径一般小于10μm,外径也只有125μm,加上防水层、加强筋、护套等,用4~48根光纤组成的光缆直径还不到13mm,比标准同轴电缆的直径47mm要小得多,加上光纤是玻璃纤维,比重小,使它具有直径小、重量轻的特点,安装十分方便。
(6)工作性能可靠。一个系统的可靠性与组成该系统的设备数量有关。设备越多,发生故障的机会越大。因为光纤系统包含的设备数量少(不像电缆系统那样需要几十个放大器),可靠性自然也就高,加上光纤设备的寿命都很长,无故障工作时间达50万~75万小时,其中寿命最短的是光发射机中的激光器,最低寿命也在10万小时以上。故一个设计良好、正确安装调试的光纤系统的工作性能是非常可靠的。
(7)成本不断下降。目前,有人提出了新摩尔定律,也叫做光学定律(Optical Law)。该定律指出,光纤传输信息的带宽,每6个月增加1倍,而价格降低1倍。光通信技术的发展,为Internet宽带技术的发展奠定了非常好的基础。这就为大型有线电视系统采用光纤传输方式扫清了最后一个障碍。由于制作光纤的材料(石英)来源十分丰富,随着技术的进步,成本还会进一步降低;而电缆所需的铜原料有限,价格会越来越高。显然,今后光纤传输将占绝对优势。
光纤通信原理
实际上,如果不是利用光全反射的原理,光纤传输系统会由于光纤的漏光而变得没有实际利用价值。当光线经过两种不同折射率的介质进行传播时(如从玻璃到空气),光线会发生折射,如下图(a)所示。假定光线在玻璃上的入射角为α1时,则在空气中的折射角为β1。折射量取决于两种介质的折射率之比。当光线在玻璃上的入射角大于某一临界值时,光线将完全反射回玻璃,而不会射入空气,这样,光线将被完全限制在光纤中,而且几乎无损耗地向前传播,如下图(b)所示。

光折射原理
在上图(b)中仅给出了一束光在玻璃内部全反射传播的情况。实际上,任何以大于临界值角度入射的光线,在不同介质的边界都将按全反射的方式在介质内传播,而且不同频率的光线在介质内部将以不同的反射角传播。
光纤的分类
根据光纤纤芯直径的粗细,可将光纤分为多模光纤(Multi-mode Fiber,MMF)和单模光纤(Single-mode Fiber,SMF)两种。如果光纤纤芯的直径较粗,则当不同频率的光信号(实际上就是不同颜色的光)在光纤中传播时,就有可能在光纤中沿不同传播路径进行传播,将具有这种特性的光纤称为多模光纤。如果将光纤纤芯直径一直缩小,直至光波波长大小的时候,则光纤此时如同一个波导,光在光纤中的传播几乎没有反射,而是沿直线传播,这样的光纤称为单模光纤。
(1)单模光纤。单模光纤的纤芯直径很小,在给定的工作波长上只能以单一模式传输,传输频带宽,传输容量大。单模光纤的芯径为8~10μm,包层直径为125μm;使用的光波波长为1310nm、1550nm。
(2)多模光纤。多模光纤是在给定的工作波长上能以多个模式同时传输的光纤。多模光纤的纤芯直径较粗一般为50~200μm,包层直径为125~230μm;使用的光波波长为850nm、1300nm。
单模光纤的造价很高,且需要激光作为光源,但其无中继传输距离非常远,且能获得非常高的数据传输速率,一般用于广域网主干线路上。多模光纤相对来说无中继传播距离要短些,而且数据传输速率要小于单模光纤;但多模光纤的价格便宜一些,并且可以用发光二极管作为光源,多模光纤一般用于局域网组网时的传输介质。单模光纤与多模光纤的比较如下表所示。

单模光纤与多模光纤的比较
光纤的主要传播特性
光纤的主要传播特性为损耗和色散。损耗是光信号在光纤中传输时发生的信号衰减,其单位为dB/km。色散是到达接收端的延迟误差,即脉冲宽度,其单位是μs/km。光纤的损耗会影响传输的中继距离,色散会影响数据传输速率,两者都很重要。自1976年以来,人们发现使用1.3μm和1.55μm波长的光信号通过光纤传输时的损耗幅度大约为0.5~0.2dB/km;而使用0.85μm波长的光信号通过光纤传输时的损耗幅度大约为3dB/km。使用0.85μm波长的光信号在多模光纤中传输时,色散可以降至10μs/km以下;而使用1.3μm波长的光信号在单模光纤中传输时,产生的色散近似于零。因此单模光纤在传输光信号时,产生的损耗和色散都比多模光纤要低得多,因此单模光纤支持无中继距离和数据传输速率都比多模光纤要高得多。
19. 以100Mb/s以太网连接的站点A和B相隔2000m,通过停等机制进行数据传输,传播速率为200m/us,有效的传输速率为( )Mb/s.
A. 80.8
B. 82.9
C. 90.1
D. 92.3
千兆以太网标准802.3z定义了一种帧突发方式(frame bursting),这种方式是指(61)。
下列千兆以太网标准中,传输距离最短的是( )。
双绞线电缆配置如下图所示,这种配置支持(26)之间的连接。
随着网络的发展,传统标准的以太网技术已难以满足日益增长的网络数据流量速度需求。在1993年10月以前,对于要求10Mb/s以上数据流量的LAN应用,只有光纤分布式数据接口(FDDI)可供选择,但它是一种价格非常昂贵的、基于100Mb/s光缆的LAN。1993年10月,Grand Junction公司推出了世界上第一台快速以太网集线器Fastch10/100和网络接口卡FastNIC100,快速以太网技术正式得以应用。随后Intel、SynOptics、3COM、BayNetworks等公司也相继推出自己的快速以太网装置。与此同时,IEEE 8023工作组也对100Mb/s以太网的各种标准(如100Base-TX、100Base-T4、MII、中继器、全双工等)进行了研究。1995年3月IEEE宣布了IEEE 802.3u 100Base-T快速以太网(Fast Ethernet)标准,就这样开始了快速以太网的时代。1997年,IEEE通过了IEEE 802.3x,支持在现有通道上进行全双工通信。
快速以太网与原来在100Mb/s带宽下工作的FDDI相比具有许多优点,最主要体现在快速以太网技术可以有效地保障用户在布线基础实施上的投资,它支持三、四、五类双绞线以及光纤的连接,能有效地利用现有的设施。
快速以太网的不足其实也是以太网技术的不足,那就是快速以太网仍是基于CSMA/CD技术,当网络负载较重时,会造成效率的降低,当然这可以使用交换技术来弥补。
100Mb/s快速以太网标准又分为100Base-T4、100Base-TX和10Base-FX等3个子类。
1)100Base-T4
100Base-T4是一种传输媒体可使用三、四、五类无屏蔽双绞线或屏蔽双绞线的快速以太网技术。它使用了4对双绞线,其中3对用于传送数据,1对用于检测冲突信号。在传输中使用8B/6T(8比特映射为6个三进制位)编码方式,它使用三元信号,每个周期发送4b,这样就获得了100Mb/s传输速率,还有一个33.3Mb/s的保留信道。信号频率为25MHz,符合EIA 586结构化布线标准。它使用与10Base-T相同的RJ-45连接器,最大网段长度为100m。
2)100Base-TX
100Base-TX是一种使用五类数据级无屏蔽双绞线或屏蔽双绞线的快速以太网技术。它使用了两对双绞线,其中一对用于发送,另一对用于接收数据。在传输中使用4B/5B编码方式,信号频率为125MHz。该编码方案将每4b的数据编成5b的数据,挑选时每组数据中不允许出现多于3个0,然后再将4B/5B进一步编成NRZI码进行传输,传输速率达到100Mb/s。100Base-TX符合EIA 568的五类布线标准和IBM的SPT一类布线标准,使用与10Base-T相同的RJ-45连接器,其最大网段长度为100m,支持全双工的数据传输。
3)100Base-FX
100Base-FX是一种使用光缆的快速以太网技术,可使用单模和多模光纤(62.5μm和125μm)。多模光纤连接的最大距离为550m,单模光纤连接的最大距离为3000m。在传输中使用4B/5B编码方式,信号频率为125MHz。它使用MIC/FDDI连接器、ST连接器或SC连接器。它的最大网段长度为150m、412m、2000m或更长至10km,这与所使用的光纤类型和工作模式有关,它支持全双工的数据传输。100Base-FX特别适合于有电气干扰的环境、较大距离连接或高保密环境等情况下的使用。
传输速率是指数据在信道中传输的速度。可以用码元传输速率和信息传输速率两种方式来描述。
码元是在数字通信中常常用时间间隔相同的符号来表示一位二进制数字。这样的时间间隔内的信号称为二进制码元,而这个间隔被称为码元长度。码元传输速率又称为码元速率或传码率。码元速率又称为波特率,每秒中传送的码元数。若数字传输系统所传输的数字序列恰为二进制序列,则等于每秒钟传送码元的数目,而在多电平中则不等同。单位为“波特/秒”,常用符号Baud/s表示。
信息传输速率即位率,位/秒(b/s),表示每秒中传送的信息量。
设定码元传输速率为RB,信息速率Rb,则两者的关系如下:
Rb=RB×log2M
其中,M为采用的进制。例如,对于采用十六进制进行传输信号,则其信息速率就是码元速率的4倍;如果数字信号采用四级电平即四进制,则一个四进制码元对应两个二进制码元(4=22)。
以太网是最早使用的局域网,也是目前使用最广泛的网络产品。以太网有10Mb/s、100Mb/s、1000Mb/s、10Gb/s等多种速率。
以太网传输介质
以太网比较常用的传输介质包括同轴电缆、双绞线和光纤三种,以IEEE 802.3委员会习惯用类似于10Base-T的方式进行命名。这种命名方式由三个部分组成:
(1)10:表示速率,单位是Mb/s。
(2)Base:表示传输机制,Base代表基带,Broad代表宽带。
(3)T:传输介质,T表示双绞线、F表示光纤、数字代表铜缆的最大段长。
传输介质的具体命名方案如下表所示,了解这些知识是十分必要的。
以太网传输介质表
以太网时隙
时间被分为离散的区间称为时隙(Slot Time)。帧总是在时隙开始的一瞬间开始发送。一个时隙内可能发送0,1或多个帧,分别对应空闲时隙、成功发送和发生冲突的情况。
设置时隙理由
在以太网规则中,若发生冲突,则必须让网上每个主机都检测到。信号传播整个介质需要一定的时间。考虑极限情况,主机发送的帧很小,两冲突主机相距很远。在A发送的帧传播到B的前一刻,B开始发送帧。这样,当A的帧到达B时,B检测到了冲突,于是发送阻塞信号。B的阻塞信号还没有传输到A,A的帧已发送完毕,那么A就检测不到冲突,而误认为已发送成功,不再发送。由于信号的传播时延,检测到冲突需要一定的时间,所以发送的帧必须有一定的长度。这就是时隙需要解决的问题。
在最坏情况下,检测到冲突所需的时间
若A和B是网上相距最远的两个主机,设信号在A和B之间传播时延为τ,假定A在t时刻开始发送一帧,则这个帧在t+τ时刻到达B,若B在t+τ-ε时刻开始发送一帧,则B在t+τ时就会检测到冲突,并发出阻塞信号。阻塞信号将在t+2τ时到达A。所以A必须在t+2τ时仍在发送才可以检测到冲突,所以一帧的发送时间必须大于2τ。
按照标准,10Mb/s以太网采用中继器时,连接最大长度为2500m,最多经过4个中继器,因此规定对于10Mb/s以太网规定一帧的最小发送时间必须为51.2μs。51.2μs也就是512位数据在10Mb/s以太网速率下的传播时间,常称为512位时。这个时间定义为以太网时隙。512位=64字节,因此以太网帧的最小长度为64字节。
冲突发生的时段
(1)冲突只能发生在主机发送帧的最初一段时间,即512位时的时段。
(2)当网上所有主机都检测到冲突后,就会停发帧。
(3)512位时是主机捕获信道的时间,如果某主机发送一个帧的512位时,而没有发生冲突,以后也就不会再发生冲突了。
提高传统以太网带宽的途径
以往被淘汰、传统的以太网是以10Mb/s速率半双工方式进行数据传输的。随着网络应用的迅速发展,网络的带宽限制已成为进一步提高网络性能的瓶颈。提高传统以太网带宽的方法主要有以下3种。
交换以太网
以太网使用的CSMA/CD是一种竞争式的介质访问控制协议,因此从本质上说它在网络负载较低时性能不错,但如果网络负载很大时,冲突会很常见,因此导致网络性能的大幅下降。为了解决这一瓶颈问题,“交换式以太网”应运而生,这种系统的核心是使用交换机代替集线器。交换机的特点是,其每个端口都分配到全部10Mb/s的以太网带宽。若交换机有8个端口或16个端口,那么它的带宽至少是共享型的8倍或16倍(这里不包括由于减少碰撞而获得的带宽)。
交换以太网能够大幅度的提高网络性能的主要原因是:
.减少了每个网段中的站点的数量;
.同时支持多个并发的通信连接。
网络交换机有三种交换机制:直通(Cut through)、存储转发(Store and forward)和碎片直通(Fragment free Cut through)。
交换式以太网具有几个优点:第一,它保留现有以太网的基础设施,保护了用户的投资;第二,提高了每个站点的平均拥有带宽和网络的整体带宽;第三,减少了冲突,提高了网络传输效率。
全双工以太网
全双工技术可以提供双倍于半双工操作的带宽,即每个方向都支持10Mb/s,这样就可以得到20Mb/s的以太网带宽。当然这还与网络流量的对称度有关。
全双工操作吸引人的另一个特点是它不需要改变原来10Base-T网络中的电缆布线,可以使用和10Base-T相同的双绞线布线系统,不同的是它使用一对双绞线进行发送,而使用另一对进行接收。这个方法是可行的,因为一般10Base-T布线是有冗余的(共4对双绞线)。
高速服务器连接
众多的工作站在访问服务器时可能会在服务器的连接处出现瓶颈,通过高速服务器连接可以解决这个问题。使用带有高速端口的交换机(如24个10Mb/s端口,1个100Mb/s或1000Mb/s高速端口),然后再把服务器接在高速端口上并使用全双工操作。这样服务器就可以实现与网络200Mb/s或2000Mb/s的连接。
以太网的帧格式
以太网帧的格式如下图所示,包含的字段有前导码、目的地址、源地址、数据类型、发送的数据,以及帧校验序列等。这些字段中除了数据字段是变长以外,其余字段的长度都是固定的。
以太网的帧结构
注:字段的长度以字节为单位
前导码(P)字段占用8字节。
目的地址(DA)字段和源地址(SA)字段都是占用6字节的长度。目的地址用于标识接收站点的地址,它可以是单个的地址,也可以是组地址或广播地址,当地址中最高字节的最低位设置为1时表示该地址是一个多播地址,用十六进制数可表示为01:00:00:00:00:00,假如全部48位(每字节8位,6字节即48位)都是1时,该地址表示是一个广播地址。源地址用于标识发送站点的地址。
类型(Type)字段占用两字节,表示数据的类型,如0x0800表示其后的数据字段中的数据包是一个IP包,而0x0806表示ARP数据包,0x8035表示RARP数据包。
数据(Data)字段占用46~1500个不等长的字节数。以太网要求最少要有46字节的数据,如果数据不够长度,必须在不足的空间插入填充字节来补充。
帧校验序列(FCS)字段是32位(即4字节)的循环冗余码。
20. 采用ADSL接入互联网,计算机需要通过(20)和分离器连接到电话入户接线盒。在HFC网络中,用户通过(21)接入CATV网络。
A. ADSL交换机
B. Cable Modem
C. ADSL Modem
D. 无线路由器
下面关于RS-232-C标准的描述中,正确的是(14)。
电话线路使用的带通虑波器的宽带为3KHz (300~3300Hz),根据奈奎斯特采样定理,最小采样频率应为(16)。
利用SDH实现广域网互联,如果用户需要的数据传输速率较小,可以用准同步数 字系列(PDH)兼容的传输方式在每个STM-1帧中封装(70)..
ADSL是一种非对称的宽带接入方式,即用户线的上行速率和下行速率不同。它采用FDM技术和DMT调制技术,在保证不影响正常电话使用的前提下,利用原有的电话双绞线进行高速数据传输。ADSL的优点是可在现有的任意双绞线上传输,误码率低,系投资少。缺点是有选线率问题,带宽速率低。
ADSL不仅继承了HDSL技术成果,而且在信号调制与编码、相位均衡及回波抵消等方面采用了更加先进的技术,性能更佳。由于ADSL的特点,ADSL主要用于Internet接入、居家购物、远程医疗等。
从实际的数据组网形式上看,ADSL所起的作用类似于窄带的拨号Modem,担负着数据的传送功能。按照OSI/RM的划分标准,ADSL的功能从理论上应该属于物理层。它主要实现信号的调制及提供接口类型等一系列底层的电气特性。同样,ADSL的宽带接入仍然遵循数据通信的对等通信原则,在用户侧对上层数据进行封装后,在网络侧的同一层上进行开封。因此,要实现ADSL的各种宽带接入,在网络侧也必须有相应的网络设备相结合。
ADSL的接入模型主要由中央交换局端模块(ATU-C)和远端用户模块(ATU-R)组成。中央交换局端模块包括中心ADSL Modem和接入多路复用系统DSLAM,远端模块由用户ADSL Modem和滤波器组成。
ADSL能够向终端用户提供1~8Mb/s的下行传输速率和512kb/s~1Mb/s的上行速率,有效传输距离在3~5km左右。
比较成熟的ADSL标准主要有两种,分别是G.DMT和G. Lite。G. DMT是全速率的ADSL标准,提供支持8Mb/s的下行速率,及1.5Mb/s的上行速率,但G.DMT要求用户端安装POTS(Plain Old Telephone Service,普通老式电话服务)分离器,比较复杂且价格昂贵。GLite是一种速度较慢的ADSL,它不需要在用户端进行线路的分离,而是电话公司的远程用户分离线路。正式称呼为ITU-T标准G-992.2的G. Lite,提供了1.5 Mb/s的下行速率和512 kb/s的上行速率。
目前,众多ADSL厂商在技术实现上,普遍将先进的ATM服务质量保证技术融入到ADSL设备中,DSLAM(ADSL的用户集中器)的ATM功能的引入,不仅提高了整个ADSL接入的总体性能,为每一用户提供了可靠的接入带宽,为ADSL星形组网方式提供了强有力的支撑,而且完成了与ATM接口的无缝互联,实现了与ATM骨干网的完美结合。
21. 采用ADSL接入互联网,计算机需要通过(20)和分离器连接到电话入户接线盒。在HFC网络中,用户通过(21)接入CATV网络。
A. ADSL交换机
B. Cable Modem
C. ADSL Moton
D. 无线路由器
数字用户线(DSL)是基于普通电话线的宽带接入技术,可以在铜质双绞线上同时传送数据和话音信号。下列选项中,数据速率最高的DSL标..
电话线路使用的带通虑波器的宽带为3KHz (300~3300Hz),根据奈奎斯特采样定理,最小采样频率应为(16)。
RS-232-C的电气特性采用V.28标准电路,允许的数据速率是(13),传输距离不大于(14)。
22. 某IP网络连接如下图所示,下列说法中正确的是( )。

A. 共有2个冲突域
B. 共有2个广播域
C. 计算机S和计算机T构成冲突域
D. 计算机Q查找计算机R的MAC地址时,ARP报文会传播到计算机S
生成树协议STP使用了哪两个参数来选举根网桥?(61)。
某STP网络从链路故障中恢复时,端口收敛时间超过30秒,处理该故障的思路不包括:( )。
在下面的标准中,定义快速生成树协议的是(26),支持端口认证的协议是(27)。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
23. 采电HDLC协议进行数据传输时,RNR 5表明( )。
A. 拒绝编号为5的帧
B. 下一个接收的帧编号应为5,但接收器末准备好,暂停接收
C. 后退N帧重传编号为5的帧
D. 选择性拒绝编号为5的帧
数据链路协议HDLC是一种(15) .
HDLC协议是一种(17),采用(18)标志作为帧定界符。
OSPF将路由器连接的物理网络划分为以下4种类型,以太网属于(25),X.25分组交换网属于(26)。
HDLC(High Level Data Link Control,高级数据链路控制)协议是国际标准化组织根据IBM公司的SDLC协议扩充开发而成的。它是一种面向位的数据链路控制协议。
HDLC帧由6个字段组成,如下图所示。
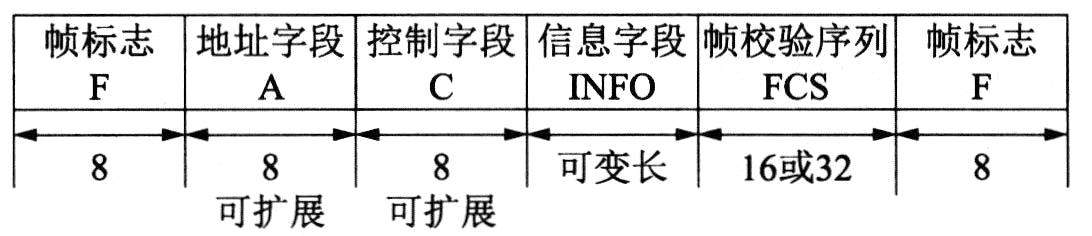
HDLC帧结构
(1)HDLC用一种特殊的位模式0111110作为帧的边界标志。
(2)地址字段用于标识从站的地址,用在点对多点链路中。
(3)HDLC定义了3种帧:信息帧(I帧)、管理帧(S帧)和无编号帧(U帧),如下图所示。控制字段第一位或前两位用于区别3种不同格式的帧。基本的控制字段是8位长。扩展的控制字段为16位长。
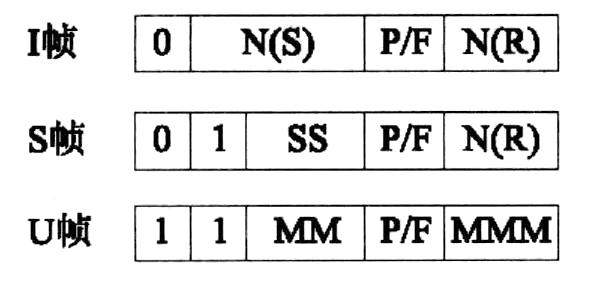
HDLC 3种帧的基本控制信息
(4)信息字段只有I帧和某些无编号帧含有的信息字段。
(5)帧校验序列通常使用CRC-CCITT标准产生的16位校验序列,有时也使用CRC-32产生的32位校验序列。
24. 若主机采用以太网接入Internet,TCP段格式中,数据字段最大长度为( )字节。
A. 20
B. 1460
C. 1500
D. 65535
当客户端收到多个DHCP服务器的响应时,客户端会选择(38)地址作为自己的IP地址。
以下给出的地址中,属于子网172.112.15.19/28的主机地址是(58)。
下面4个主机地址中属于网络110.17.200.0/21的地址是(53)。
在网络管理中,最为常用的就是net命令家族。常用的net命令有以下几个。
.net view命令:显示由指定的计算机共享的域、计算机或资源的列表。
.net share:用于管理共享资源,使网络用户可以使用某一服务器上的资源。
.net use命令:用于将计算机与共享的资源相连接或断开,或者显示关于计算机连接的信息。
.net start命令:用于启动服务,或显示已启动服务的列表。
.net stop命令:用于停止正在运行的服务。
.net user命令:可用来添加或修改计算机上的用户账户,或者显示用户账户的信息。
.net config命令:显示正在运行的可配置服务,或显示和更改服务器服务或工作站服务的设置。
.net send命令:用于将消息(可以是中文)发送到网络上的其他用户、计算机或者消息名称上。
.net localgroup命令:用于添加、显示或修改本地组。
.net accounts命令:可用来更新用户账户数据库、更改密码及所有账户的登录要求。
TCP是面向连接的通信协议,通过三次握手建立连接,通信完成时要拆除连接,由于TCP是面向连接的,所以只能用于端到端的通信。
TCP提供的是一种可靠的数据流服务,采用“带重传的肯定确认”技术实现传输的可靠性。TCP还采用一种称为“滑动窗口”的方式进行流量控制,所谓窗口,实际表示接收能力,用以限制发送方的发送速度。
如果IP数据包中有已经封装好的TCP数据包,那么IP将把它们向“上”传送到TCP层。TCP将包排序并进行错误检查,同时实现虚电路之间的连接。TCP数据包中包括序号和确认,所以未按照顺序收到的包可以被排序,而损坏的包则可以被重传。
TCP将它的信息发送到更高层的应用程序,例如Telnet的服务程序和客户程序。应用程序轮流将信息送回TCP层,TCP层便将它们向下传送到IP层、设备驱动程序和物理介质,最后传送到接收方。
面向连接的服务(例如Telnet、FTP、rlogin、X Windows和SMTP)需要高度的可靠性,所以它们使用了TCP。DNS在某些情况下使用TCP(发送和接收域名数据库),但使用UDP传送有关单个主机的信息。
以太网是最早使用的局域网,也是目前使用最广泛的网络产品。以太网有10Mb/s、100Mb/s、1000Mb/s、10Gb/s等多种速率。
以太网传输介质
以太网比较常用的传输介质包括同轴电缆、双绞线和光纤三种,以IEEE 802.3委员会习惯用类似于10Base-T的方式进行命名。这种命名方式由三个部分组成:
(1)10:表示速率,单位是Mb/s。
(2)Base:表示传输机制,Base代表基带,Broad代表宽带。
(3)T:传输介质,T表示双绞线、F表示光纤、数字代表铜缆的最大段长。
传输介质的具体命名方案如下表所示,了解这些知识是十分必要的。
以太网传输介质表
以太网时隙
时间被分为离散的区间称为时隙(Slot Time)。帧总是在时隙开始的一瞬间开始发送。一个时隙内可能发送0,1或多个帧,分别对应空闲时隙、成功发送和发生冲突的情况。
设置时隙理由
在以太网规则中,若发生冲突,则必须让网上每个主机都检测到。信号传播整个介质需要一定的时间。考虑极限情况,主机发送的帧很小,两冲突主机相距很远。在A发送的帧传播到B的前一刻,B开始发送帧。这样,当A的帧到达B时,B检测到了冲突,于是发送阻塞信号。B的阻塞信号还没有传输到A,A的帧已发送完毕,那么A就检测不到冲突,而误认为已发送成功,不再发送。由于信号的传播时延,检测到冲突需要一定的时间,所以发送的帧必须有一定的长度。这就是时隙需要解决的问题。
在最坏情况下,检测到冲突所需的时间
若A和B是网上相距最远的两个主机,设信号在A和B之间传播时延为τ,假定A在t时刻开始发送一帧,则这个帧在t+τ时刻到达B,若B在t+τ-ε时刻开始发送一帧,则B在t+τ时就会检测到冲突,并发出阻塞信号。阻塞信号将在t+2τ时到达A。所以A必须在t+2τ时仍在发送才可以检测到冲突,所以一帧的发送时间必须大于2τ。
按照标准,10Mb/s以太网采用中继器时,连接最大长度为2500m,最多经过4个中继器,因此规定对于10Mb/s以太网规定一帧的最小发送时间必须为51.2μs。51.2μs也就是512位数据在10Mb/s以太网速率下的传播时间,常称为512位时。这个时间定义为以太网时隙。512位=64字节,因此以太网帧的最小长度为64字节。
冲突发生的时段
(1)冲突只能发生在主机发送帧的最初一段时间,即512位时的时段。
(2)当网上所有主机都检测到冲突后,就会停发帧。
(3)512位时是主机捕获信道的时间,如果某主机发送一个帧的512位时,而没有发生冲突,以后也就不会再发生冲突了。
提高传统以太网带宽的途径
以往被淘汰、传统的以太网是以10Mb/s速率半双工方式进行数据传输的。随着网络应用的迅速发展,网络的带宽限制已成为进一步提高网络性能的瓶颈。提高传统以太网带宽的方法主要有以下3种。
交换以太网
以太网使用的CSMA/CD是一种竞争式的介质访问控制协议,因此从本质上说它在网络负载较低时性能不错,但如果网络负载很大时,冲突会很常见,因此导致网络性能的大幅下降。为了解决这一瓶颈问题,“交换式以太网”应运而生,这种系统的核心是使用交换机代替集线器。交换机的特点是,其每个端口都分配到全部10Mb/s的以太网带宽。若交换机有8个端口或16个端口,那么它的带宽至少是共享型的8倍或16倍(这里不包括由于减少碰撞而获得的带宽)。
交换以太网能够大幅度的提高网络性能的主要原因是:
.减少了每个网段中的站点的数量;
.同时支持多个并发的通信连接。
网络交换机有三种交换机制:直通(Cut through)、存储转发(Store and forward)和碎片直通(Fragment free Cut through)。
交换式以太网具有几个优点:第一,它保留现有以太网的基础设施,保护了用户的投资;第二,提高了每个站点的平均拥有带宽和网络的整体带宽;第三,减少了冲突,提高了网络传输效率。
全双工以太网
全双工技术可以提供双倍于半双工操作的带宽,即每个方向都支持10Mb/s,这样就可以得到20Mb/s的以太网带宽。当然这还与网络流量的对称度有关。
全双工操作吸引人的另一个特点是它不需要改变原来10Base-T网络中的电缆布线,可以使用和10Base-T相同的双绞线布线系统,不同的是它使用一对双绞线进行发送,而使用另一对进行接收。这个方法是可行的,因为一般10Base-T布线是有冗余的(共4对双绞线)。
高速服务器连接
众多的工作站在访问服务器时可能会在服务器的连接处出现瓶颈,通过高速服务器连接可以解决这个问题。使用带有高速端口的交换机(如24个10Mb/s端口,1个100Mb/s或1000Mb/s高速端口),然后再把服务器接在高速端口上并使用全双工操作。这样服务器就可以实现与网络200Mb/s或2000Mb/s的连接。
以太网的帧格式
以太网帧的格式如下图所示,包含的字段有前导码、目的地址、源地址、数据类型、发送的数据,以及帧校验序列等。这些字段中除了数据字段是变长以外,其余字段的长度都是固定的。
以太网的帧结构
注:字段的长度以字节为单位
前导码(P)字段占用8字节。
目的地址(DA)字段和源地址(SA)字段都是占用6字节的长度。目的地址用于标识接收站点的地址,它可以是单个的地址,也可以是组地址或广播地址,当地址中最高字节的最低位设置为1时表示该地址是一个多播地址,用十六进制数可表示为01:00:00:00:00:00,假如全部48位(每字节8位,6字节即48位)都是1时,该地址表示是一个广播地址。源地址用于标识发送站点的地址。
类型(Type)字段占用两字节,表示数据的类型,如0x0800表示其后的数据字段中的数据包是一个IP包,而0x0806表示ARP数据包,0x8035表示RARP数据包。
数据(Data)字段占用46~1500个不等长的字节数。以太网要求最少要有46字节的数据,如果数据不够长度,必须在不足的空间插入填充字节来补充。
帧校验序列(FCS)字段是32位(即4字节)的循环冗余码。
25. TCP采用拥塞窗口(cwnd)进行拥塞控制。以下关于cwnd的说法中正确的是( )。
A. 首部中的窗口段存放cwnd的值
B. 每个段包含的数据只要不超过cwnd值就可以发送了
C. cwnd值由对方指定
D. cwnd值存放在本地
POP3服务器默认使用(36)协议的(37)的端口。
建立TCP连接时,一端主动打开后所处的状态为(21)。
下图中主机A和主机B通过三次握手建立TCP连接,图中(1)处的状态是(20),图(2)处的数字是(21)。
TCP是面向连接的通信协议,通过三次握手建立连接,通信完成时要拆除连接,由于TCP是面向连接的,所以只能用于端到端的通信。
TCP提供的是一种可靠的数据流服务,采用“带重传的肯定确认”技术实现传输的可靠性。TCP还采用一种称为“滑动窗口”的方式进行流量控制,所谓窗口,实际表示接收能力,用以限制发送方的发送速度。
如果IP数据包中有已经封装好的TCP数据包,那么IP将把它们向“上”传送到TCP层。TCP将包排序并进行错误检查,同时实现虚电路之间的连接。TCP数据包中包括序号和确认,所以未按照顺序收到的包可以被排序,而损坏的包则可以被重传。
TCP将它的信息发送到更高层的应用程序,例如Telnet的服务程序和客户程序。应用程序轮流将信息送回TCP层,TCP层便将它们向下传送到IP层、设备驱动程序和物理介质,最后传送到接收方。
面向连接的服务(例如Telnet、FTP、rlogin、X Windows和SMTP)需要高度的可靠性,所以它们使用了TCP。DNS在某些情况下使用TCP(发送和接收域名数据库),但使用UDP传送有关单个主机的信息。
26. UDP头部的大小为( )字节。
A. 8
B. 16
C. 20
D. 32
主机甲向主机乙发送一个TCP报文段,SYN字段为“1”,序列号字段的值为2000,若主机乙同意建立连接,则发送给主机甲的报..
IP头和TCP头的最小开销合计为(21)字节,以太网最大帧长为1518字节,则可以传送的TCP数据最大为(22)字节。
下图中主机A和主机B通过三次握手建立TCP连接,图中(1)处的状态是(20),图(2)处的数字是(21)。
UDP是TCP/IP协议簇中等同于TCP的通信协议,其差异在于:UDP直接利用IP进行UDP数据报的传输,因此UDP提供的是无连接、不可靠的数据报投递服务。
UDP常用于数据量较少的数据传输。例如,域名系统中域名地址/IP地址的映射请求和应答采用UDP进行传输,以减少TCP连接的过程,提高工作效率。
当使用UDP传输信息流时,用户负责解决排序、差错确认等问题。
27. 为了控制P数据报在网络中无限转发,在IPv4数据报首部中设置了( )字段。
A. 标识符
B. 首部长度
C. 生存期
D. 总长度
IP 地址202.117.17.255/22 是什么地址? (55)。
假设用户Q1有2000台主机,则必须给他分配(53)个C类网络,如果分配给用户Q1的超网号为200.9.64.0,则指定给Q1的地址掩码为(54):假..
由DHCP服务器分配的默认网关地址是192.168.5.33/28,(53)是本地主机的有效地址。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
对于短报文来说,一个报文分组就足够容纳所传送的数据信息。一般单个报文分组称数据报(Datagram)。数据报的服务以传送单个报文分组为主要目标。原CCITT研究组把数据报定义为,能包含在单个报文分组数据域中的报文,且传送它到目标地址与其他已发送或将要发送的报文分组无关,这样报文分组号可以省略。也就是说,每个分组的传送是被单独处理的,它本身携带有足够的信息。
数据报的一般格式如下表所示:

数据报格式
发送数据报与发送信件和邮包一样。在数据报服务控制下,网络接受来自源的单一报文分组,并独立地传到目的点。数据报服务是无连接的服务。
28. Telnet是用于远程访问服务器的常用协议。下列关于Telnet的描述中,不正确的是( )。
A. 可传输数据和口令
B. 默认端口号是23
C. 一种安全的通信协议
D. 用TCP作为传输层协议
配置POP3服务器时,邮件服务器的属性对话框如下图所示,其中默认情况下“服务器端口”文本框应填入(37)。
当接收邮件时,客户端与POP3服务器之间通过(39)建立连接,所使用的端口是(40)。
与HTTP1.0相比,HTTP1.1的优点不包括(30)。
在网络管理中,最为常用的就是net命令家族。常用的net命令有以下几个。
.net view命令:显示由指定的计算机共享的域、计算机或资源的列表。
.net share:用于管理共享资源,使网络用户可以使用某一服务器上的资源。
.net use命令:用于将计算机与共享的资源相连接或断开,或者显示关于计算机连接的信息。
.net start命令:用于启动服务,或显示已启动服务的列表。
.net stop命令:用于停止正在运行的服务。
.net user命令:可用来添加或修改计算机上的用户账户,或者显示用户账户的信息。
.net config命令:显示正在运行的可配置服务,或显示和更改服务器服务或工作站服务的设置。
.net send命令:用于将消息(可以是中文)发送到网络上的其他用户、计算机或者消息名称上。
.net localgroup命令:用于添加、显示或修改本地组。
.net accounts命令:可用来更新用户账户数据库、更改密码及所有账户的登录要求。
29. Cookie为客户端持久保持数据提供了方便,但也存在一定的弊端。下列选项中,不属于Cookie弊端的是( )。
A. 增加流量消耗
B. 明文传物,存在安全性隐患
C. 存在敏感信息泄露风险
D. 保存访问站点的缓存数据
FTP协议默认使用的数据端口是( )。
SHA-256是( )算法。
POP3服务器默认使用(36)协议的(37)的端口。
30. 使用电子邮件客户端从服务器下载邮件,能实现邮件的移动、删除等操作在客户端和邮箱上更新同步,所使用的电子邮件接收协议是( )。
A. SMTP
B. POP3
C. IMAP4
D. MIME
若FTP服务器开启了匿名访问功能,匿名登录时需要输入的用户名是(40)。
安全电子邮件使用(68)协议。
POP3协议采用(26)模式,当客户机需要服务时,客户端软件(OutlookExpress 或FoxMail)与POP3服务器建立(27)连接。
语句格式:

电子邮件(E-mail)是现在数据量、使用量最大的一个Internet应用,它用来完成人际之间的消息通信。与它相关的有以下三个协议。
(1)SMTP:简单邮件传送协议,用于邮件的发送,工作在25号端口上。
(2)POP3(Post Office Protocol 3,邮局协议的第3个版本):用于接收邮件,工作在110号端口上。
(3)IMAP(Interactive Mail Access Protocol,交互式邮件存取协议):邮件访问协议,是用于替代POP3协议的新协议,工作在143号端口上。
31. 在Linux系统中,DNS配置文件的( )参数,用于确定DNS服务器地址。
A. nameserver
B. domain
C. search
D. sortlist
在Linux系统中,使用Apache服务器时默认的Web根目录是(35)。
在Linux操作系统中,存放用户账号加密口令的文件是(34)。
下面关于Linux系统文件挂载的叙述中,正确的是(36)。
DNS服务器进行域名解析时,若采用递归方法,发送的域名请求为(30)。
DNS服务器中提供了多种资源记录,其中(37)定义了区域的邮件服务器及其优先级。
在Windows中,可以使用(38)命令测试DNS正向解析功能,要查看域名www.aaa.com所对应的主机IP地址,须将type值设置为(39)。
网络用户希望用有意义的名字来标识主机,而不是IP地址。为了解决这个需求,应运而生的是域名服务系统(DNS)。它运行在TCP协议之上,负责将域名转换成实际相对应的IP地址,从而在不改变底层协议的寻址方法的基础上,为使用者提供一个直接使用符号名来确定主机的平台。
DNS是一个分层命名系统,名字由若干个标号组成,标号之间用圆点分隔。最右边的是主域名,最左边的是主机名,中间的是子域名。
通常写域名时,最后是不加“.”的,其实这只是一个缩写,最后一个“.”代表的是“根”。如果采用全域名写法,还需要加上这个小点。这在配置DNS时就会见到。
除了以上讲述的名字语法规则和管理机构的设立,域名系统中还包括一个高效、可靠、通用的分布式系统用于名字到地址的映射。将域名映射到IP地址的机制由若干个称为名字服务器(name server)的独立、协作的系统组成。
DNS实际上是一个服务器软件,运行在指定的计算机上,完成域名到IP地址的转换。它把网络中的主机按树形结构分成域和子域,子域名或主机名在上级域名结构中必须是唯一的。每一个子域都有域名服务器,它管理着本域的域名转换,各级服务器构成一棵树。这样,当用户使用域名时,应用程序先向本地域名服务器请求,本地服务器先查找自己的域名库,如果找到该域名,则返回IP地址;如果未找到,则分析域名,然后向相关的上级域名服务器发出申请。这样传递下去,直至有一个域名服务器找到该域名,并返回IP地址。如果没有域名服务器能识别该域名,则认为该域名不可知。
充分利用机器的高速缓存,暂存解析后的IP地址,可以提高DNS的查询效率。用户有时会连续访问相同的因特网地址,DNS在第一次解析该地址后,将其存放在高速缓存中,当用户再次请求时,DNS可直接从缓存中获得IP地址。
Linux是一个类似于UNIX的操作系统,Linux系统不仅能够运行于PC平台,还在嵌入式系统方面大放光芒,在各种嵌入式Linux迅速发展的状况下,Linux逐渐形成了可与Windows CE等嵌入式操作系统进行抗衡的局面。嵌入式Linux的特点如下:
(1)精简的内核,性能高,稳定,多任务。
(2)适用于不同的CPU,支持多种架构,如x86、ARM、ALPHA、SPARC等。
(3)能够提供完善的嵌入式图形用户界面以及嵌入式X-Windows。
(4)提供嵌入式浏览器、邮件程序、音频和视频播放器、记事本等应用程序。
(5)提供完整的开发工具和软件开发包,同时提供PC上的开发版本。
(6)用户可定制,可提供图形化的定制和配置工具。
(7)常用嵌入式芯片的驱动集,支持大量的周边硬件设备,驱动丰富。
(8)针对嵌入式的存储方案,提供实时版本和完善的嵌入式解决方案。
(9)完善的中文支持,强大的技术支持,完整的文档。
(10)开放源码,丰富的软件资源,广泛的软件开发者的支持,价格低廉,结构灵活,适用面广。
32. 在Linux系统中,要将文件复制到另一个目录中,为防止意外覆盖相同文件名的文件,可使用( )命令实现。
A. cp-a
B. cp-i
C. cp-R
D. cp-f
Linux系统中,DHCP服务的主配置文件是(34),保存客户端租约信息的文件是(35)。
在Linux中,要复制整个目录,应使用( )命令。
在Linux操作系统中,存放用户账号加密口令的文件是(34)。
Linux是一个类似于UNIX的操作系统,Linux系统不仅能够运行于PC平台,还在嵌入式系统方面大放光芒,在各种嵌入式Linux迅速发展的状况下,Linux逐渐形成了可与Windows CE等嵌入式操作系统进行抗衡的局面。嵌入式Linux的特点如下:
(1)精简的内核,性能高,稳定,多任务。
(2)适用于不同的CPU,支持多种架构,如x86、ARM、ALPHA、SPARC等。
(3)能够提供完善的嵌入式图形用户界面以及嵌入式X-Windows。
(4)提供嵌入式浏览器、邮件程序、音频和视频播放器、记事本等应用程序。
(5)提供完整的开发工具和软件开发包,同时提供PC上的开发版本。
(6)用户可定制,可提供图形化的定制和配置工具。
(7)常用嵌入式芯片的驱动集,支持大量的周边硬件设备,驱动丰富。
(8)针对嵌入式的存储方案,提供实时版本和完善的嵌入式解决方案。
(9)完善的中文支持,强大的技术支持,完整的文档。
(10)开放源码,丰富的软件资源,广泛的软件开发者的支持,价格低廉,结构灵活,适用面广。
33. 在Linux系统中,可在( )文件中修改系统主机名。
A. /ctc/hostname
B. /ctc/sysconfig
C. /dev/hostname
D. /dev/sysconfig
在Linux系统中可用ls -al命令列出文件列表, (31) 列出的是一个符号连接文件。
在Linux 中,( )是默认安装DHCP服务器的配置文件。
在Linux中,通常使用( )命令删除一个文件或目录。
Linux是一个类似于UNIX的操作系统,Linux系统不仅能够运行于PC平台,还在嵌入式系统方面大放光芒,在各种嵌入式Linux迅速发展的状况下,Linux逐渐形成了可与Windows CE等嵌入式操作系统进行抗衡的局面。嵌入式Linux的特点如下:
(1)精简的内核,性能高,稳定,多任务。
(2)适用于不同的CPU,支持多种架构,如x86、ARM、ALPHA、SPARC等。
(3)能够提供完善的嵌入式图形用户界面以及嵌入式X-Windows。
(4)提供嵌入式浏览器、邮件程序、音频和视频播放器、记事本等应用程序。
(5)提供完整的开发工具和软件开发包,同时提供PC上的开发版本。
(6)用户可定制,可提供图形化的定制和配置工具。
(7)常用嵌入式芯片的驱动集,支持大量的周边硬件设备,驱动丰富。
(8)针对嵌入式的存储方案,提供实时版本和完善的嵌入式解决方案。
(9)完善的中文支持,强大的技术支持,完整的文档。
(10)开放源码,丰富的软件资源,广泛的软件开发者的支持,价格低廉,结构灵活,适用面广。
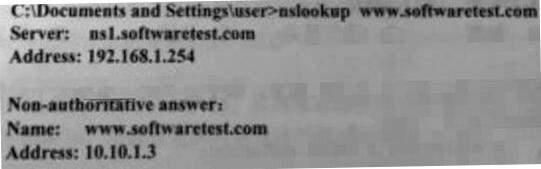
34. 在Windows命令提示符运行nslookup命令,结果如下所示。为www.softwaretest.com提供解析的DNS服务器IP地址是( )。
A. 192.168.1.254
B. 10.10.1.3
C. 192.168.1.1
D. 10.10.1.1
在Windows系统中,默认权限最低的用户组是(40)。
在Windows Server 2003中,(46)组成员用户具有完全控制权限。
Windows Server 2003操作系统中,(37)提供了远程桌面访问。
在DNS的资源记录中,A记录( )。
查看DNS缓存记录的命令是(36)。
下图是DNS转发器工作的过程。采用迭代查询算法的是(35)。
一个IP地址由网络号和主机号两部分组成,由4字节共32位的数字串组成,这4字节通常用小数点分隔。每字节可用十进制表示,如192.46.8.22。IP地址也可以用二进制和十六进制表示。
IP地址分类
IP地址分为5类,如下表所示,其中A、B、C类是常用地址。

Internet的IP地址空间容量

IP地址除了标识一台主机外,还有几种具有特殊意义的形式。
(1)本网络的本台主机。若一个IP地址由全0组成,即0.0.0.0,表示在本网络上本台主机,当一台主机在运行引导程序但又不知道其IP地址时使用该地址。
(2)本网络的某台主机。网络号各位全为"0"的IP地址,表示在这个网络中的特定主机。它用于一个主机向同网络中其他主机发送报文。
(3)网络地址。主机号各位全为"0"的IP地址标识本网络的网络地址,不分配给任何主机。
(4)直接广播地址(有时就简称为广播地址)。主机号各位全为"1"的IP地址,不分配给任何主机,它用于将一个分组发送给特定网络上的所有主机,即对全网广播。
(5)受限(本地)广播地址。受限广播地址是32位全1的IP地址(255.255.255.255)。该地址用于主机配置过程中IP数据报的目的地址,此时,主机可能还不知道它所在网络的网络掩码,甚至连它的IP地址也不知道。在任何情况下,路由器都不转发目的地址为受限的广播地址的数据报,这样的数据报仅出现在本地网络中。
(6)回送地址(Loopback Address)。A类网络地址127.X.X.X是一个保留地址,用于网络软件测试以及本地进程间的通信。
如果一个组织不需要接入到因特网上,但需要在其网络上运行TCP/IP协议,最佳选择是使用私网地址,但Internet中路由器一般不转发目标地址为私网地址的数据包。私网地址如下表所示。

私网IP地址空间
子网划分和子网掩码
由于IP地址的分配是以"网络"为单位进行的,如果一个部门拥有256个用户接入Internet,至少应该为该部门分配两个连续的C类网地址。很显然,这种分配制度导致了大量的IP地址资源的浪费。为了提高IP地址的使用效率,可采用借位的方式将一个网络划分为子网:从主机号最高位开始借位变为新的子网号,所剩余的部分仍为主机号。这使得IP地址的结构分为3部分:网络号、子网号和主机号。
引入子网划分技术后带来了一个重要问题,即主机路由和路由设备如何判断一个给定的IP地址是否已经进行了子网划分,从而能正确地从IP地址中分离出有效的网络标识。通常,将引入子网划分技术前的A、B、C类地址称为有类别(Classful)的IP地址;将引入子网划分技术后的IP地址称为无类别(Classless)的IP地址,并因此引入子网掩码来描述IP地址中关于网络标识和主机号位数的组成情况。
子网掩码(Subnetmask)通常与IP地址配对出现,其功能是告知主机或路由设备,IP地址的哪一部分代表网络号部分,哪一部分代表主机号部分。子网掩码使用与IP地址相同的编码格式,长32位,由一串1和跟随的一串0组成。子网掩码中的1对应于IP地址中的网络号(net-id)和子网号(subnet-id),而子网掩码中的0对应于IP地址中的主机号(host-id)。要得到网络或子网地址,只需将IP地址和子网掩码按位进行"与"运算即可。
子网掩码有两种表示方法。
(1)用点分十进制表示法表示,如256.256.256.0、256.256.256.240等。
(2)在IP地址后加一个"/网络号和子网号的位数"。例如,210.46.12.58/28就表示该IP地址的网络号(net-id)和子网号(subnet-id)共占用28位,主机号占用32-28=4位,如果用点分十进制表示法表示,则子网掩码为256.256.256.240,其二进制表示为
11111111 11111111 11111111 11110000
采用子网掩码是对网络编址的有益补充,但是还存在着一些缺陷,如划分的子网中较小的会浪费许多地址。为了解决这个问题,避免任何可能的地址浪费,就出现了可变长子网掩码(Variable Length Subnetwork Mask, VLSM)的编址方案。VLSM允许一个网络使用不同的网络掩码以适应不同规模的子网要求。
nslookup是一个监测网络中DNS服务器是否能正确实现域名解析的命令工具。它通常需要一台域名服务器来提供域名服务。如果用户已经设置好域名服务器,就可以用这个命令查看不同主机的IP地址对应的域名。
1)语法格式
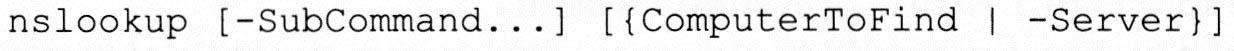
2)参数说明
.-SubCommand…:将一个或多个nslookup子命令指定为命令行选项。
.ComputerToFind:如果未指定其他服务器,就使用当前默认DNS名称服务器查阅ComputerToFind的信息。要查找不在当前DNS域的计算机,请在名称上附加句点。
.-Server:指定将该服务器作为DNS名称服务器使用。如果省略了-Server,将使用默认的DNS名称服务器。
3)nslookup的两种模式
nslookup有两种模式,即交互式和非交互式。
如果仅需要查找一块数据,请使用非交互式模式。对于第一个参数,输入要查找的计算机的名称或IP地址。对于第二个参数,输入DNS名称服务器的名称或IP地址。如果省略第二个参数,nslookup使用默认DNS名称服务器。
如果需要查找多块数据,可以使用交互模式。第一个参数输入连字符(-),第二个参数输入DNS名称服务器的名称或IP地址。或者,省略两个参数,则nslookup使用默认DNS名称服务器。在交互方式下,可以用set命令设置选项,以满足指定的查询需要。
.>set all:列出当前设置的默认选项。
.set type=mx:查询本地域的邮件交换器信息。
.server NAME:由当前默认服务器切换到指定的名字服务器NAME。
.Is:用于区域传输,罗列出本地区域中的所有主机信息。
.set type:设置查询的资源记录类型。DNS服务器主要的资源记录有A(域名到IP地址的映射)、PTR(IP地址到域名的映射)、MX(邮件服务器及其优先级)、CNAM(别名)和NS(区域的授权服务器)等类型。
.set type=any:对查询的域名显示各种可用的信息资源记录(A、CNAME、MX、NS、PTR、SOA和SRV等)。
.set debug:显示查询过程的详细信息,这些信息可用于对DNS服务器进行排错。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
网络用户希望用有意义的名字来标识主机,而不是IP地址。为了解决这个需求,应运而生的是域名服务系统(DNS)。它运行在TCP协议之上,负责将域名转换成实际相对应的IP地址,从而在不改变底层协议的寻址方法的基础上,为使用者提供一个直接使用符号名来确定主机的平台。
DNS是一个分层命名系统,名字由若干个标号组成,标号之间用圆点分隔。最右边的是主域名,最左边的是主机名,中间的是子域名。
通常写域名时,最后是不加“.”的,其实这只是一个缩写,最后一个“.”代表的是“根”。如果采用全域名写法,还需要加上这个小点。这在配置DNS时就会见到。
除了以上讲述的名字语法规则和管理机构的设立,域名系统中还包括一个高效、可靠、通用的分布式系统用于名字到地址的映射。将域名映射到IP地址的机制由若干个称为名字服务器(name server)的独立、协作的系统组成。
DNS实际上是一个服务器软件,运行在指定的计算机上,完成域名到IP地址的转换。它把网络中的主机按树形结构分成域和子域,子域名或主机名在上级域名结构中必须是唯一的。每一个子域都有域名服务器,它管理着本域的域名转换,各级服务器构成一棵树。这样,当用户使用域名时,应用程序先向本地域名服务器请求,本地服务器先查找自己的域名库,如果找到该域名,则返回IP地址;如果未找到,则分析域名,然后向相关的上级域名服务器发出申请。这样传递下去,直至有一个域名服务器找到该域名,并返回IP地址。如果没有域名服务器能识别该域名,则认为该域名不可知。
充分利用机器的高速缓存,暂存解析后的IP地址,可以提高DNS的查询效率。用户有时会连续访问相同的因特网地址,DNS在第一次解析该地址后,将其存放在高速缓存中,当用户再次请求时,DNS可直接从缓存中获得IP地址。
35. Windows Server 2008 R2上IIS7.5能提供的服务有( )。
A. DHCP服务
B. FTP服务
C. DNS服务
D. 远程桌面服务
在Windows操作系统中,远程桌面使用的默认端口是( )。
采用DHCP分配IP地址无法做到(28),当客户机发送dhcpdiscover报文时采用(29)方式发送。
FTP客户上传文件时,通过服务器20端口建立的连接是(32),客户端应用进程的端口可以为(33) 。
Microsoft的Web服务器产品为Internet Information Services(IIS),IIS是允许在公共Intranet或Irternet上发布信息的Web服务器,是目前最流行的Web服务器产品之一。ⅡS提供了一个图形界面的管理工具,称为Internet服务管理器,可用于监视配置和控制Internet服务。
IIS是一种Web服务组件,其中包括Web服务器、FTP服务器、NNTP服务器和SMTP服务器,分别用于网页浏览、文件传输、新闻服务和邮件发送等方面,它使得在网络上发布信息成为一件很容易的事。IIS提供ISAPI(Intranet Server API)作为扩展Web服务器功能的编程接口;同时,它还提供一个Internet数据库连接器,可以实现对数据库的查询和更新。
36. 某网络上MAC地址为00-FF-78-ED-20-DE的主机,可首次向网络上的DHCP服务器发送(36)报文以请求IP地址配置的信息,报文的源MAC地址和源IP地址分别是(37)。
A. Dhcp discover
B. Dhcp request
C. Dhcp offer
D. Dhcp ack
采用DHCP分配IP地址无法做到(28),当客户机发送dhcpdiscover报文时采用(29)方式发送。
某DHCP服务器设置的IP地址池从192.168.1.100到192.168.1.200,此时该网段下某台安装Windows系统的工作站启动后,获得的IP地址是1..
下列关于DHCP配置的叙述中,错误的是(35)。
一个IP地址由网络号和主机号两部分组成,由4字节共32位的数字串组成,这4字节通常用小数点分隔。每字节可用十进制表示,如192.46.8.22。IP地址也可以用二进制和十六进制表示。
IP地址分类
IP地址分为5类,如下表所示,其中A、B、C类是常用地址。
Internet的IP地址空间容量
IP地址除了标识一台主机外,还有几种具有特殊意义的形式。
(1)本网络的本台主机。若一个IP地址由全0组成,即0.0.0.0,表示在本网络上本台主机,当一台主机在运行引导程序但又不知道其IP地址时使用该地址。
(2)本网络的某台主机。网络号各位全为"0"的IP地址,表示在这个网络中的特定主机。它用于一个主机向同网络中其他主机发送报文。
(3)网络地址。主机号各位全为"0"的IP地址标识本网络的网络地址,不分配给任何主机。
(4)直接广播地址(有时就简称为广播地址)。主机号各位全为"1"的IP地址,不分配给任何主机,它用于将一个分组发送给特定网络上的所有主机,即对全网广播。
(5)受限(本地)广播地址。受限广播地址是32位全1的IP地址(255.255.255.255)。该地址用于主机配置过程中IP数据报的目的地址,此时,主机可能还不知道它所在网络的网络掩码,甚至连它的IP地址也不知道。在任何情况下,路由器都不转发目的地址为受限的广播地址的数据报,这样的数据报仅出现在本地网络中。
(6)回送地址(Loopback Address)。A类网络地址127.X.X.X是一个保留地址,用于网络软件测试以及本地进程间的通信。
如果一个组织不需要接入到因特网上,但需要在其网络上运行TCP/IP协议,最佳选择是使用私网地址,但Internet中路由器一般不转发目标地址为私网地址的数据包。私网地址如下表所示。
私网IP地址空间
子网划分和子网掩码
由于IP地址的分配是以"网络"为单位进行的,如果一个部门拥有256个用户接入Internet,至少应该为该部门分配两个连续的C类网地址。很显然,这种分配制度导致了大量的IP地址资源的浪费。为了提高IP地址的使用效率,可采用借位的方式将一个网络划分为子网:从主机号最高位开始借位变为新的子网号,所剩余的部分仍为主机号。这使得IP地址的结构分为3部分:网络号、子网号和主机号。
引入子网划分技术后带来了一个重要问题,即主机路由和路由设备如何判断一个给定的IP地址是否已经进行了子网划分,从而能正确地从IP地址中分离出有效的网络标识。通常,将引入子网划分技术前的A、B、C类地址称为有类别(Classful)的IP地址;将引入子网划分技术后的IP地址称为无类别(Classless)的IP地址,并因此引入子网掩码来描述IP地址中关于网络标识和主机号位数的组成情况。
子网掩码(Subnetmask)通常与IP地址配对出现,其功能是告知主机或路由设备,IP地址的哪一部分代表网络号部分,哪一部分代表主机号部分。子网掩码使用与IP地址相同的编码格式,长32位,由一串1和跟随的一串0组成。子网掩码中的1对应于IP地址中的网络号(net-id)和子网号(subnet-id),而子网掩码中的0对应于IP地址中的主机号(host-id)。要得到网络或子网地址,只需将IP地址和子网掩码按位进行"与"运算即可。
子网掩码有两种表示方法。
(1)用点分十进制表示法表示,如256.256.256.0、256.256.256.240等。
(2)在IP地址后加一个"/网络号和子网号的位数"。例如,210.46.12.58/28就表示该IP地址的网络号(net-id)和子网号(subnet-id)共占用28位,主机号占用32-28=4位,如果用点分十进制表示法表示,则子网掩码为256.256.256.240,其二进制表示为
11111111 11111111 11111111 11110000
采用子网掩码是对网络编址的有益补充,但是还存在着一些缺陷,如划分的子网中较小的会浪费许多地址。为了解决这个问题,避免任何可能的地址浪费,就出现了可变长子网掩码(Variable Length Subnetwork Mask, VLSM)的编址方案。VLSM允许一个网络使用不同的网络掩码以适应不同规模的子网要求。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
37. 某网络上MAC地址为00-FF-78-ED-20-DE的主机,可首次向网络上的DHCP服务器发送(36)报文以请求IP地址配置的信息,报文的源MAC地址和源IP地址分别是(37)。
A. 0:0:0:0:0:0:0:0 0.0.0.0
B. 0:0:0:0:0:0:0:0 255.255.255.255
C. 00-FF-78-ED-20-DE 0.0.0.0
D. 00-FF-78-ED-20-DE 255.255.255.255
下列关于DHCP的说法中,错误的是(36)。
采用DHCP分配IP地址无法做到(28),当客户机发送dhcpdiscover报文时采用(29)方式发送。
DHCP服务器设置了C类私有地址作为地址池,某Windows客户端获得的地址是169.254.107.100,出现该现象可能的原因是( )。
38. 用户在登录FTP服务器的过程中,建立TCP连接时使用的默认端口号是( )。
A. 20
B. 21
C. 22
D. 23
SMTP传输的邮件报文采用(31)格式表示。
从FTP服务器下载文件的命令是(49)。
在Linux系统中,使用Apache服务器时默认的Web根目录是(35)。
文件传输协议(File Transfer Protocol, FTP)是在Internet中两个远程计算机之间传送文件的协议。该协议允许用户使用FTP命令对远程计算机中的文件系统进行操作。通过FTP可以传送任意类型、任意大小的文件。Windows Server 2008 R2中IIS 7.5里内置了FTP模块。
TCP是面向连接的通信协议,通过三次握手建立连接,通信完成时要拆除连接,由于TCP是面向连接的,所以只能用于端到端的通信。
TCP提供的是一种可靠的数据流服务,采用“带重传的肯定确认”技术实现传输的可靠性。TCP还采用一种称为“滑动窗口”的方式进行流量控制,所谓窗口,实际表示接收能力,用以限制发送方的发送速度。
如果IP数据包中有已经封装好的TCP数据包,那么IP将把它们向“上”传送到TCP层。TCP将包排序并进行错误检查,同时实现虚电路之间的连接。TCP数据包中包括序号和确认,所以未按照顺序收到的包可以被排序,而损坏的包则可以被重传。
TCP将它的信息发送到更高层的应用程序,例如Telnet的服务程序和客户程序。应用程序轮流将信息送回TCP层,TCP层便将它们向下传送到IP层、设备驱动程序和物理介质,最后传送到接收方。
面向连接的服务(例如Telnet、FTP、rlogin、X Windows和SMTP)需要高度的可靠性,所以它们使用了TCP。DNS在某些情况下使用TCP(发送和接收域名数据库),但使用UDP传送有关单个主机的信息。
文件传输协议(File Transfer Protocol,FTP)用来在计算机之间传输文件。通常,一个用户需要在FTP服务器中进行注册,即建立用户账号,在拥有合法的登录用户名和密码后,才有可能进行有效的FTP连接和登录。FTP在客户端与服务器的内部建立两条TCP连接:一条是控制连接,主要用于传输命令和参数(端口号为21);另一条是数据连接,主要用于传送文件(端口号为20)。
在TCP/IP网络中,传输层的所有服务都包含端口号,它们可以唯一区分每个数据包包含哪些应用协议。端口系统利用这种信息来区分包中的数据,尤其是端口号使一个接收端计算机系统能够确定它所收到的IP包类型,并把它交给合适的高层软件。
端口号和设备IP地址的组合通常称作插口(socket)。任何TCP/IP实现所提供的服务都用知名的1~1023之间的端口号。这些知名端口号由Internet号分配机构(Internet Assigned Numbers Authority,IANA)来管理。例如,SMTP所用的TCP端口号是25,POP3所用的TCP端口号是110,DNS所用的UDP端口号为53,WWW服务使用的TCP端口号为80。FTP在客户与服务器的内部建立两条TCP连接,一条是控制连接,端口号为21;另一条是数据连接,端口号为20。
256~1023之间的端口号通常由Unix系统占用,以提供一些特定的UNIX服务。也就是说,提供一些只有UNIX系统才有的、其他操作系统可能不提供的服务。
在实际应用中,用户可以改变服务器上各种服务的保留端口号,但要注意,在需要服务的客户端也要改为同一端口号。
39. 用户使用域名访问某网站时,是通过( )得到目的主机的IP地址。
A. HTTP
B. ARP
C. DNS
D. ICMP
ARP协议的作用是(18),它的协议数据单元封装在(19)中传送。ARP请求是采用(20)方式发送的。
在域名系统中,根域下面是顶级域(TLD)。在下面的选项中(68)属于全世界通用的顶级域。
ARP表用于缓存设备的IP地址与MAC地址的对应关系,采用ARP表的好处是(22)。
一个IP地址由网络号和主机号两部分组成,由4字节共32位的数字串组成,这4字节通常用小数点分隔。每字节可用十进制表示,如192.46.8.22。IP地址也可以用二进制和十六进制表示。
IP地址分类
IP地址分为5类,如下表所示,其中A、B、C类是常用地址。
Internet的IP地址空间容量
IP地址除了标识一台主机外,还有几种具有特殊意义的形式。
(1)本网络的本台主机。若一个IP地址由全0组成,即0.0.0.0,表示在本网络上本台主机,当一台主机在运行引导程序但又不知道其IP地址时使用该地址。
(2)本网络的某台主机。网络号各位全为"0"的IP地址,表示在这个网络中的特定主机。它用于一个主机向同网络中其他主机发送报文。
(3)网络地址。主机号各位全为"0"的IP地址标识本网络的网络地址,不分配给任何主机。
(4)直接广播地址(有时就简称为广播地址)。主机号各位全为"1"的IP地址,不分配给任何主机,它用于将一个分组发送给特定网络上的所有主机,即对全网广播。
(5)受限(本地)广播地址。受限广播地址是32位全1的IP地址(255.255.255.255)。该地址用于主机配置过程中IP数据报的目的地址,此时,主机可能还不知道它所在网络的网络掩码,甚至连它的IP地址也不知道。在任何情况下,路由器都不转发目的地址为受限的广播地址的数据报,这样的数据报仅出现在本地网络中。
(6)回送地址(Loopback Address)。A类网络地址127.X.X.X是一个保留地址,用于网络软件测试以及本地进程间的通信。
如果一个组织不需要接入到因特网上,但需要在其网络上运行TCP/IP协议,最佳选择是使用私网地址,但Internet中路由器一般不转发目标地址为私网地址的数据包。私网地址如下表所示。
私网IP地址空间
子网划分和子网掩码
由于IP地址的分配是以"网络"为单位进行的,如果一个部门拥有256个用户接入Internet,至少应该为该部门分配两个连续的C类网地址。很显然,这种分配制度导致了大量的IP地址资源的浪费。为了提高IP地址的使用效率,可采用借位的方式将一个网络划分为子网:从主机号最高位开始借位变为新的子网号,所剩余的部分仍为主机号。这使得IP地址的结构分为3部分:网络号、子网号和主机号。
引入子网划分技术后带来了一个重要问题,即主机路由和路由设备如何判断一个给定的IP地址是否已经进行了子网划分,从而能正确地从IP地址中分离出有效的网络标识。通常,将引入子网划分技术前的A、B、C类地址称为有类别(Classful)的IP地址;将引入子网划分技术后的IP地址称为无类别(Classless)的IP地址,并因此引入子网掩码来描述IP地址中关于网络标识和主机号位数的组成情况。
子网掩码(Subnetmask)通常与IP地址配对出现,其功能是告知主机或路由设备,IP地址的哪一部分代表网络号部分,哪一部分代表主机号部分。子网掩码使用与IP地址相同的编码格式,长32位,由一串1和跟随的一串0组成。子网掩码中的1对应于IP地址中的网络号(net-id)和子网号(subnet-id),而子网掩码中的0对应于IP地址中的主机号(host-id)。要得到网络或子网地址,只需将IP地址和子网掩码按位进行"与"运算即可。
子网掩码有两种表示方法。
(1)用点分十进制表示法表示,如256.256.256.0、256.256.256.240等。
(2)在IP地址后加一个"/网络号和子网号的位数"。例如,210.46.12.58/28就表示该IP地址的网络号(net-id)和子网号(subnet-id)共占用28位,主机号占用32-28=4位,如果用点分十进制表示法表示,则子网掩码为256.256.256.240,其二进制表示为
11111111 11111111 11111111 11110000
采用子网掩码是对网络编址的有益补充,但是还存在着一些缺陷,如划分的子网中较小的会浪费许多地址。为了解决这个问题,避免任何可能的地址浪费,就出现了可变长子网掩码(Variable Length Subnetwork Mask, VLSM)的编址方案。VLSM允许一个网络使用不同的网络掩码以适应不同规模的子网要求。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
IP地址用数字表示,使用时难以记忆和书写,因此在IP地址的基础上又发展出了一种符号化的地址方案,用来代替数字型的IP地址,这就是域名。
域名由多个分量组成,分量之间用点号隔开,格式为
*.三级域名.二级域名.顶级域名
例如mail.yctc.edu.cn,其中en是顶级域名,表示中国,edu是二级域名,表示教育机构。各个分量代表不同级别的域名,级别最低的域名写在最左边,级别最高的顶级域名写在最右边,完整的域名不超过255个字符,但域名并不代表计算机所在的物理地点,它只是一个逻辑概念,使用域名有助于记忆。
域名的划分是在顶级域名的基础上注册二级域名,二级域名下还可以注册三级域名等。现在的顶级域名有以下三大类。
①国家顶级域名。国家顶级域名采用ISO 3166的规定制定各个国家的顶级域名。如cn表示中国,us表示美国,jp表示日本等。
②国际顶级域名。采用int,国际性的组织可在int下注册。
③通用顶级域名。常见的通用顶级域名如com表示公司,net表示网络服务机构,org表示非营利性组织,edu表示教育机构(美国专用),gov表示政府部门(美国专用),mil表示军事部门(美国专用),aero表示航空运输企业等。
在国家顶级域名下注册的二级域名由该国家自行确定,我国将二级域名划分为类别域名和行政区域名两大类。其中,类别域名有六个:ac表示科研机构,com表示工、商、金融等企业,edu表示教育机构,gov表示政府部门,net表示互联网络、接入网络的网络信息中心和运行中心,org表示各种非营利性组织。“行政区域名”共有34个,适用于各省、自治区、直辖市。
一般一个单位可以申请注册一个三级域名,一旦拥有一个域名,单位可以自行决定是否需要进一步划分子域,并且不需要向上级报告子域的划分情况。
当用户通过域名访问Internet上的某个主机时,其实是访问其IP地址,那么系统会如何识别哪个域名对应哪个IP地址呢?这是因为这个域名到IP地址的转换是由域名服务器DNS完成的。通过建立DNS数据库,域名服务器记录主机名称与IP地址的对应关系,并为所有访问Internet的客户机提供域名解析服务。
A. 表示IP地址到主机名的映射
B. 表示主机名到IP地址的映射
C. 指定授权服务器
D. 指定区域邮件服务器
在DNS的资源记录中,A记录( )。
在Linux系统中,DNS配置文件的( )参数,用于确定DNS服务器地址。
DNS服务器中的资源记录分成不同类型,其中指明区域主服务器和管理员邮件地址是(51),指明区域邮件服务器地址的是(52)。
网络用户希望用有意义的名字来标识主机,而不是IP地址。为了解决这个需求,应运而生的是域名服务系统(DNS)。它运行在TCP协议之上,负责将域名转换成实际相对应的IP地址,从而在不改变底层协议的寻址方法的基础上,为使用者提供一个直接使用符号名来确定主机的平台。
DNS是一个分层命名系统,名字由若干个标号组成,标号之间用圆点分隔。最右边的是主域名,最左边的是主机名,中间的是子域名。
通常写域名时,最后是不加“.”的,其实这只是一个缩写,最后一个“.”代表的是“根”。如果采用全域名写法,还需要加上这个小点。这在配置DNS时就会见到。
除了以上讲述的名字语法规则和管理机构的设立,域名系统中还包括一个高效、可靠、通用的分布式系统用于名字到地址的映射。将域名映射到IP地址的机制由若干个称为名字服务器(name server)的独立、协作的系统组成。
DNS实际上是一个服务器软件,运行在指定的计算机上,完成域名到IP地址的转换。它把网络中的主机按树形结构分成域和子域,子域名或主机名在上级域名结构中必须是唯一的。每一个子域都有域名服务器,它管理着本域的域名转换,各级服务器构成一棵树。这样,当用户使用域名时,应用程序先向本地域名服务器请求,本地服务器先查找自己的域名库,如果找到该域名,则返回IP地址;如果未找到,则分析域名,然后向相关的上级域名服务器发出申请。这样传递下去,直至有一个域名服务器找到该域名,并返回IP地址。如果没有域名服务器能识别该域名,则认为该域名不可知。
充分利用机器的高速缓存,暂存解析后的IP地址,可以提高DNS的查询效率。用户有时会连续访问相同的因特网地址,DNS在第一次解析该地址后,将其存放在高速缓存中,当用户再次请求时,DNS可直接从缓存中获得IP地址。
每个DNS服务器用资源记录(Resource Record,RR)的集合去实现其负责区域名字的解析。本质上,一个资源记录是一个名字到值的映射或绑定,而资源记录用5元组表示。一个资源记录包括下面几个字段:
名字解析的含义就是在通过名字索引查找到相应的值。
(1)类型字段说明查找到的值如何解释。常用的类型字段主要包括:
.A(Address):值字段给出的是名字字段对应的IP地址,这样就实现了主机名字到IP地址的映射。
.NS(Name Server):值字段给出的是名字服务器的名字,该名字服务器负责解析名字字段指定的域名。
.MX(Mail eXchange):值字段给出的是邮件服务器的名字,该邮件服务器负责接收名字字段指定的域的邮件。
.CNAME(Canonical NAME):值字段给出的是名字字段对应的主机规范名。
(2)分类字段允许定义资源记录的分类。至今,唯一广泛使用的分类是因特网分类,记为IN。
(3)TTL字段指出了该条资源记录的有效期,一旦TTL到期,DNS服务器必须将该资源记录删除。
41. 下列关于防火墙技术的描述中,正确的是( )。
A. 防火墙不能支持网络地址转换
B. 防火墙通常部署在企业内部网和Internet之间
C. 防火墙可以查、杀各种病毒
D. 防火墙可以过滤垃圾邮件
在入侵检测系统中,事件分析器接收事件信息并对其进行分析,判断是否为入侵行为或异常现象,其常用的三种分析方法中不包括(45)..
以下关于入侵检测系统的描述中,正确的是( )。
包过滤防火墙对通过防火墙的数据包进行检查,只有满足条件的数据包才能通过,对数据包的检查内容一般不包括(48)。
防火墙是一种特殊的设备(通常是一个路由器,也可能只是一台运行专用软件的PC),它有选择地过滤或阻塞网络间的流量。通常防火墙都是硬件和软件的结合(如路由器的操作系统和配置),它可能位于两个互相连接的私有网络处,更常见的是在一个私有网络与一个公共网络(比如Internet)连接处。下图所示为常见防火墙的示意图。
防火墙示意图
通过在网络中设置防火墙,可以过滤网络通信的数据包,对非法访问加以拒绝。系统设置防火墙后,可以为网络提供各种保护,主要包括以下几个方面的内容。
◆隔离不信任网段间的直接通信。
◆隔离网络内部不信任网段间的直接通信。
◆拒绝非法访问。
◆地址过滤。
◆访问发起位置的判断。
◆过滤网络服务请求。
◆系统认证。
◆日志功能。
利用防火墙技术,通常能够在内外网之间提供安全保护。但是,仅仅使用防火墙保证网络安全还远远不够,原因如下所述。
◆入侵者可寻找防火墙背后可能敞开的后门。网络结构的改变,有时会造成防火墙上的安全策略失效。
◆入侵者可能就在防火墙内。在每个企业的内部网络中,每个内部网段上除连接着业务主机外,还有许多工作站,这些工作站与主机的通信不需要通过防火墙。如果攻击行为是从这些工作站上发起的,主机将处于无保护的状态。
◆由于性能的限制,防火墙不能提供实时的入侵检测能力。
单一应用防火墙技术,以上问题是不能得到有效解决的。如果公司在重要主机上安装实时入侵检测系统就可以解决由上述情况引起的安全问题。
防火墙是指建立在内外网络边界上的过滤封锁机制。内部网络被认为是安全和可信赖的,而外部网络(通常是Internet)被认为是不安全和不可信赖的。防火墙的作用是防止不希望的、未经授权的通信进出被保护的内部网络,通过边界控制强化内部网络的安全政策。由于防火墙是一种被动技术,它假设了网络边界和服务,因此,对内部的非法访问难以有效地控制,防火墙适合于相对独立的网络。
实现防火墙的产品主要两大类:一类是网络级防火墙,另一类是应用级防火墙。
网络级防火墙
网络级防火墙也称为过滤型防火墙,事实上是一种具有特殊功能的路由器,采用报文动态过滤技术,能够动态地检查流过的TCP/IP报文或分组头,根据企业所定义的规则,决定禁止某些报文通过或者允许某些报文通过,允许通过的报文将按照路由表设定的路径进行信息转发。相应的防火墙软件工作在传输层与网络层。
状态检测防火墙又称动态包过滤,是在传统包过滤上的功能扩展。状态检测防火墙在网络层由一个检查引擎截获数据包并抽取出与应用层状态有关的信息,并以此作为依据决定对该连接是接受还是拒绝。这种技术提供了高度安全的解决方案,同时也具有较好的性能、适应性和可扩展性。
状态检测防火墙一般也包括一些代理级的服务,它们提供附加的对特定应用程序数据内容的支持。状态检测技术最适合提供对UDP协议的有限支持。它将所有通过防火墙的UDP分组均视为一个虚拟连接,当反向应答分组送达时,就认为一个虚拟连接已经建立。
包过滤方式的优点是不用改动客户机和主机上的应用程序,因为它工作在网络层和传输层,与应用层无关。但其弱点也是明显的:过滤判别的依据只是网络层和传输层的有限信息,因而各种安全要求不可能充分满足;在许多过滤器中,过滤规则的数目是有限制的,且随着规则数目的增加,性能会受到很大影响;由于缺少上下文关联信息,不能有效地过滤如UDP、RPC一类的协议;另外,大多数过滤器中缺少审计和报警机制,它只能依据包头信息,而不能对用户身份进行验证,很容易受到地址欺骗型攻击。对安全管理人员素质要求高,建立安全规则时,必须对协议本身及其在不同应用程序中的作用有较深入的理解。因此,过滤器通常和应用网关配合使用,共同组成防火墙系统。
应用级防火墙
应用级防火墙也称为应用网关型防火墙,目前已大多采用代理服务机制,即采用一个网关来管理应用服务,在其上安装对应于每种服务的特殊代码(代理服务程序),在此网关上控制与监督各类应用层服务的网络连接。例如对外部用户(或内部用户)的FTP、TELNET、SMTP等服务请求,检查用户的真实身份、请求合法性和源与目的地IP地址等,从而由网关决定接受或拒绝该服务请求,对于可接受的服务请求由代理服务机制连接内部网与外部网。代理服务程序的配置由企业网络管理员所控制。
目前常用的应用级防火墙大至上有4种类型,分别适合于不同规模的企业内部网:双穴主机网关、屏蔽主机网关、屏蔽子网关和应用代理服务器。一个共同点是需要有一台主机(称为堡垒主机)来负责通信登记、信息转发和控制服务提供等任务。
(1)双穴主机(dual-homed)网关:由堡垒主机作为应用网关,其中装有两块网卡分别连接外因特网和受保护的内部网,该主机运行防火墙软件,具有两个IP地址,并且能隔离内部主机与外部主机之间的所有可能连接。
(2)屏蔽主机(screened host)网关:也称甄别主机网关。在外部Internet与被保护的企业内部网之间插入了堡垒主机和路由器,通常是由IP分组过滤路由器去过滤或甄别可能的不安全连接,再把所有授权的应用服务连接转向应用网关的代理服务机制。
(3)屏蔽子网(screened subnet)网关:也称甄别子网网关,适合于较大规模的网络使用。即在外部因特网与被保护的企业内部网之间插入了一个独立子网,例如在子网中有两个路由器和一台堡垒主机(其上运行防火墙软件作为应用网关),内部网与外部网各有一个分组过滤路由器,可根据不同甄别规则接受或拒绝网络通信,子网中的堡垒主机(或其他可供共享的服务器资源)是外部网与内部网都可能访问的唯一系统。
42. SHA-256是( )算法。
A. 加密
B. 数字签名
C. 认证
D. 报文摘要
匿名FTP访问通常使用(39)作为用户名。
POP3协议采用(61)模式进行通信,当客户机需要服务时,客户端软件与POP3服务器建立(62)连接。
POP3协议采用(26)模式,当客户机需要服务时,客户端软件(OutlookExpress 或FoxMail)与POP3服务器建立(27)连接。
隐式字典的典型压缩算法有LZ77和LZSS。显式字典的典型压缩算法有LZ78和LZW。下面介绍LZ77算法和LZSS算法。
LZ77算法
为了更好地说明LZ77算法的原理,首先介绍该算法中的几个术语。
. 输入流:要被压缩的字符序列。
. 字符:输入流中的基本数据单元。
. 编码位置:输入流中当前要编码的字符位置,指前向缓冲存储器中的开始字符。
. 前向缓存:存放从编码位置到输入流结束的字符序列。
. 窗口:包含W个字符的窗口,字符是从编码位置开始往后数的,也就是最后处理的字符数。
. 指针:指向窗口中的匹配串并包含长度的指针。
LZ77算法的核心是查找从前向缓冲存储器开始的最长的匹配串。该算法的具体执行步骤如下。
步骤1:把编码位置设置到输入流的开始位置。
步骤2:查找窗口中最长的匹配串。
步骤3:以(Pointer, Length)Characters的格式输出。其中Pointer是指向窗口中匹配串的指针,Length表示匹配字符的长度,Characters是前向缓存中不匹配的第1个字符。
步骤4:如果前向缓冲存储器不是空的,则把编码位置和窗口向前移(Length+1)个字符,然后返回步骤2。
LZSS算法
LZSS算法通过输出真实字符解决了在窗口中出现没有匹配串的问题,但这种解决方案包含冗余信息,冗余信息表现在两个方面:一是编码器的输出可能包含空指针;二是编码器可能输出额外字符,即可能包含下一个匹配串中的字符。LZSS算法以比较有效的方法解决了这个问题,它的思想是如果匹配串的长度比指针本身的长度长,就输出指针,否则就输出真实字符。由于输出数据流中包含指针和字符本身,因此为了区分它们就需要有额外的标志位,即ID位。
LZSS算法的具体执行步骤如下。
步骤1:把编码位置置于输入流的开始位置。
步骤2:在前向缓冲存储器中查找窗口中最长的匹配串。
①Pointe:匹配串指针。
②Length:匹配串长度。
步骤3:判断匹配串长度Length是否大于或等于最小匹配串长度(Length≥MIN_ LENGTH)。
是:输出指针,然后把编码位置向前移动Length个字符。
否:输出前向缓冲存储器中的第1个字符,然后把编码位置向前移动1个字符。
步骤4:如果前向缓冲存储器不是空的,则返回步骤2。
在相同的计算环境下,LZSS算法比LZ77可获得更高的压缩比,而译码同样简单。这也就是为什么这种算法成为开发新算法的基础,许多后来开发的文档压缩程序都使用了LZSS的思想,如PKZip、ARJ、LHArc和ZOO等,其差别仅仅是指针的长短和窗口的大小有所不同。
LZSS同样可以和熵编码联合使用,如ARJ就与霍夫曼编码联用,而PKZip则与Shannon-Fano联用,它的后续版本也采用霍夫曼编码。
43. 根据国际标准ITU-T X.509规定,数字证书的一般格式中会包含认证机构的签名,该数据域的作用是( )。
A. 用于标识办法证书的权威机构CA
B. 用于指示建立和签署证书的CA的X.509名字
C. 用于防止证书的伪造
D. 用于传递CA的公钥
用户B收到用户A带数字签名的消息M,为了验证M的真实性,首先需要从CA 获取用户A的数字证书,并利用(42)验证该证书的真伪,然后利..
用户A和B要进行安全通信,通信过程需确认双方身份和消息不可否认,A、B通信时可使用(43)来对用户的身份进行认证,使用(44)确..
Kerberos是一种(44)。
国际电信联盟(International Telecommunication Union, ITU)成立于1934年,是联合国下属的15个专门机构之一。ITU-T的标准化工作由其设立的研究组(Study Group, SG)进行。其中与网络管理有关的研究组有以下4个。
(1)SG2网络运行(Network Operation)。该组进行电信网络的管理和网络服务质量的研究工作。
(2)SG4网络维护(Network Maintenance)。负责电信管理网络(TMN)的研究;有关网络及其组成部分的维护,确立所属的维护机制;由其他研究组提供的专门维护机制的应用。
(3)SG7数据网和开放系统通信(Data Networks and Open Systems Communication)。该组负责系统互联中的管理标准研究。
(4)SG11交换和信令(Switching and Signalling)。该组负责电信管理网络的研究工作。原CCITT已经用X.700系列制定了一系列管理标准(建议书),这些标准和ISO的网络管理标准基本上相同,只是采用了各自的编号体系。而ITU的网络管理标准(建议书)中最著名的是有关电信管理网络的M系列建议书。
国际标准是指国际标准化组织(ISO)、国际电工委员会(IEC)所制定的标准,以及ISO出版的《国际标准题内关键词索引(KWIC Index)》中收录的其他国际组织制定的标准。
44. 以下关于三重DES加密算法的描述中,正确的是( )。
A. 三重DES加密使用两个不同密钥进行三次加密
B. 三重DES加密使用三个不同素钥进行三次加密
C. 三重DES加密的密钥长度是DES密钥长度的三倍
D. 三重DES加密使用一个密钥进行三次加密
MD5是(44)算法,对任意长度的输入计算得到的结果长度为(45)位。
PGP是一种用于电子邮件加密的工具,可提供数据加密和数字签名服务,使用(37)进行数据加密,使用(38)进行数据完整性验证。
三重DES加密使用(41)个密钥对明文进行3次加密,其密钥长度为(42)位。
三重DES是指使用两个密钥,执行3次DES算法,如下图所示。其密钥长度是112位。
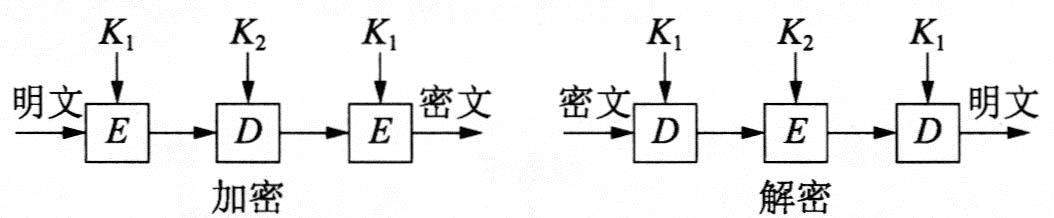
三重DES加密算法
常用的算法描述方法包括流程图、NS盒图、伪代码和决策树。
隐式字典的典型压缩算法有LZ77和LZSS。显式字典的典型压缩算法有LZ78和LZW。下面介绍LZ77算法和LZSS算法。
LZ77算法
为了更好地说明LZ77算法的原理,首先介绍该算法中的几个术语。
. 输入流:要被压缩的字符序列。
. 字符:输入流中的基本数据单元。
. 编码位置:输入流中当前要编码的字符位置,指前向缓冲存储器中的开始字符。
. 前向缓存:存放从编码位置到输入流结束的字符序列。
. 窗口:包含W个字符的窗口,字符是从编码位置开始往后数的,也就是最后处理的字符数。
. 指针:指向窗口中的匹配串并包含长度的指针。
LZ77算法的核心是查找从前向缓冲存储器开始的最长的匹配串。该算法的具体执行步骤如下。
步骤1:把编码位置设置到输入流的开始位置。
步骤2:查找窗口中最长的匹配串。
步骤3:以(Pointer, Length)Characters的格式输出。其中Pointer是指向窗口中匹配串的指针,Length表示匹配字符的长度,Characters是前向缓存中不匹配的第1个字符。
步骤4:如果前向缓冲存储器不是空的,则把编码位置和窗口向前移(Length+1)个字符,然后返回步骤2。
LZSS算法
LZSS算法通过输出真实字符解决了在窗口中出现没有匹配串的问题,但这种解决方案包含冗余信息,冗余信息表现在两个方面:一是编码器的输出可能包含空指针;二是编码器可能输出额外字符,即可能包含下一个匹配串中的字符。LZSS算法以比较有效的方法解决了这个问题,它的思想是如果匹配串的长度比指针本身的长度长,就输出指针,否则就输出真实字符。由于输出数据流中包含指针和字符本身,因此为了区分它们就需要有额外的标志位,即ID位。
LZSS算法的具体执行步骤如下。
步骤1:把编码位置置于输入流的开始位置。
步骤2:在前向缓冲存储器中查找窗口中最长的匹配串。
①Pointe:匹配串指针。
②Length:匹配串长度。
步骤3:判断匹配串长度Length是否大于或等于最小匹配串长度(Length≥MIN_ LENGTH)。
是:输出指针,然后把编码位置向前移动Length个字符。
否:输出前向缓冲存储器中的第1个字符,然后把编码位置向前移动1个字符。
步骤4:如果前向缓冲存储器不是空的,则返回步骤2。
在相同的计算环境下,LZSS算法比LZ77可获得更高的压缩比,而译码同样简单。这也就是为什么这种算法成为开发新算法的基础,许多后来开发的文档压缩程序都使用了LZSS的思想,如PKZip、ARJ、LHArc和ZOO等,其差别仅仅是指针的长短和窗口的大小有所不同。
LZSS同样可以和熵编码联合使用,如ARJ就与霍夫曼编码联用,而PKZip则与Shannon-Fano联用,它的后续版本也采用霍夫曼编码。
45. 以下关于HTTP和HTTPS的描述中,不正确的是( )。
A. 部署HTTPS需要到CA申请证书
B. HTTP信息采用明文传输,HTTPS则采用SSL加密传输
C. HTTP和HTTPS使用的默认端口都是80
D. HTTPS由SSL+HTTP构建,可进行加密传输、身份认证,比HTTP安全
下述协议中与安全电子邮箱服务无关的是( )。
PGP的功能中不包括( )。
HTTPS采用(39)协议实现安全网站访问。
HTTPS是以安全为目标的HTTP通道,简单讲是HTTP的安全版。它是对HTTP协议的扩展,目的是保证商业贸易的传输安全,工作在应用层。由于SSL的迅速出现,加上SSL工作在传输层,适用于所有TCP/IP应用,采用443号端口,而HTTPS只能够工作在HTTP协议层,仅限于Web应用。
46. 假设有一个LAN,每10分钟轮询所有被管理设备一次,管理报文的处理时间是50ms,网络延迟为1ms,没有明显的网络拥塞,单个轮询需要时间大约为0.2s,则该管理站最多可支持( )个设备。
A. 4500
B. 4000
C. 3500
D. 3000
在SNMP协议中,当代理收到一个GET请求时,如果有一个值不可或不能提供,则返回(46)。
SNMP采用UDP提供的数据报服务,这是由于(47)。
SNMP MIB中被管对象的Access属性不包括(57)。
轮询是一种请求一响应式的交互方式。管理站向代理发出请求,询问(管理站)所需要的信息值,代理响应管理站,从管理信息库中取得相应的信息,返回给管理站。
47. 某主机能够ping通网关,但是ping外网主机IP地址时显示“目标主机不可达”,出现该故障的原因可能是( )。
A. 本机TCP/IP协议安装错误
B. 域名服务工作不正常
C. 网关路由错误
D. 本机路由错误
网关是最复杂的网络互联设备,它用于连接网络层之上执行不同协议的子网,组成异构型的互联网。为了实现异构型设备之间的通信,网关要对不同的传输层、会话层、表示层和应用层协议进行翻译和变换。
由于工作复杂,因此用网关进行网络互联时效率比较低,而且透明性不好。因而网关往往用于针对某种特殊用途的专用连接。有时并不划分路由器和网关,而把网络层及其以上进行协议转换的互联设备统称为网关。
一个IP地址由网络号和主机号两部分组成,由4字节共32位的数字串组成,这4字节通常用小数点分隔。每字节可用十进制表示,如192.46.8.22。IP地址也可以用二进制和十六进制表示。
IP地址分类
IP地址分为5类,如下表所示,其中A、B、C类是常用地址。
Internet的IP地址空间容量
IP地址除了标识一台主机外,还有几种具有特殊意义的形式。
(1)本网络的本台主机。若一个IP地址由全0组成,即0.0.0.0,表示在本网络上本台主机,当一台主机在运行引导程序但又不知道其IP地址时使用该地址。
(2)本网络的某台主机。网络号各位全为"0"的IP地址,表示在这个网络中的特定主机。它用于一个主机向同网络中其他主机发送报文。
(3)网络地址。主机号各位全为"0"的IP地址标识本网络的网络地址,不分配给任何主机。
(4)直接广播地址(有时就简称为广播地址)。主机号各位全为"1"的IP地址,不分配给任何主机,它用于将一个分组发送给特定网络上的所有主机,即对全网广播。
(5)受限(本地)广播地址。受限广播地址是32位全1的IP地址(255.255.255.255)。该地址用于主机配置过程中IP数据报的目的地址,此时,主机可能还不知道它所在网络的网络掩码,甚至连它的IP地址也不知道。在任何情况下,路由器都不转发目的地址为受限的广播地址的数据报,这样的数据报仅出现在本地网络中。
(6)回送地址(Loopback Address)。A类网络地址127.X.X.X是一个保留地址,用于网络软件测试以及本地进程间的通信。
如果一个组织不需要接入到因特网上,但需要在其网络上运行TCP/IP协议,最佳选择是使用私网地址,但Internet中路由器一般不转发目标地址为私网地址的数据包。私网地址如下表所示。
私网IP地址空间
子网划分和子网掩码
由于IP地址的分配是以"网络"为单位进行的,如果一个部门拥有256个用户接入Internet,至少应该为该部门分配两个连续的C类网地址。很显然,这种分配制度导致了大量的IP地址资源的浪费。为了提高IP地址的使用效率,可采用借位的方式将一个网络划分为子网:从主机号最高位开始借位变为新的子网号,所剩余的部分仍为主机号。这使得IP地址的结构分为3部分:网络号、子网号和主机号。
引入子网划分技术后带来了一个重要问题,即主机路由和路由设备如何判断一个给定的IP地址是否已经进行了子网划分,从而能正确地从IP地址中分离出有效的网络标识。通常,将引入子网划分技术前的A、B、C类地址称为有类别(Classful)的IP地址;将引入子网划分技术后的IP地址称为无类别(Classless)的IP地址,并因此引入子网掩码来描述IP地址中关于网络标识和主机号位数的组成情况。
子网掩码(Subnetmask)通常与IP地址配对出现,其功能是告知主机或路由设备,IP地址的哪一部分代表网络号部分,哪一部分代表主机号部分。子网掩码使用与IP地址相同的编码格式,长32位,由一串1和跟随的一串0组成。子网掩码中的1对应于IP地址中的网络号(net-id)和子网号(subnet-id),而子网掩码中的0对应于IP地址中的主机号(host-id)。要得到网络或子网地址,只需将IP地址和子网掩码按位进行"与"运算即可。
子网掩码有两种表示方法。
(1)用点分十进制表示法表示,如256.256.256.0、256.256.256.240等。
(2)在IP地址后加一个"/网络号和子网号的位数"。例如,210.46.12.58/28就表示该IP地址的网络号(net-id)和子网号(subnet-id)共占用28位,主机号占用32-28=4位,如果用点分十进制表示法表示,则子网掩码为256.256.256.240,其二进制表示为
11111111 11111111 11111111 11110000
采用子网掩码是对网络编址的有益补充,但是还存在着一些缺陷,如划分的子网中较小的会浪费许多地址。为了解决这个问题,避免任何可能的地址浪费,就出现了可变长子网掩码(Variable Length Subnetwork Mask, VLSM)的编址方案。VLSM允许一个网络使用不同的网络掩码以适应不同规模的子网要求。
ping通过发送"Internet控制报文协议(ICMP)"回送请求/应答报文来验证与另一台TCP/IP计算机的IP级连接。回送请求/应答报文的接收情况将和往返过程的次数一起显示出来。ping是用于检测网络连接性、可到达性和名称解析的疑难问题的主要TCP/IP命令。如果不带参数,ping将显示帮助。
1)语法格式
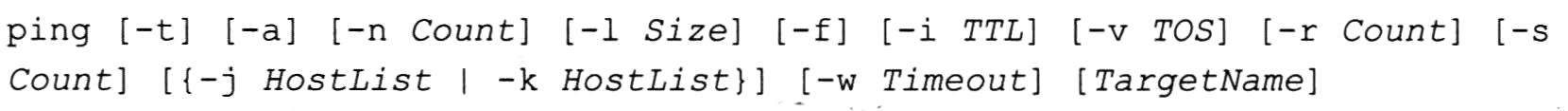
2)参数说明
参数如下表所示。

ping的选项

IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
Internet上每台主机都必须有一个唯一的标识,即主机的IP地址,IP协议就是根据IP地址实现信息传递的。IP地址分为IPv4和IPv6两个版本。
(1) IPv4
IP地址由32位(即4字节)二进制数组成,将每个字节作为一段并以十进制数来表示,每段间用“.”分隔。例如,202.96.209.5就是一个合法的IP地址。
IP地址由网络标识和主机标识两部分组成。常用的IP地址有A、B、C三类,每类均规定了网络标识和主机标识在32位中所占的位数,区别如下:
.A类:一般分配给具有大量主机的网络使用,第一个字节十进制值为0~126。
.B类:通常分配给规模中等的网络使用,第一个字节十进制值为l28~191。
.C类:通常分配给小型局域网使用,第一个字节十进制值为192~223。
IP地址由世界各大地区的权威机构Inter NIC(Internet Network Information Center)管理和分配。
将主机标识域进一步划分为子网标识和子网主机标识,通过灵活定义子网标识域的位数,可以控制每个子网的规模。将一个大型网络划分为若干个既相对独立又相互联系的子网后,网络内部各子网便可独立寻址和管理,各子网间通过跨子网的路由器连接,这样也提高了网络的安全性。
利用子网掩码可以判断两台主机是否在同一子网中。子网掩码与IP地址一样也是32位二进制数,不同的是它的子网主机标识部分为全“0”。若两台主机的IP地址分别与它们的子网掩码相“与”后的结果相同,则说明这两台主机在同一子网中。
(2)IPv6
IPv6是由IETF小组设计的用来替代现行的IPv4协议的一种新的IP协议。
IPv6由128位(16字节)二进制数组成,RFC1884中规定把IPv6表示为8个16位的无符号整数,每个整数用4个十六进制位表示,中间用冒号分隔,例如:3ffe:3201:1401:1280:c8ff:fe4d:db39:1984。
IPv6具有如下优点:
.提供更大的地址空间,能够实现即插即用和灵活的重新编址。
.更简单的头信息,能够使路由器提供更有效率的路由转发。
.与移动IP和IPSec保持兼容的移动性和安全性。
.提供丰富的从IPv4到IPv6的转换和互操作方法。
48. Windows 系统中的SNMP服务程序包括SNMPService和SNMPTrap两个。其中SNMPService接收SNMP请求报文。根据要求发送响应报文;而SNMPTrap的作用是( )。
A. 处理本地计算机上的陷入信息
B. 被管对象检测到差错,发送给管理站
C. 接收本地或远程SNMP代理发送的陷入信息
D. 处理远程计算机发来的陷入信息
1)SNMP概述
SNMP的前身是简单网关监控协议(SGMP),用来对通信线路进行管理。随后对其改进并加入了符合Internet定义的SMI和MIB体系结构,改进后的协议就是著名的SNMP。SNMP的目标是管理Internet上众多厂家生产的软硬件平台,因此SNMP受Internet标准网络管理框架的影响很大。SNMP的体系结构如下图所示。

SNMP的体系结构
SNMP的体系结构围绕以下4个概念和目标进行设计。
◆使管理代理的软件成本尽可能低。
◆最大限度地保持远程管理的功能,以便充分利用Internet上的网络资源。
◆体系结构必须有扩充的余地。
◆保持SNMP的独立性,不依赖于具体的计算机、网关和网络传输协议。
在SNMP的改进版本SNMPv2中,又加入了保证SNMP体系本身安全性的目标。
另外,SNMP中提供了以下4类管理操作。
◆get操作:用来提取特定的网络管理信息。
◆get-next操作:通过遍历操作来提供强大的管理信息的提取能力。
◆set操作:用来对管理信息进行控制(修改、设置)。
◆trap操作:用来报告重要的事件。
各种操作的执行如下图所示。

SNMP的4种操作
2)SNMP管理控制框架与实现
(1)SNMP管理控制框架。
SNMP定义了管理进程(Manager)和管理代理(Agent)之间的关系,这个关系被称为共同体(Community)。描述共同体的语义是非常复杂的,但其句法却很简单。位于网络管理工作站(运行管理进程)和各网络元素上,利用SNMP相互通信,并对网络进行管理的软件统称为SNMP应用实体。若干个应用实体和SNMP组合起来形成一个共同体,不同的共同体之间用名字来区分。共同体的名字必须符合Internet的层次结构命名规则,由非保留字符串组成。此外,一个SNMP应用实体可以加入多个共同体。
SNMP的应用实体对Internet管理信息库中的管理对象进行操作。一个SNMP应用实体可操作的管理对象子集称为SNMP MIB授权范围。SNMP应用实体对授权范围内管理对象的访问还有进一步的访问控制限制,比如只读、读/写等;SNMP体系结构中要求每个共同体都规定其授权范围及其对每个对象的访问方式。记录这些定义的文件被称为共同体定义文件。
SNMP的报文总是源自每个应用实体,报文中包括该应用实体所在的共同体的名字。这种报文在SNMP中称为有身份标识的报文,共同体名字是在管理进程和管理代理之间交换管理信息报文时使用的。管理信息报文中包括以下两部分内容。
◆共同体名:加上发送方的一些标识信息(附加信息),用以验证发送方确实是共同体中的成员。共同体实际上就是用来实现管理应用实体之间身份鉴别的机制。
◆数据:这是两个管理应用实体之间真正需要交换的信息。
第三版本前的SNMP只是实现了简单的身份鉴别,接收方仅凭共同体名来判定收发双方是否在同一个共同体中,而前面提到的附加信息尚未应用。接收方在验明发送报文的管理代理或管理进程的身份后要对其访问权限进行检查。访问权限检查涉及以下因素。
◆一个共同体内各成员可以对哪些对象进行读、写等管理操作,这些可读写对象称为该共同体的授权对象(在授权范围内)。
◆共同体成员对授权范围内每个对象定义了访问模式:只读或可读写。
◆规定授权范围内每个管理对象(类)可进行的操作(包括get、get-next、set和trap)。
◆管理信息库(MIB)限制对每个对象的访问方式(如MIB中可以规定哪些对象只能读而不能写等)。
管理代理通过上述预先定义的访问模式和权限,来决定共同体中其他成员要求的管理对象访问(操作)是否允许。共同体概念同样适用于转换代理(Proxy Agent),只不过转换代理中包含的对象主要是其他设备的内容。
(2)SNMP的实现方式。
为了提供遍历管理信息库的手段,SNMP在其MIB中采用了树状命名方法对每个管理对象的实例进行命名。每个对象实例的名字都由对象类名字加上一个后缀构成,对象类的名字是不会相互重复的,因而不同对象类的对象实例之间也很少有重名的危险。
在共同体的定义中一般要规定该共同体授权的管理对象的范围,相应地也就规定了哪些对象实例是该共同体的"管辖范围"。据此,共同体的定义可以想象为一个多叉树,以字典序提供了遍历所有管理对象实例的手段。有了这个手段,SNMP就可以使用get-next操作符,顺序地从一个对象找到下一个对象。get-next(object-instance)操作返回的结果是一个对象实例的标识符及其相关信息,该对象实例在上面的多叉树中紧排在指定标识符object-instance对象的后面。这种手段的优点在于:即使不知道管理对象实例的具体名字,管理系统也能逐个地找到它,并提取到它的有关信息。遍历所有管理对象的过程可以从第一个对象实例开始(这个实例一定要给出),然后逐次使用get-next,直到返回一个差错(表示不存在的管理对象实例)结束(完成遍历)。
由于信息是以表格形式(一种数据结构)存放的,在SNMP的管理概念中,把所有表格都视为子树,其中一张表格(及其名字)是相应子树的根节点,每个列是根下面的子节点,一列中的每个行则是该列节点下面的子节点,并且是子树的叶节点,如下图所示。
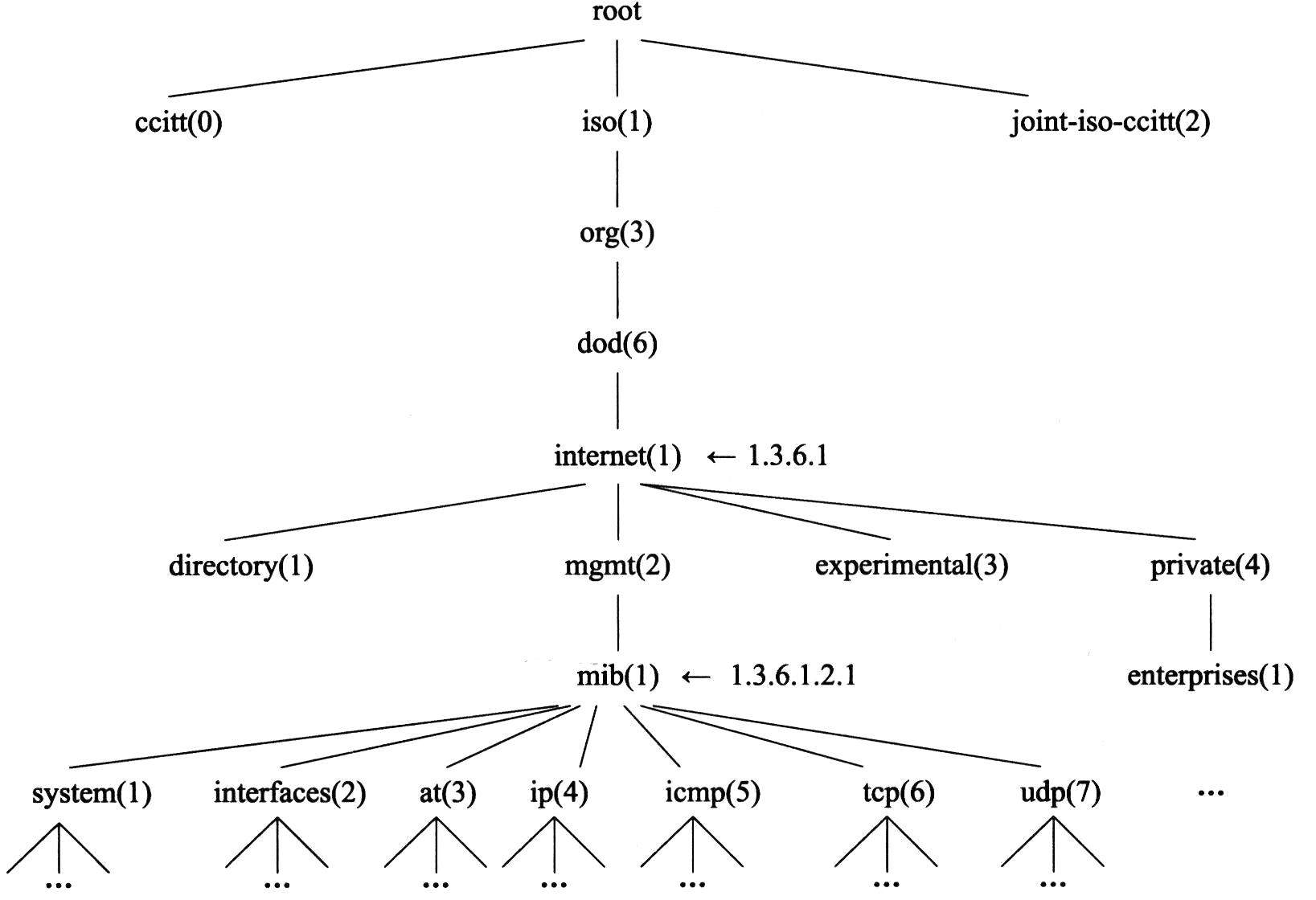
管理信息库中的对象标识
因此,按照前面的子树遍历思路,对表格的遍历是先访问第一列的所有元素,再访问第二列的所有元素……直到最后一个元素。若试图得到最后一个元素的"下一个"元素,则返回差错标记。
SNMP中的各种管理信息大多以表格形式存在,一个表格对应一个对象类,每个元素对应于该类的一个对象实例。那么,管理信息表对象中单个元素(对象实例)的操作可以用前面提到的get-next方法,也可以用get/set等操作。下面主要介绍表格内一行信息的整体操作。
◆增加一行:通过SNMP只用一次set操作就可在一个表格中增加一行。操作中的每个变量都对应于待增加行中的一个列元素,包括对象实例的标识符。
◆删除一行:删除一行也可以通过SNMP调用set操作,将该行中的任意一个元素(对象实例)设置成"非法"即可。
至于删除一行时,表中的一行元素是否真的在表中消失,则与每个设备(管理代理)的具体实现有关,因此管理进程必须能通过各数据字段的内容来判断数据的合法性。
3)SNMP协议
SNMP是一个异步的请求/响应协议,即SNMP的请求和响应之间没有必定的时间顺序关系,换句话说,SNMP是一个面向无连接的协议。这样,SNMP实体不需要在发出请求后立即等待响应的到来,因此SNMP响应也可能丢失或出现错误。SNMP中设计了四种基本协议的交互过程。
第一种情况是管理进程从管理代理处提取管理信息。管理进程通过SNMP和传输网络发送get-request给管理代理,请求中包括管理对象的标识符等参数;管理代理收到请求后返回相应内容的get-response,响应中包括待提取的管理信息。
第二种情况是管理进程在管理代理的可见范围内遍历一部分管理对象实例。管理进程通过SNMP和传输网络发送get-next-request给管理代理,管理代理收到后完成遍历的一次操作,用get-response将遍历结果返回给管理进程。
第三种情况是管理进程在管理代理中存储信息,即对管理代理的管理信息库(MIB)进行写操作(包括设置工作参数)。管理进程发送一个set-request给管理代理,由管理代理完成set操作,然后用set-response返回操作结果。
第四种情况则是管理代理主动向管理进程报告事件。管理代理通过SNMP和传输网络将trap发送给管理进程,这个操作没有响应。
注意:上面的各个请求都是管理进程发给管理代理的,响应则都是由管理代理发给管理进程的。只有trap是无响应的,由管理代理单向发给管理进程。另外,请求、响应和trap的传输处理都要受"共同体"定义的限制,包括访问权限。
SNMP协议是一个对称协议,没有主从关系。SNMP上的管理进程和管理代理都可以得到SNMP完全相同的服务。下面对SNMP协议的部分特点和关键内容进行介绍。
(1)管理信息报文。
在大多数SNMP操作中都使用一个相同的报文数据结构。对于前面提到的身份鉴别方法,报文中包含三种数据(信息)传递给专门的"身份鉴别实体":共同体名称、有关数据和发送方SNMP实体的传输层地址。
身份鉴别实体负责验证发送方是否是合法的对等实体,并返回两种可能的结果:一种结果是返回本次报文中的SNMP协议数据类型和发送方SNMP实体的权限标识符;另一种结果是返回例外。其中第一种结果表明发送方SNMP实体确实是本共同体的成员之一,接收方SNMP实体接下来对它进行处理。第二种结果("例外")表明发送方SNMP实体并非本共同体成员,不能接受此报文,并且接收方SNMP实体还可能根据配置产生一个"身份非法"的trap事件。
(2)协议数据单元及其管理操作。
SNMP协议实体之间的协议数据单元(PDU)只有两种不同的结构和格式,一个PDU格式在大部分操作中使用,而另一个则只在trap操作中作为trap的协议数据单元。
PDU一般包含多个代表特殊意义的字段:request-id是一个整数值,用来区分不同的PDU;error-status反映管理操作是成功还是失败;error-index表明操作中哪个变量错误;variable-bindings是一系列变量的清单,序列中每一项包含一个变量名及其变量值。
在SNMP中,接收方完成身份鉴别并得到共同体定义信息之后,SNMP实体根据PDU内容执行以下几种操作:get操作,根据变量名取出指定的对象实例;get-next操作,该操作与get操作不同,不是取变量名指定的对象实例,而是取出变量名指定的对象实例的按字典排序的下一个对象实例;set操作,对指定对象实体的值用请求中的新值替换;get-response对get/set报文做出响应并返回操作结果,收到该响应报文的操作请求方首先根据报文中的request-id在记录中查找有无这个序号的请求,如果没有则丢弃该响应,否则接收该响应,管理进程要进行响应处理。
(3)trap操作。
trap是一种捕捉事件并报告的操作,实际上几乎所有网络管理系统和管理协议都具有这种机制。trap在OSI网络管理国际标准中称为"事件和通报",一般都简称为事件报告。
为了减少管理信息的业务流量,管理代理负责对管理对象的trap进行检查,管理检查可以设置检查条件,这样,管理进程就可以在一定程度上控制trap报告过程。引入trap报告的最大好处是许多重要事件的发生得以及时让管理进程知道。因为一般只有比较关键的trap事件才确实需要报告,再加上每个trap事件都很简短,因此由于trap而引入的不确定管理信息业务量是较少的,但却能大大改善网络管理的时效性。
由于事件多种多样,各种事件的发生环境也不一样,trap操作的复杂性比前面讲的几种操作都大,SNMP的trap操作PDU中的字段类型也较多。这些trap操作PDU中的字段包括:enterprise,记录发送trap事件的管理代理的标识符;agent-addr,管理代理的网络节点地址;generic-trap,描述该trap操作报告是哪一种异常事件;specific-trap,给出各管理代理自行定义的trap事件代码;time-stam,表示trap事件发生的时刻;variable-bindings,给出一组变量,这些变量及其值给出了与trap事件有关的详细信息。
当管理代理检测到一个例外或异常事件发生时,管理代理首先要判断需要将该事件报告给哪个或哪些管理进程。对每个管理进程,管理代理要选择相应的共同体号,由SNMP协议实体按照前面的字段格式构造trap报告的PDU,再将其发送出去。
(4)SNMP PDU的传输。
SNMP的设计是独立于具体的传输网络的,也就是说,它既可以在TCP/IP的支持下操作,也可以在OSI的传输层协议支持下完成操作,甚至可以在以太网的直接支持下实现操作。其中对OSI传输层的服务没有要求,既可以是有连接的服务,也可以是无连接的服务。为了实现上述目标,Internet组织定义了若干映射标准,规定了如何将SNMP协议数据单元PDU映射到下层的无连接传输请求上去。
在所有各种映射定义中,有一点是相同的,即所有SNMP报文数据是通过一个"顺序化"过程在网络上传输的,这个顺序化过程可以将任意结构的数据编码成一个有序的字符串进行传送。对方收到这些字符串后则按照完全相同的语法将它们解码成原来的数据结构。
(5)MIB中为SNMP定义的管理对象。
在Internet的第二版管理信息库(MIB-Ⅱ)中,为SNMP应用实体定义了若干管理对象,其中包括SNMP的各种服务原语、各种收发协议数据单元、各种参数指示或统计变量等,凡SNMP中可操作的数据结构或变量都包括在内,下面将详细介绍。
SNMP是TCP/IP协议族的一部分,提供了在系统之间监视并交流状态信息的能力。基于Windows的SNMP使用由管理系统和代理组成的分布式体系结构。
Windows的SNMP服务包括两个应用程序,一个是SNMP代理服务程序snmp.exe,另一个是SNMP陷入服务程序snmptrap.exe。
当前能够作为管理进程运行的网络管理软件典型的有惠普公司的OpenView、IBM公司的NetView、Sun公司的SunNet以及Cabletron公司的Spectrum。这些网络管理系统都在支持本公司网络管理方案的同时,支持通过SNMP对网络对象进行管理。
49. 某主机IP地址为192.168.88.156,其网络故障表现为时断时续。通过软件进行抓包分析,结果如下图所示,造成该主机网络故障的原因可能是( )。
A. 网关地址配置不正确
B. DNS配置不正确或者工作不正常
C. 该网络遭到ARP病毒的攻击
D. 该主机网卡硬件故障
一个IP地址由网络号和主机号两部分组成,由4字节共32位的数字串组成,这4字节通常用小数点分隔。每字节可用十进制表示,如192.46.8.22。IP地址也可以用二进制和十六进制表示。
IP地址分类
IP地址分为5类,如下表所示,其中A、B、C类是常用地址。
Internet的IP地址空间容量
IP地址除了标识一台主机外,还有几种具有特殊意义的形式。
(1)本网络的本台主机。若一个IP地址由全0组成,即0.0.0.0,表示在本网络上本台主机,当一台主机在运行引导程序但又不知道其IP地址时使用该地址。
(2)本网络的某台主机。网络号各位全为"0"的IP地址,表示在这个网络中的特定主机。它用于一个主机向同网络中其他主机发送报文。
(3)网络地址。主机号各位全为"0"的IP地址标识本网络的网络地址,不分配给任何主机。
(4)直接广播地址(有时就简称为广播地址)。主机号各位全为"1"的IP地址,不分配给任何主机,它用于将一个分组发送给特定网络上的所有主机,即对全网广播。
(5)受限(本地)广播地址。受限广播地址是32位全1的IP地址(255.255.255.255)。该地址用于主机配置过程中IP数据报的目的地址,此时,主机可能还不知道它所在网络的网络掩码,甚至连它的IP地址也不知道。在任何情况下,路由器都不转发目的地址为受限的广播地址的数据报,这样的数据报仅出现在本地网络中。
(6)回送地址(Loopback Address)。A类网络地址127.X.X.X是一个保留地址,用于网络软件测试以及本地进程间的通信。
如果一个组织不需要接入到因特网上,但需要在其网络上运行TCP/IP协议,最佳选择是使用私网地址,但Internet中路由器一般不转发目标地址为私网地址的数据包。私网地址如下表所示。
私网IP地址空间
子网划分和子网掩码
由于IP地址的分配是以"网络"为单位进行的,如果一个部门拥有256个用户接入Internet,至少应该为该部门分配两个连续的C类网地址。很显然,这种分配制度导致了大量的IP地址资源的浪费。为了提高IP地址的使用效率,可采用借位的方式将一个网络划分为子网:从主机号最高位开始借位变为新的子网号,所剩余的部分仍为主机号。这使得IP地址的结构分为3部分:网络号、子网号和主机号。
引入子网划分技术后带来了一个重要问题,即主机路由和路由设备如何判断一个给定的IP地址是否已经进行了子网划分,从而能正确地从IP地址中分离出有效的网络标识。通常,将引入子网划分技术前的A、B、C类地址称为有类别(Classful)的IP地址;将引入子网划分技术后的IP地址称为无类别(Classless)的IP地址,并因此引入子网掩码来描述IP地址中关于网络标识和主机号位数的组成情况。
子网掩码(Subnetmask)通常与IP地址配对出现,其功能是告知主机或路由设备,IP地址的哪一部分代表网络号部分,哪一部分代表主机号部分。子网掩码使用与IP地址相同的编码格式,长32位,由一串1和跟随的一串0组成。子网掩码中的1对应于IP地址中的网络号(net-id)和子网号(subnet-id),而子网掩码中的0对应于IP地址中的主机号(host-id)。要得到网络或子网地址,只需将IP地址和子网掩码按位进行"与"运算即可。
子网掩码有两种表示方法。
(1)用点分十进制表示法表示,如256.256.256.0、256.256.256.240等。
(2)在IP地址后加一个"/网络号和子网号的位数"。例如,210.46.12.58/28就表示该IP地址的网络号(net-id)和子网号(subnet-id)共占用28位,主机号占用32-28=4位,如果用点分十进制表示法表示,则子网掩码为256.256.256.240,其二进制表示为
11111111 11111111 11111111 11110000
采用子网掩码是对网络编址的有益补充,但是还存在着一些缺陷,如划分的子网中较小的会浪费许多地址。为了解决这个问题,避免任何可能的地址浪费,就出现了可变长子网掩码(Variable Length Subnetwork Mask, VLSM)的编址方案。VLSM允许一个网络使用不同的网络掩码以适应不同规模的子网要求。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
Internet上每台主机都必须有一个唯一的标识,即主机的IP地址,IP协议就是根据IP地址实现信息传递的。IP地址分为IPv4和IPv6两个版本。
(1) IPv4
IP地址由32位(即4字节)二进制数组成,将每个字节作为一段并以十进制数来表示,每段间用“.”分隔。例如,202.96.209.5就是一个合法的IP地址。
IP地址由网络标识和主机标识两部分组成。常用的IP地址有A、B、C三类,每类均规定了网络标识和主机标识在32位中所占的位数,区别如下:
.A类:一般分配给具有大量主机的网络使用,第一个字节十进制值为0~126。
.B类:通常分配给规模中等的网络使用,第一个字节十进制值为l28~191。
.C类:通常分配给小型局域网使用,第一个字节十进制值为192~223。
IP地址由世界各大地区的权威机构Inter NIC(Internet Network Information Center)管理和分配。
将主机标识域进一步划分为子网标识和子网主机标识,通过灵活定义子网标识域的位数,可以控制每个子网的规模。将一个大型网络划分为若干个既相对独立又相互联系的子网后,网络内部各子网便可独立寻址和管理,各子网间通过跨子网的路由器连接,这样也提高了网络的安全性。
利用子网掩码可以判断两台主机是否在同一子网中。子网掩码与IP地址一样也是32位二进制数,不同的是它的子网主机标识部分为全“0”。若两台主机的IP地址分别与它们的子网掩码相“与”后的结果相同,则说明这两台主机在同一子网中。
(2)IPv6
IPv6是由IETF小组设计的用来替代现行的IPv4协议的一种新的IP协议。
IPv6由128位(16字节)二进制数组成,RFC1884中规定把IPv6表示为8个16位的无符号整数,每个整数用4个十六进制位表示,中间用冒号分隔,例如:3ffe:3201:1401:1280:c8ff:fe4d:db39:1984。
IPv6具有如下优点:
.提供更大的地址空间,能够实现即插即用和灵活的重新编址。
.更简单的头信息,能够使路由器提供更有效率的路由转发。
.与移动IP和IPSec保持兼容的移动性和安全性。
.提供丰富的从IPv4到IPv6的转换和互操作方法。
50. Windows中标准的SNMP Service和SNMP Trap分别使用的默认UDP端口是( )。
A. 25和26
B. 160和161
C. 161和162
D. 161和160
UDP是TCP/IP协议簇中等同于TCP的通信协议,其差异在于:UDP直接利用IP进行UDP数据报的传输,因此UDP提供的是无连接、不可靠的数据报投递服务。
UDP常用于数据量较少的数据传输。例如,域名系统中域名地址/IP地址的映射请求和应答采用UDP进行传输,以减少TCP连接的过程,提高工作效率。
当使用UDP传输信息流时,用户负责解决排序、差错确认等问题。
1)SNMP概述
SNMP的前身是简单网关监控协议(SGMP),用来对通信线路进行管理。随后对其改进并加入了符合Internet定义的SMI和MIB体系结构,改进后的协议就是著名的SNMP。SNMP的目标是管理Internet上众多厂家生产的软硬件平台,因此SNMP受Internet标准网络管理框架的影响很大。SNMP的体系结构如下图所示。
SNMP的体系结构
SNMP的体系结构围绕以下4个概念和目标进行设计。
◆使管理代理的软件成本尽可能低。
◆最大限度地保持远程管理的功能,以便充分利用Internet上的网络资源。
◆体系结构必须有扩充的余地。
◆保持SNMP的独立性,不依赖于具体的计算机、网关和网络传输协议。
在SNMP的改进版本SNMPv2中,又加入了保证SNMP体系本身安全性的目标。
另外,SNMP中提供了以下4类管理操作。
◆get操作:用来提取特定的网络管理信息。
◆get-next操作:通过遍历操作来提供强大的管理信息的提取能力。
◆set操作:用来对管理信息进行控制(修改、设置)。
◆trap操作:用来报告重要的事件。
各种操作的执行如下图所示。
SNMP的4种操作
2)SNMP管理控制框架与实现
(1)SNMP管理控制框架。
SNMP定义了管理进程(Manager)和管理代理(Agent)之间的关系,这个关系被称为共同体(Community)。描述共同体的语义是非常复杂的,但其句法却很简单。位于网络管理工作站(运行管理进程)和各网络元素上,利用SNMP相互通信,并对网络进行管理的软件统称为SNMP应用实体。若干个应用实体和SNMP组合起来形成一个共同体,不同的共同体之间用名字来区分。共同体的名字必须符合Internet的层次结构命名规则,由非保留字符串组成。此外,一个SNMP应用实体可以加入多个共同体。
SNMP的应用实体对Internet管理信息库中的管理对象进行操作。一个SNMP应用实体可操作的管理对象子集称为SNMP MIB授权范围。SNMP应用实体对授权范围内管理对象的访问还有进一步的访问控制限制,比如只读、读/写等;SNMP体系结构中要求每个共同体都规定其授权范围及其对每个对象的访问方式。记录这些定义的文件被称为共同体定义文件。
SNMP的报文总是源自每个应用实体,报文中包括该应用实体所在的共同体的名字。这种报文在SNMP中称为有身份标识的报文,共同体名字是在管理进程和管理代理之间交换管理信息报文时使用的。管理信息报文中包括以下两部分内容。
◆共同体名:加上发送方的一些标识信息(附加信息),用以验证发送方确实是共同体中的成员。共同体实际上就是用来实现管理应用实体之间身份鉴别的机制。
◆数据:这是两个管理应用实体之间真正需要交换的信息。
第三版本前的SNMP只是实现了简单的身份鉴别,接收方仅凭共同体名来判定收发双方是否在同一个共同体中,而前面提到的附加信息尚未应用。接收方在验明发送报文的管理代理或管理进程的身份后要对其访问权限进行检查。访问权限检查涉及以下因素。
◆一个共同体内各成员可以对哪些对象进行读、写等管理操作,这些可读写对象称为该共同体的授权对象(在授权范围内)。
◆共同体成员对授权范围内每个对象定义了访问模式:只读或可读写。
◆规定授权范围内每个管理对象(类)可进行的操作(包括get、get-next、set和trap)。
◆管理信息库(MIB)限制对每个对象的访问方式(如MIB中可以规定哪些对象只能读而不能写等)。
管理代理通过上述预先定义的访问模式和权限,来决定共同体中其他成员要求的管理对象访问(操作)是否允许。共同体概念同样适用于转换代理(Proxy Agent),只不过转换代理中包含的对象主要是其他设备的内容。
(2)SNMP的实现方式。
为了提供遍历管理信息库的手段,SNMP在其MIB中采用了树状命名方法对每个管理对象的实例进行命名。每个对象实例的名字都由对象类名字加上一个后缀构成,对象类的名字是不会相互重复的,因而不同对象类的对象实例之间也很少有重名的危险。
在共同体的定义中一般要规定该共同体授权的管理对象的范围,相应地也就规定了哪些对象实例是该共同体的"管辖范围"。据此,共同体的定义可以想象为一个多叉树,以字典序提供了遍历所有管理对象实例的手段。有了这个手段,SNMP就可以使用get-next操作符,顺序地从一个对象找到下一个对象。get-next(object-instance)操作返回的结果是一个对象实例的标识符及其相关信息,该对象实例在上面的多叉树中紧排在指定标识符object-instance对象的后面。这种手段的优点在于:即使不知道管理对象实例的具体名字,管理系统也能逐个地找到它,并提取到它的有关信息。遍历所有管理对象的过程可以从第一个对象实例开始(这个实例一定要给出),然后逐次使用get-next,直到返回一个差错(表示不存在的管理对象实例)结束(完成遍历)。
由于信息是以表格形式(一种数据结构)存放的,在SNMP的管理概念中,把所有表格都视为子树,其中一张表格(及其名字)是相应子树的根节点,每个列是根下面的子节点,一列中的每个行则是该列节点下面的子节点,并且是子树的叶节点,如下图所示。
管理信息库中的对象标识
因此,按照前面的子树遍历思路,对表格的遍历是先访问第一列的所有元素,再访问第二列的所有元素……直到最后一个元素。若试图得到最后一个元素的"下一个"元素,则返回差错标记。
SNMP中的各种管理信息大多以表格形式存在,一个表格对应一个对象类,每个元素对应于该类的一个对象实例。那么,管理信息表对象中单个元素(对象实例)的操作可以用前面提到的get-next方法,也可以用get/set等操作。下面主要介绍表格内一行信息的整体操作。
◆增加一行:通过SNMP只用一次set操作就可在一个表格中增加一行。操作中的每个变量都对应于待增加行中的一个列元素,包括对象实例的标识符。
◆删除一行:删除一行也可以通过SNMP调用set操作,将该行中的任意一个元素(对象实例)设置成"非法"即可。
至于删除一行时,表中的一行元素是否真的在表中消失,则与每个设备(管理代理)的具体实现有关,因此管理进程必须能通过各数据字段的内容来判断数据的合法性。
3)SNMP协议
SNMP是一个异步的请求/响应协议,即SNMP的请求和响应之间没有必定的时间顺序关系,换句话说,SNMP是一个面向无连接的协议。这样,SNMP实体不需要在发出请求后立即等待响应的到来,因此SNMP响应也可能丢失或出现错误。SNMP中设计了四种基本协议的交互过程。
第一种情况是管理进程从管理代理处提取管理信息。管理进程通过SNMP和传输网络发送get-request给管理代理,请求中包括管理对象的标识符等参数;管理代理收到请求后返回相应内容的get-response,响应中包括待提取的管理信息。
第二种情况是管理进程在管理代理的可见范围内遍历一部分管理对象实例。管理进程通过SNMP和传输网络发送get-next-request给管理代理,管理代理收到后完成遍历的一次操作,用get-response将遍历结果返回给管理进程。
第三种情况是管理进程在管理代理中存储信息,即对管理代理的管理信息库(MIB)进行写操作(包括设置工作参数)。管理进程发送一个set-request给管理代理,由管理代理完成set操作,然后用set-response返回操作结果。
第四种情况则是管理代理主动向管理进程报告事件。管理代理通过SNMP和传输网络将trap发送给管理进程,这个操作没有响应。
注意:上面的各个请求都是管理进程发给管理代理的,响应则都是由管理代理发给管理进程的。只有trap是无响应的,由管理代理单向发给管理进程。另外,请求、响应和trap的传输处理都要受"共同体"定义的限制,包括访问权限。
SNMP协议是一个对称协议,没有主从关系。SNMP上的管理进程和管理代理都可以得到SNMP完全相同的服务。下面对SNMP协议的部分特点和关键内容进行介绍。
(1)管理信息报文。
在大多数SNMP操作中都使用一个相同的报文数据结构。对于前面提到的身份鉴别方法,报文中包含三种数据(信息)传递给专门的"身份鉴别实体":共同体名称、有关数据和发送方SNMP实体的传输层地址。
身份鉴别实体负责验证发送方是否是合法的对等实体,并返回两种可能的结果:一种结果是返回本次报文中的SNMP协议数据类型和发送方SNMP实体的权限标识符;另一种结果是返回例外。其中第一种结果表明发送方SNMP实体确实是本共同体的成员之一,接收方SNMP实体接下来对它进行处理。第二种结果("例外")表明发送方SNMP实体并非本共同体成员,不能接受此报文,并且接收方SNMP实体还可能根据配置产生一个"身份非法"的trap事件。
(2)协议数据单元及其管理操作。
SNMP协议实体之间的协议数据单元(PDU)只有两种不同的结构和格式,一个PDU格式在大部分操作中使用,而另一个则只在trap操作中作为trap的协议数据单元。
PDU一般包含多个代表特殊意义的字段:request-id是一个整数值,用来区分不同的PDU;error-status反映管理操作是成功还是失败;error-index表明操作中哪个变量错误;variable-bindings是一系列变量的清单,序列中每一项包含一个变量名及其变量值。
在SNMP中,接收方完成身份鉴别并得到共同体定义信息之后,SNMP实体根据PDU内容执行以下几种操作:get操作,根据变量名取出指定的对象实例;get-next操作,该操作与get操作不同,不是取变量名指定的对象实例,而是取出变量名指定的对象实例的按字典排序的下一个对象实例;set操作,对指定对象实体的值用请求中的新值替换;get-response对get/set报文做出响应并返回操作结果,收到该响应报文的操作请求方首先根据报文中的request-id在记录中查找有无这个序号的请求,如果没有则丢弃该响应,否则接收该响应,管理进程要进行响应处理。
(3)trap操作。
trap是一种捕捉事件并报告的操作,实际上几乎所有网络管理系统和管理协议都具有这种机制。trap在OSI网络管理国际标准中称为"事件和通报",一般都简称为事件报告。
为了减少管理信息的业务流量,管理代理负责对管理对象的trap进行检查,管理检查可以设置检查条件,这样,管理进程就可以在一定程度上控制trap报告过程。引入trap报告的最大好处是许多重要事件的发生得以及时让管理进程知道。因为一般只有比较关键的trap事件才确实需要报告,再加上每个trap事件都很简短,因此由于trap而引入的不确定管理信息业务量是较少的,但却能大大改善网络管理的时效性。
由于事件多种多样,各种事件的发生环境也不一样,trap操作的复杂性比前面讲的几种操作都大,SNMP的trap操作PDU中的字段类型也较多。这些trap操作PDU中的字段包括:enterprise,记录发送trap事件的管理代理的标识符;agent-addr,管理代理的网络节点地址;generic-trap,描述该trap操作报告是哪一种异常事件;specific-trap,给出各管理代理自行定义的trap事件代码;time-stam,表示trap事件发生的时刻;variable-bindings,给出一组变量,这些变量及其值给出了与trap事件有关的详细信息。
当管理代理检测到一个例外或异常事件发生时,管理代理首先要判断需要将该事件报告给哪个或哪些管理进程。对每个管理进程,管理代理要选择相应的共同体号,由SNMP协议实体按照前面的字段格式构造trap报告的PDU,再将其发送出去。
(4)SNMP PDU的传输。
SNMP的设计是独立于具体的传输网络的,也就是说,它既可以在TCP/IP的支持下操作,也可以在OSI的传输层协议支持下完成操作,甚至可以在以太网的直接支持下实现操作。其中对OSI传输层的服务没有要求,既可以是有连接的服务,也可以是无连接的服务。为了实现上述目标,Internet组织定义了若干映射标准,规定了如何将SNMP协议数据单元PDU映射到下层的无连接传输请求上去。
在所有各种映射定义中,有一点是相同的,即所有SNMP报文数据是通过一个"顺序化"过程在网络上传输的,这个顺序化过程可以将任意结构的数据编码成一个有序的字符串进行传送。对方收到这些字符串后则按照完全相同的语法将它们解码成原来的数据结构。
(5)MIB中为SNMP定义的管理对象。
在Internet的第二版管理信息库(MIB-Ⅱ)中,为SNMP应用实体定义了若干管理对象,其中包括SNMP的各种服务原语、各种收发协议数据单元、各种参数指示或统计变量等,凡SNMP中可操作的数据结构或变量都包括在内,下面将详细介绍。
在TCP/IP网络中,传输层的所有服务都包含端口号,它们可以唯一区分每个数据包包含哪些应用协议。端口系统利用这种信息来区分包中的数据,尤其是端口号使一个接收端计算机系统能够确定它所收到的IP包类型,并把它交给合适的高层软件。
端口号和设备IP地址的组合通常称作插口(socket)。任何TCP/IP实现所提供的服务都用知名的1~1023之间的端口号。这些知名端口号由Internet号分配机构(Internet Assigned Numbers Authority,IANA)来管理。例如,SMTP所用的TCP端口号是25,POP3所用的TCP端口号是110,DNS所用的UDP端口号为53,WWW服务使用的TCP端口号为80。FTP在客户与服务器的内部建立两条TCP连接,一条是控制连接,端口号为21;另一条是数据连接,端口号为20。
256~1023之间的端口号通常由Unix系统占用,以提供一些特定的UNIX服务。也就是说,提供一些只有UNIX系统才有的、其他操作系统可能不提供的服务。
在实际应用中,用户可以改变服务器上各种服务的保留端口号,但要注意,在需要服务的客户端也要改为同一端口号。
中标人的投标应当符合下列条件之一:
(1)能够最大限度地满足招标文件中规定的各项综合评价标准。
(2)能够满足招标文件的实质性要求,并且经评审的投标价格最低;但是投标价格低于成本的除外。
评标委员会经评审,认为所有投标都不符合招标文件要求的,可以否决所有投标。依法必须进行招标的项目的所有投标被否决的,招标人应当重新招标。
在确定中标人前,招标人不得与投标人就投标价格、投标方案等实质性内容进行谈判。评标委员会成员应当客观、公正地履行职务,遵守职业道德,对所提出的评审意见承担个人责任。评标委员会成员不得私下接触投标人,不得收受投标人的财物或其他好处。评标委员会成员和参与评标的有关工作人员不得透露对投标文件的评审和比较、中标候选人的推荐情况,以及与评标有关的其他情况。
中标人确定后,招标人应当向中标人发出中标通知书,并同时将中标结果通知所有未中标的投标人。中标通知书对招标人和中标人具有法律效力。中标通知书发出后,招标人改变中标结果的,或者中标人放弃中标项目的,应当依法承担法律责任。招标人和中标人应当自中标通知书发出之日起30日内,按照招标文件和中标人的投标文件订立书面合同。招标人和中标人不得再行订立背离合同实质性内容的其他协议。招标文件要求中标人提交履约保证金的,中标人应当提交。
依法必须进行招标的项目,招标人应当自确定中标人之日起15日内,向有关行政监督部门提交招标投标情况的书面报告。
51. 公司为服务器分配了IP地址段121.21.35.192/28,下面的IP地址中,不能作为Web服务器地址的是( )。
A. 121.21.35.204
B. 121.21.35.205
C. 121.21.35.206
D. 121.21.35.207
一个IP地址由网络号和主机号两部分组成,由4字节共32位的数字串组成,这4字节通常用小数点分隔。每字节可用十进制表示,如192.46.8.22。IP地址也可以用二进制和十六进制表示。
IP地址分类
IP地址分为5类,如下表所示,其中A、B、C类是常用地址。
Internet的IP地址空间容量
IP地址除了标识一台主机外,还有几种具有特殊意义的形式。
(1)本网络的本台主机。若一个IP地址由全0组成,即0.0.0.0,表示在本网络上本台主机,当一台主机在运行引导程序但又不知道其IP地址时使用该地址。
(2)本网络的某台主机。网络号各位全为"0"的IP地址,表示在这个网络中的特定主机。它用于一个主机向同网络中其他主机发送报文。
(3)网络地址。主机号各位全为"0"的IP地址标识本网络的网络地址,不分配给任何主机。
(4)直接广播地址(有时就简称为广播地址)。主机号各位全为"1"的IP地址,不分配给任何主机,它用于将一个分组发送给特定网络上的所有主机,即对全网广播。
(5)受限(本地)广播地址。受限广播地址是32位全1的IP地址(255.255.255.255)。该地址用于主机配置过程中IP数据报的目的地址,此时,主机可能还不知道它所在网络的网络掩码,甚至连它的IP地址也不知道。在任何情况下,路由器都不转发目的地址为受限的广播地址的数据报,这样的数据报仅出现在本地网络中。
(6)回送地址(Loopback Address)。A类网络地址127.X.X.X是一个保留地址,用于网络软件测试以及本地进程间的通信。
如果一个组织不需要接入到因特网上,但需要在其网络上运行TCP/IP协议,最佳选择是使用私网地址,但Internet中路由器一般不转发目标地址为私网地址的数据包。私网地址如下表所示。
私网IP地址空间
子网划分和子网掩码
由于IP地址的分配是以"网络"为单位进行的,如果一个部门拥有256个用户接入Internet,至少应该为该部门分配两个连续的C类网地址。很显然,这种分配制度导致了大量的IP地址资源的浪费。为了提高IP地址的使用效率,可采用借位的方式将一个网络划分为子网:从主机号最高位开始借位变为新的子网号,所剩余的部分仍为主机号。这使得IP地址的结构分为3部分:网络号、子网号和主机号。
引入子网划分技术后带来了一个重要问题,即主机路由和路由设备如何判断一个给定的IP地址是否已经进行了子网划分,从而能正确地从IP地址中分离出有效的网络标识。通常,将引入子网划分技术前的A、B、C类地址称为有类别(Classful)的IP地址;将引入子网划分技术后的IP地址称为无类别(Classless)的IP地址,并因此引入子网掩码来描述IP地址中关于网络标识和主机号位数的组成情况。
子网掩码(Subnetmask)通常与IP地址配对出现,其功能是告知主机或路由设备,IP地址的哪一部分代表网络号部分,哪一部分代表主机号部分。子网掩码使用与IP地址相同的编码格式,长32位,由一串1和跟随的一串0组成。子网掩码中的1对应于IP地址中的网络号(net-id)和子网号(subnet-id),而子网掩码中的0对应于IP地址中的主机号(host-id)。要得到网络或子网地址,只需将IP地址和子网掩码按位进行"与"运算即可。
子网掩码有两种表示方法。
(1)用点分十进制表示法表示,如256.256.256.0、256.256.256.240等。
(2)在IP地址后加一个"/网络号和子网号的位数"。例如,210.46.12.58/28就表示该IP地址的网络号(net-id)和子网号(subnet-id)共占用28位,主机号占用32-28=4位,如果用点分十进制表示法表示,则子网掩码为256.256.256.240,其二进制表示为
11111111 11111111 11111111 11110000
采用子网掩码是对网络编址的有益补充,但是还存在着一些缺陷,如划分的子网中较小的会浪费许多地址。为了解决这个问题,避免任何可能的地址浪费,就出现了可变长子网掩码(Variable Length Subnetwork Mask, VLSM)的编址方案。VLSM允许一个网络使用不同的网络掩码以适应不同规模的子网要求。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
Web服务器也称为WWW服务器,主要功能是提供网上信息浏览服务。
在UNIX和Linux平台下使用最广泛的HTTP服务器是W3C、NCSA和Apache服务器,而Windows平台使用IIS的Web服务器。跨平台的Web服务器有IBM WebSphere、BEA WebLogic、Tomcat等。在选择使用Web服务器应考虑的本身特性因素有性能、安全性、日志和统计、虚拟主机、代理服务器、缓冲服务和集成应用程序等。
Web服务器的主要性能指标包括最大并发连接数、响应延迟、吞吐量(每秒处理的请求数)、成功请求数、失败请求数、每秒点击次数、每秒成功点击次数、每秒失败点击次数、尝试连接数、用户连接数等。
52. 使用CIDR技术将下列4个C类地址: 202.145.27.0/24、202.145.29.0/24、202.145.31.0/24和202.145.33.0/24 汇总为一个超网地址,其地址为(52),下面 (53)不属于该地址段,汇聚之后的地址空间是原来地址空间的(54)倍。
A. 202.145.27.0/20
B. 202. 145.0.0/20
C. 202.145.0.0/18
D. 202.145.32.0/19
无分类域间路由选择(CIDR)
无分类域间路由选择(CIDR)消除了传统A类、B类和C类地址以及划分子网的概念,从而可以更加有效地分配IPv4的地址空间。CIDR使用各种长度的"网络前缀"(Network-Prefix)来代替分类地址中的网络号和子网号,而不像分类地址中只使用1字节、2字节和3字节长的网络号。CIDR不再使用"子网"概念而使用网络前缀,使IP地址从三级编址(使用子网掩码)又回到两级编址,但这是一个无分类的两级编址。CIDR使用"斜线记法",它又称为CIDR记法,即在IP地址后面加上一斜线"/",然后写上网络前缀所占的比特数(这个数值对应于三级编址中子网掩码中比特1的个数)。例如,128.14.146.158/20,表示在这32比特中,前20比特表示网络前缀,后面2比特为主机号。
CIDR将网络前缀都相同的连续的IP地址组成"CIDR地址块"。一个CIDR地址块是由地址块的起始地址(即地址块中地址块数值最小的一个)和地址块中的地址数来定义的。CIDR地址块也可用斜线记法来表示。例如,128.14.32.0/20表示的地址块共有212个地址,这个地址的起始地址是128.14.32.0。
超网
超网技术是将几个小的网络组成一个大的网络。例如,一个组织需要1000个地址,申请4个C类地址,可以把4个C类地址合并为一个超网,如下图所示。CIDR技术实现了超网。
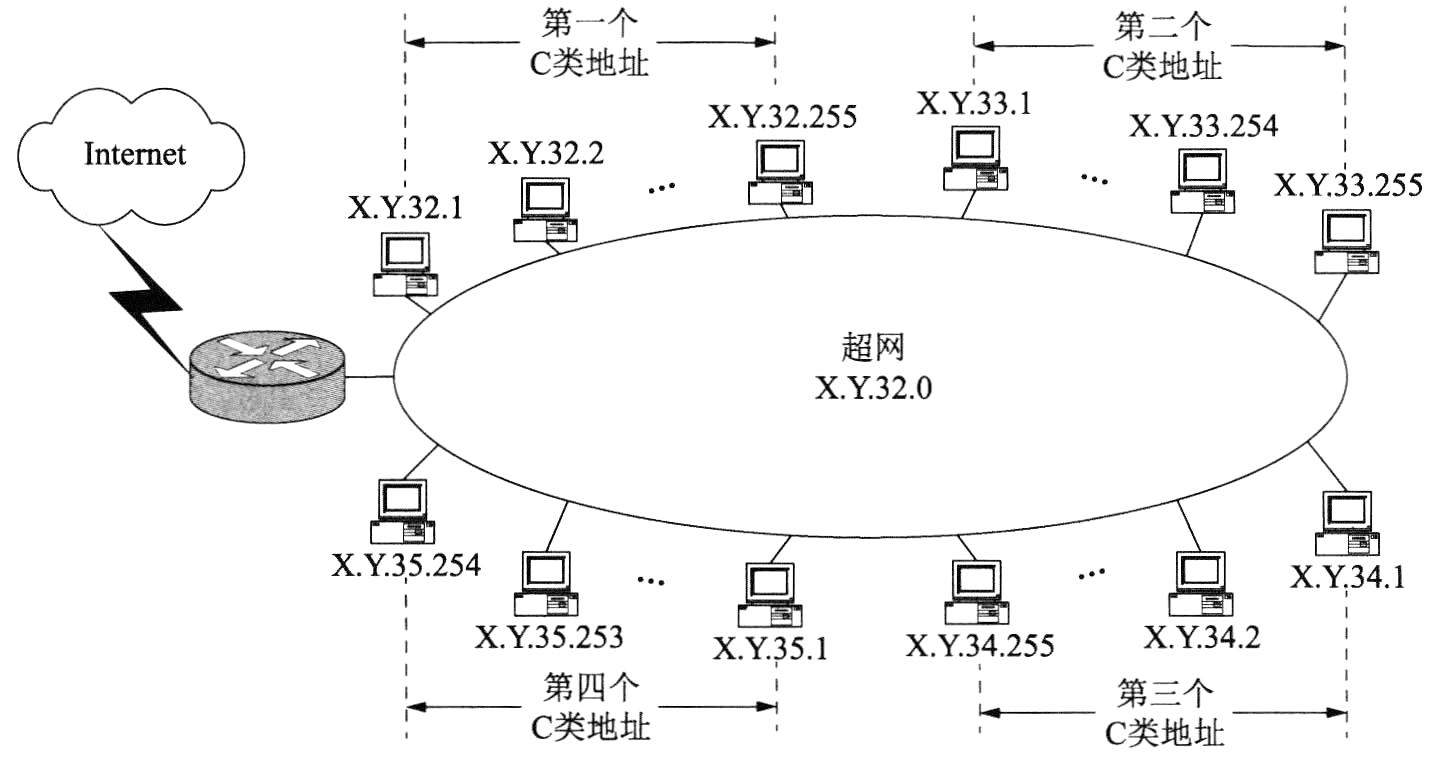
超网
路由汇总
路由汇总也称路由聚合,其实现方法与超网相同,但它的主要目的是减少路由表的网络数目,减轻路由器的负担。在大型的网络中,可能包含几十万条IP路由,有些存储容量较小的路由器无法容纳如此庞大的路由信息,使用路由汇总可以合并几个网络地址为一个代表这几个网络的聚合网络地址。
设有下面4条路由:172.18.129.0/24、172.18.130.0/24、172.18.132.0/24和172.18.133.0/24,进行路由汇聚,能覆盖这4条路由的地址是172.18.128.0/21。计算方法是找出4条路由的网络地址的共同前缀和位数,计算过程如下图所示。

路由汇聚的过程
超网技术是将几个小的网络组成一个大的网络。例如,一个组织需要1000个地址,申请4个C类地址,可以把4个C类地址合并为一个超网,如下图所示。CIDR技术实现了超网。
超网
53. 使用CIDR技术将下列4个C类地址: 202.145.27.0/24、202.145.29.0/24、202.145.31.0/24和202.145.33.0/24 汇总为一个超网地址,其地址为(52),下面 (53)不属于该地址段,汇聚之后的地址空间是原来地址空间的(54)倍。
A. 202.145.20.255
B. 202.145.35.177
C. 202.145.60.210
D. 202.145.64.1
54. 使用CIDR技术将下列4个C类地址: 202.145.27.0/24、202.145.29.0/24、202.145.31.0/24和202.145.33.0/24 汇总为一个超网地址,其地址为(52),下面 (53)不属于该地址段,汇聚之后的地址空间是原来地址空间的(54)倍。
A. 2
B. 4
C. 8
D. 16
A. 92.168.15.255/20
B. 172.16.23.255/20
C. 172.20.83.255/22
D. 202.100.10.15/28
一个IP地址由网络号和主机号两部分组成,由4字节共32位的数字串组成,这4字节通常用小数点分隔。每字节可用十进制表示,如192.46.8.22。IP地址也可以用二进制和十六进制表示。
IP地址分类
IP地址分为5类,如下表所示,其中A、B、C类是常用地址。
Internet的IP地址空间容量
IP地址除了标识一台主机外,还有几种具有特殊意义的形式。
(1)本网络的本台主机。若一个IP地址由全0组成,即0.0.0.0,表示在本网络上本台主机,当一台主机在运行引导程序但又不知道其IP地址时使用该地址。
(2)本网络的某台主机。网络号各位全为"0"的IP地址,表示在这个网络中的特定主机。它用于一个主机向同网络中其他主机发送报文。
(3)网络地址。主机号各位全为"0"的IP地址标识本网络的网络地址,不分配给任何主机。
(4)直接广播地址(有时就简称为广播地址)。主机号各位全为"1"的IP地址,不分配给任何主机,它用于将一个分组发送给特定网络上的所有主机,即对全网广播。
(5)受限(本地)广播地址。受限广播地址是32位全1的IP地址(255.255.255.255)。该地址用于主机配置过程中IP数据报的目的地址,此时,主机可能还不知道它所在网络的网络掩码,甚至连它的IP地址也不知道。在任何情况下,路由器都不转发目的地址为受限的广播地址的数据报,这样的数据报仅出现在本地网络中。
(6)回送地址(Loopback Address)。A类网络地址127.X.X.X是一个保留地址,用于网络软件测试以及本地进程间的通信。
如果一个组织不需要接入到因特网上,但需要在其网络上运行TCP/IP协议,最佳选择是使用私网地址,但Internet中路由器一般不转发目标地址为私网地址的数据包。私网地址如下表所示。
私网IP地址空间
子网划分和子网掩码
由于IP地址的分配是以"网络"为单位进行的,如果一个部门拥有256个用户接入Internet,至少应该为该部门分配两个连续的C类网地址。很显然,这种分配制度导致了大量的IP地址资源的浪费。为了提高IP地址的使用效率,可采用借位的方式将一个网络划分为子网:从主机号最高位开始借位变为新的子网号,所剩余的部分仍为主机号。这使得IP地址的结构分为3部分:网络号、子网号和主机号。
引入子网划分技术后带来了一个重要问题,即主机路由和路由设备如何判断一个给定的IP地址是否已经进行了子网划分,从而能正确地从IP地址中分离出有效的网络标识。通常,将引入子网划分技术前的A、B、C类地址称为有类别(Classful)的IP地址;将引入子网划分技术后的IP地址称为无类别(Classless)的IP地址,并因此引入子网掩码来描述IP地址中关于网络标识和主机号位数的组成情况。
子网掩码(Subnetmask)通常与IP地址配对出现,其功能是告知主机或路由设备,IP地址的哪一部分代表网络号部分,哪一部分代表主机号部分。子网掩码使用与IP地址相同的编码格式,长32位,由一串1和跟随的一串0组成。子网掩码中的1对应于IP地址中的网络号(net-id)和子网号(subnet-id),而子网掩码中的0对应于IP地址中的主机号(host-id)。要得到网络或子网地址,只需将IP地址和子网掩码按位进行"与"运算即可。
子网掩码有两种表示方法。
(1)用点分十进制表示法表示,如256.256.256.0、256.256.256.240等。
(2)在IP地址后加一个"/网络号和子网号的位数"。例如,210.46.12.58/28就表示该IP地址的网络号(net-id)和子网号(subnet-id)共占用28位,主机号占用32-28=4位,如果用点分十进制表示法表示,则子网掩码为256.256.256.240,其二进制表示为
11111111 11111111 11111111 11110000
采用子网掩码是对网络编址的有益补充,但是还存在着一些缺陷,如划分的子网中较小的会浪费许多地址。为了解决这个问题,避免任何可能的地址浪费,就出现了可变长子网掩码(Variable Length Subnetwork Mask, VLSM)的编址方案。VLSM允许一个网络使用不同的网络掩码以适应不同规模的子网要求。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
Internet上每台主机都必须有一个唯一的标识,即主机的IP地址,IP协议就是根据IP地址实现信息传递的。IP地址分为IPv4和IPv6两个版本。
(1) IPv4
IP地址由32位(即4字节)二进制数组成,将每个字节作为一段并以十进制数来表示,每段间用“.”分隔。例如,202.96.209.5就是一个合法的IP地址。
IP地址由网络标识和主机标识两部分组成。常用的IP地址有A、B、C三类,每类均规定了网络标识和主机标识在32位中所占的位数,区别如下:
.A类:一般分配给具有大量主机的网络使用,第一个字节十进制值为0~126。
.B类:通常分配给规模中等的网络使用,第一个字节十进制值为l28~191。
.C类:通常分配给小型局域网使用,第一个字节十进制值为192~223。
IP地址由世界各大地区的权威机构Inter NIC(Internet Network Information Center)管理和分配。
将主机标识域进一步划分为子网标识和子网主机标识,通过灵活定义子网标识域的位数,可以控制每个子网的规模。将一个大型网络划分为若干个既相对独立又相互联系的子网后,网络内部各子网便可独立寻址和管理,各子网间通过跨子网的路由器连接,这样也提高了网络的安全性。
利用子网掩码可以判断两台主机是否在同一子网中。子网掩码与IP地址一样也是32位二进制数,不同的是它的子网主机标识部分为全“0”。若两台主机的IP地址分别与它们的子网掩码相“与”后的结果相同,则说明这两台主机在同一子网中。
(2)IPv6
IPv6是由IETF小组设计的用来替代现行的IPv4协议的一种新的IP协议。
IPv6由128位(16字节)二进制数组成,RFC1884中规定把IPv6表示为8个16位的无符号整数,每个整数用4个十六进制位表示,中间用冒号分隔,例如:3ffe:3201:1401:1280:c8ff:fe4d:db39:1984。
IPv6具有如下优点:
.提供更大的地址空间,能够实现即插即用和灵活的重新编址。
.更简单的头信息,能够使路由器提供更有效率的路由转发。
.与移动IP和IPSec保持兼容的移动性和安全性。
.提供丰富的从IPv4到IPv6的转换和互操作方法。
56. 交换设备上配STP的基本功能包括( )。
①将设备的生成树工作模式配置成STP
②配置根桥和备份根桥设备
③配置端口的路径开销值,实现将该端口阻塞
④使能STP,实现环路消除
A. ①③④
B. ①②③
C. ①②③④
D. ①②
设图G=(V,E)是个连通图,当从图中任一个顶点出发遍历图G时,将边集E(G)分为两个集合,即A(G)和B(G)。其中A(G)是遍历时所经过的边的集合,B(G)是遍历时未经过的边的集合。G1=(V,A)是图G的子图,称子图G1为连通图G的生成树。
图的生成树不是唯一的。选择不同的存储方式,从不同的顶点出发,可以得到不同的生成树。对于非连通图而言,每个连通分量中的顶点集和遍历时走过的边集一起构成若干棵生成树,把它们称为非连通图的生成树森林。
树的存储结构及遍历操作
树是非线性结构,存储树时,须把树中结点之间存在的关系反映在树的存储结构中。树有很多存储结构,这里仅介绍最常用的两种。
1)树的标准存储结构
树的标准存储结构由结点的数据和指向子结点的指针数组组成;对于度为M的树,其指针数组中的元素个数为M。
2)树的带逆存储结构
由于树的带逆存储结构需要一个从子结点指向父结点的指针,因而该结构在标准存储结构的基础上,需要在树的结点中增加一个指向其双亲结点位置的指针。
树的遍历是树的基本操作之一,也是最重要的操作之一。树的遍历含义是指:按照某种要求依次访问树中的每个结点,每个结点均被访问一次且仅被访问一次。常用的树的遍历方法可分为前序遍历、后序遍历和中序遍历。
(1)树的前序遍历。首先访问根结点,然后从左到右前序遍历根结点的各棵子树。树的前序遍历递归算法如下:

若利用栈来记录当前未访问完的子树的根结点指针,则前序遍历的非递归算法如下:

(2)树的后序遍历。树的后序遍历的基本思想是:先依次遍历每棵子树,然后访问根结点,与后序遍历二叉树相同。树的后序遍历递归算法如下:

(3)树的中序遍历。树的中序遍历的基本思想是:先左子树,遍历根结点,然后依次遍历其他各棵子树,类似二叉树的中序遍历。树的中序遍历递归算法如下:

二叉树的递归定义
二叉树是结点的集合,这个集合或者为空,或者是由一个根和两棵互不相交的被称为左子树和右子树的二叉树组成。二叉树中的每个结点至多有两棵子树,且有左右之分,次序不能颠倒。
二叉树是一种重要的树型结构,但不是树的特例,其有5种形态,分别为:空(二叉树);只有根结点;根结点和左子树;根结点和右子树;根结点和左右子树。
二叉树与树的区别:二叉树可以为空,每个结点子树不超过2个,而树至少有一个结点且结点子树无限制。
二叉树的性质及其推广
二叉树的性质如下。
性质1:在二叉树的第i层上至多有2i-1个结点(i≥1)。
性质2:深度为k的二叉树至多有2k-1个结点(k≥1)。
性质3:对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0= n2+1。
性质4:具有n个结点的完全二叉树的深度为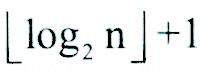
性质5:如果有n个结点的完全二叉树,对任一结点i(1
.如果i=1,则i为根,无双亲;若i>1,则i的双亲为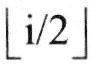
.如果2i>n,则无左孩子,否则左孩子为2i。
.如果2i+1>n,则无右孩子,否则右孩子为2i+1。
二叉树的有关性质可推广到k叉树,如:一棵含有n个结点的二叉树共含有n+1个空指针;而一棵含有n个结点的三叉树共含有2n+1个空指针。推而广之,一棵含有n个结点的k叉树共含有(k-1)n+1个空指针。
不难看出,在k叉树的第i层上至多有ki-1个结点(i≥1);深度为H的k叉树至多有(kH-1)/(k-1)个结点(H≥1)。
同理,可得含N个结点和N个叶子结点的完全三叉树的高度分别为:
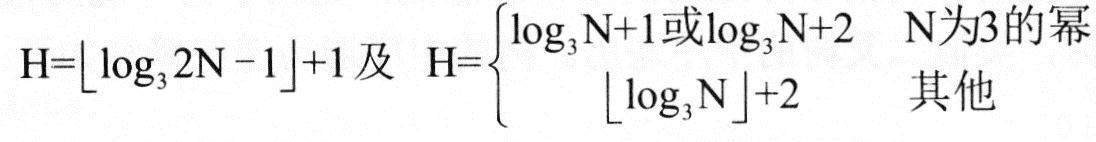
其推导过程如下。
(1)设含N个结点的完全三叉树的高度为H,则1+3+…+3H-2+1≤N≤1+3+…+3H-1,3H-1≤2N-1≤3H-2,即
(2)设含N个叶子结点的完全三叉树的高度为H,则3H-2≤N≤3H-1,即
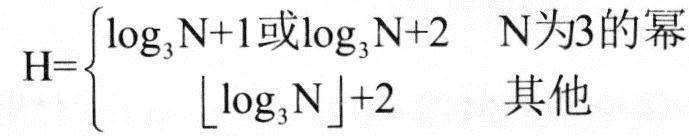
可进一步推广,含N个结点的完全k叉树的高度为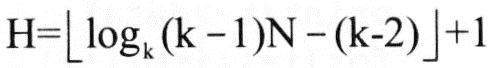
二叉树遍历的非递归
二叉树的遍历是其操作的重点,通常采用的递归算法不难实现和理解。但要实现二叉树遍历的非递归则有一定的难度,因而是理解二叉树遍历的难点。
由于很多程序员考题中都隐含地利用二叉树遍历的非递归算法,如:求二叉树中某个结点的祖先等,因而必须牢固地掌握二叉树的3种遍历的非递归算法。本质上,程序员考题中不是要考生遍历二叉树中的所有结点,而是遍历满足某种条件的结点并输出,在成功找到答案之前需要保留访问过的部分结点信息,因而须借助栈和队列等重要的数据结构。
二叉树的前序、中序和后序遍历的非递归算法分别如下所述。
二叉链表的C语言描述如下:

1)前序遍历的非递归算法

2)中序遍历的非递归调用算法

3)后序遍历的非递归调用算法

下面通过例子来说明二叉树遍历的非递归应用。
例如,在以二叉链表为存储结构的二叉树中,打印数据域值为x的结点(假定结点值不相同),并打印x的所有祖先的数据域值。
解决此问题的算法思想是:若在查找某结点的过程中,记下其祖先结点,则可以实现本问题要求。能实现这种要求的数据结构是栈,故设置一个栈用于装入x结点的所有祖先。而这种查找只有用非递归的后序遍历。
栈的元素结构说明如下:

用线索二叉树实现二叉树的非递归
以二叉链表作为存储结构时,只能找到左、右子树信息,不能直接得到结点在任一序列中的前驱和后继信息,最简单的方法是每个结点上增加两个指针域,但有点浪费。其实,n个结点的二叉链表中必定存在n+1个空链域,因此可用这些链域来存放结点的前驱和后继信息。改进后的结点结构如下。

其中,ltag=0:表示lchild域指示结点的左子树。
ltag=1:表示lchild域指示结点的前驱。
rtag=0:表示rchild域指示结点的左子树。
rtag=1:表示rchild域指示结点的前驱。
其C语言描述如下:

以这种结构构成的二叉链表叫作线索链表,其中指向结点前驱和后继的指针叫线索。加上线索的二叉树叫线索二叉树。对二叉树以某种次序遍历使其成为线索二叉树的过程叫作线索化。
对给定的线索二叉树中的某个结点p,查找结点p的后继(中序),其特点为所有叶子结点的右链直接指示了后继,所有非终端结点的后继应是其右子树中第一个中序遍历的结点。
对给定的线索二叉树中的某个结点p,查找结点p的前驱(中序),其特点为若其左标志为1,则左链为线索,指示其前驱,否则其前驱为左子树上最后遍历的一个结点。
可见,对线索二叉树进行遍历可通过线索找到相应的前驱和后继,而无须进行递归。
例如,对给定的中序线索化二叉树,查找结点*p的中序后继。在中序线索二叉树中,查找p指针的结点,其后继分为两种情况:若p->rtag=1,则p->rchild,即指向其后继结点;若p->rtag=0,则*p结点的中序后继必为其右子树中第一个中序遍历到的结点,即从*p的右子树开始,沿着左指针链向下找,直到找到一个没有左子树的结点,该结点就是*p的右子树中"最左下"的结点。其算法如下:

二叉树与树或森林转换的目的
由于树或森林可借用孩子兄弟表示法实现与二叉树的转换,所以只要研究二叉树的特性就行了,而无须对树或森林单独进行深入的讨论。
这里仅给出森林和二叉树的转换算法,树和二叉树的转换算法类似。
1)森林的二叉树表示
森林转换成二叉树的步骤如下。
设F={T1,T2,…,Tn}是森林,对应的二叉树B={root,LB,RB},则:
(1)若F为空,即n=0,则B为空。
(2)若F非空,即n>0,则二叉树的根为T1的根,其左子树是从T1中根结点的子树森林F={T11,T12,…,T1n}转换而成的二叉树;其右子树是从森林F={T2,T3,…,Tn}转换而成的二叉树。
2)二叉树转化为森林
若B是一棵二叉树,根为T,L为左子树的根,R为右子树的根,则其相应的森林F{B}由下列步骤形成。
(1)若B为空,则F为空。
(2)若B非空,则B的根结点T为{T1,T2,…,Tn}的根结点,B[L]构成了T1的不相交的子树集合{T11,T12,…,T1n};B[R]构成了森林中其他的树T2,…,Tn。
建立二叉树的若干方法
建立二叉树的方法有很多,如:按完全二叉树的形式输入字符序列,其中空格表示相应的子树为空。
近年来,在程序员考试中经常出现的二叉树建立为:已知二叉树的后序序列和中序序列或已知二叉树的前序序列和中序序列,要求考生确定一棵二叉树。
例如,一棵二叉树的中序序列和后序序列分别是DCBAEFG和DCBGFEA,请给出该二叉树的前序序列。该题可通过后序遍历确定二叉树的根结点,然后找到该数据值在前序序列中的位置,并用该位置的左部序列和后序序列中的相应序列构造左子树,用该位置的右部序列和后序序列中的相应序列构造右子树,如此不断地递归构造即可得到二叉树。建立的二叉树如下图所示。
二叉树
而且,该题还可以引申到要考生证明已知二叉树的前序序列和中序序列,可唯一确定一棵二叉树;或要求考生针对已知二叉树的前序序列和中序序列,写出建立一棵二叉树的算法等。同时,要求考生证明已知二叉树的前序序列和后序序列,不能唯一确定一棵二叉树。
当然还可以通过给定的广义表建立二叉树等。可见,建立二叉树的方法很多,只要考生掌握了二叉树递归定义的本质和输入形式就可以方便地建立二叉树。
哈夫曼树的建立和哈夫曼编码的构造
1)哈夫曼树的基本概念
.路径:由从树中一个结点到另一个结点之间的分支构成两结点之间的路径。
.路径长度:路径上的分支数目。
.树的路径长度:从树根到每一个结点的路径长度之和。
.结点的带权路径长度:从结点到根之间的路径长度与结点上权的乘积WkLk。
.树的带权路径长度:树中所有带权叶子结点的路径长度之和。
.哈夫曼树:假设有n个数值{W1,W2,…,Wn},试构造一棵有n个叶子结点的二叉树,结点带权为W1,带权路径长度WPL最小的二叉树称哈夫曼树。
对下图给定的两棵二叉树,它们的带权路径长度分别如下。
二叉树
(1)WPL=7*2+5*2+2*2+4*2=36。
(2)WPL=7*1+5*2+2*3+4*3=35。
2)哈夫曼树的构造
哈夫曼树的构造算法如下。
(1)根据给定的n个数值{W1,W2,…,Wn}构成n棵二叉树的集合F={T1,T2,…,Tn},其中每棵二叉树Ti中只有一个带权为Wi的根结点,左右子树均空。
(2)在F中选取两棵根结点的数值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的数值为其左右子树上根结点的数值之和。
(3)在F中删除这两棵树,同时将新得到的二叉树加入F中。
(4)重复步骤(2)、(3),直到F只含一棵树为止。
3)哈夫曼编码
哈夫曼编码的设计思想是:若要设计长短不等的编码,则必须是任意一个字符的编码都不是另一个字符的编码的前缀,这种编码称为前缀编码。利用二叉树来设计二进制的前缀编码,设计长度最短的二进制前缀编码,以n种字符出现的频率作为权,由此得到的二进制前缀编码为哈夫曼编码。
如何利用树型结构求解集合的幂
求集合{1,2,…,n}的幂集问题是一个经典的问题。解决这个问题的最典型做法就是递归调用,传统的做法这里不再讨论。
如何利用树状结构这个参照系来设计求集合{1,2,…,n}的幂集算法是我们讨论的重点。对于给定的集合{1,2,3,4},按幂集集合中的元素个数和字典次序建立的树如下图所示。
集合{1,2,3,4}的幂集树型示意
为了保持集合中元素的字典次序,可采用两种方法来求集合{1,2,3,4}的幂集集合:①采用前序遍历树;②按层次遍历树。特别要注意的是在设计求集合的幂集时并不建立真正的树,而是在考生的心里建立这样一个虚拟的树,并以这棵树为参照系。下面给出这两种方法的算法。
方法1:前序遍历虚拟树。

方法2:按层次遍历虚拟树。

可见,灵活地应用树状结构及其遍历操作的思路,能有效地解决实际应用问题。
二叉树的应用
二叉树运算是数据结构的重要内容。为了加深对二叉树内容的理解,这里给出一些应用实例。为方便描述,二叉树的顺序存储结构用一维数组R来表示,而二叉链表的结点存储结构定义如下:

(1)以二叉链表为存储结构,写一算法用括号形式(key,LT,RT)打印二叉树,其中key是根结点数据,LT和RT分别是括号形式的左右子树。并且要求:空树不打印任何信息,一个结点x的树打印形式是x,而不应是(x,)的形式。代码如下:

(2)建立哈夫曼树和哈夫曼编码。

(3)将已知二叉树改建为中序线序树。
将已知二叉树改建为中序线序树的算法的主要思路是:对二叉树进行中序遍历,若当前被访问结点的左子结点指针为空,则让它指向当前结点的前驱结点;若其前驱结点的右子结点指针为空,则让它指向当前结点。相应的算法如下:

在TCP/IP网络中,传输层的所有服务都包含端口号,它们可以唯一区分每个数据包包含哪些应用协议。端口系统利用这种信息来区分包中的数据,尤其是端口号使一个接收端计算机系统能够确定它所收到的IP包类型,并把它交给合适的高层软件。
端口号和设备IP地址的组合通常称作插口(socket)。任何TCP/IP实现所提供的服务都用知名的1~1023之间的端口号。这些知名端口号由Internet号分配机构(Internet Assigned Numbers Authority,IANA)来管理。例如,SMTP所用的TCP端口号是25,POP3所用的TCP端口号是110,DNS所用的UDP端口号为53,WWW服务使用的TCP端口号为80。FTP在客户与服务器的内部建立两条TCP连接,一条是控制连接,端口号为21;另一条是数据连接,端口号为20。
256~1023之间的端口号通常由Unix系统占用,以提供一些特定的UNIX服务。也就是说,提供一些只有UNIX系统才有的、其他操作系统可能不提供的服务。
在实际应用中,用户可以改变服务器上各种服务的保留端口号,但要注意,在需要服务的客户端也要改为同一端口号。
路由器在网络层对分组信息进行存储转发,实现多个网络互联。因此,路由器应具有以下基本功能。
(1)协议转换。能对网络层及其以下各层的协议进行转换。
(2)路由选择。当分组从互联的网络到达路由器时,路由器能根据分组的目的地址按某种路由策略选择最佳路由,将分组转发出去,并能随网络拓扑的变化,自动调整路由表。
(3)能支持多种协议的路由选择。路由器与协议有关,不同的路由器有不同的路由器协议,支持不同的网络层协议。如果互联的局域网采用了两种不同的协议,一种是TCP/IP协议;另一种是SPX/IPX协议(即Netware的运输层/网络层协议),由于这两种协议有许多不同之处,分布在互联网中的TCP/IP(或SPX/IPX)主机上,只能通过TCP/IP(或SPX/IPX)路由器与其他互联网中的TCP/IP(或SPX/IPX)主机通信,但不能与同一个局域网或其他局域网中的SPX/IPX(或TCP/IP)主机通信。问题产生的原因在于互联网主机之间的通信受到路由器协议的限制。因此,近年来推出了一种多协议路由器,它能支持多种协议,如IP,IPX,X.25及DEC Net协议等,能为不同类型的协议建立和维护不同的路由表。这样利用路由器不仅能连接同构型局域网,还能用它连接局域网和广域网。例如,利用一个多协议路由器来连接以太网、令牌环网、FDDI网、X.25网及DEC Net等,从而使大、中型网络的组建更加方便,并获得较高的性能价格比。但是,由于目前多协议路由器尚未标准化,不同厂家的多协议路由器不一定能协同工作,在选购时应加以注意。
(4)流量控制。路由器不仅具有缓冲区,而且还能控制收发双方数据流量,使两者更加匹配。
(5)分段和组装功能。当多个网络通过路由器互联时,各网络传输的数据分组的大小可能不相同,这就需要路由器对分组进行分段或组装。即路由器能将接收的大分组分段并封装成小分组后转发,或将接收的小分组组装成大分组后转发。如果路由器没有分段组装功能,那么整个互联网就只能按照所允许的某个最短分组进行传输,大大降低了网络的效能。
(6)网络管理功能。路由器是连接多种网络的汇集点,网间信息都要通过它,在这里对网络中的信息流、设备进行监视和管理是比较方便的。因此,高档路由器都配置了网络管理功能,以便提高网络的运行效率、可靠性和可维护性。
57. OSPF协议相对于RIP的优势在于( )。
①没有跳数的限制
②支持可变长子网掩码(VLSM)
③支持网络规模大
④收敛速度快
A. ①③④
B. ①②③
C. ①②③④
D. ①②
编址的另一个特殊形式是子网掩码。子网掩码的目的有两个:一是显示使用的编址类别,二是将网络分成子网来控制网络流量。在第一种情况下,子网掩码可使得应用程序能够确定IP地址的哪一部分是表示网络ID,哪一部分是表示主机ID。例如,一个A类地址网络的默认子网掩码是第一个8位字节均为二进制的1,其他字节均为二进制的0:11111111.00000000.00000000.00000000(255.0.0.0)。
如果要将网络分成子网,子网掩码应包含子网ID,这个子网ID是由网络管理员决定的,存在于网络ID和主机ID之内。例如,可以指定B类地址的整个第三个8位字节来说明子网ID,如11111111.11111111.11111111.00000000(255.255.255.0);另一种选择是只指定第三个8位字节的前5位作为子网ID,后3位和余下的8位字节用于指定主机ID,如11111111.11111111.11111000.00000000(255.255.248.0)。
使用子网掩码将网络分成一系列小型网络,可以使得第三层设备能够有效地忽略传统的地址分类命名,因此在通过多个子网和额外的网络地址将网络进行分段时就有了更多的选项,克服了四个8位字节长度的限制。同样是利用子网掩码工具,1992年出现了一种新的忽略地址分类命名的方法,它是无分类域间路由(Classless Inter-Domain Routing, CIDR)编址方法。
引入CIDR后,意味着网络"类"(比如A类地址、B类地址等)的概念已经被取消,取而代之的是"网络前缀"的概念。CIDR的基本思想是取消地址的分类结构,允许以可变长分界的方式分配网络数。它支持路由聚合,可限制Internet主干路由器中必要路由信息的增长。
CIDR编址的方法是在点分隔的十进制符号之后画一个斜杠"/",并在斜杠后加上子网掩码"1"的总个数。比如202.102.0.0/23。我们知道,202.102.0.0是C类网络地址(默认是24位子网掩码);而采用CIDR编址后,202.102.0.0/23(23位子网掩码)既不属于C类网络地址,也不属于B类网络地址。但是,网络地址202.102.0.0/23提供了更多的信息节点(510个),而默认的C类网络地址202.102.0.0只提供了254个信息节点。
可见,CIDR编址方法为中型的网络提供了更多的IP地址选项。例如,对于需要262 144个节点的网络,其CIDR网络编址方案可以是165.100.0.0/14。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
为了响应不断增长的建立越来越大的基于IP的网络需要,IETF成立了一个工作组专门开发一种开放的、基于大型复杂IP网络的链路状态路由选择协议。由于它依据一些厂商专用的最短路径优先(SPF)路由选择协议开发而成,而且是开放性的,因此称为开放式最短路径优先(Open Shortest Path First,OSPF)协议,和其他SPF一样,它采用的也是Dijkstra算法。OSPF协议现在已成为最重要的路由选择协议之一,主要用于同一个自治系统。
OSPF协议采用了“区域”的设计,提高了网络可扩展性,并且加快了网络会聚时间。也就是将网络划分成为许多较小的区域,每个区域定义一个独立的区域号并将此信息配置给网络中的每个路由器。从理论上说,通常不应该采用实际地域来划分区域,而是应该本着使不同区域间的通信量最小的原则进行合理分配。
OSPF是一种典型的链路状态路由协议。采用OSPF的路由器彼此交换并保存整个网络的链路信息,从而掌握全网的拓扑结构,独立计算路由。因为RIP路由协议不能服务于大型网络,所以IETF的IGP工作组特别开发链路状态协议——OSPF。目前广为使用的是OSPF第二版,最新标准为RFC2328。
OSPF路由协议概述
OSPF作为一种内部网关协议,用于在同一个自治域(AS)中的路由器之间发布路由信息。区别于距离矢量协议(RIP),OSPF具有支持大型网络、路由收敛快、占用网络资源少等优点,在目前应用的路由协议中占有相当重要的地位。
基本概念和术语
下面介绍OSPF的基本概念和术语:
(1)链路状态。
OSPF路由器收集其所在网络区域上各路由器的连接状态信息,即链路状态信息(Link-State),生成链路状态数据库(Link-State Database)。路由器掌握了该区域上所有路由器的链路状态信息,也就等于了解了整个网络的拓扑状况。OSPF路由器利用“最短路径优先算法(Shortest Path First,SPF)”,独立地计算出到达任意目的地的路由。
(2)区域。
OSPF协议引入“分层路由”的概念,将网络分割成一个“主干”连接的一组相互独立的部分,这些相互独立的部分被称为“区域”(Area),“主干”的部分称为“主干区域”。每个区域就如同一个独立的网络,该区域的OSPF路由器只保存该区域的链路状态。每个路由器的链路状态数据库都可以保持合理的大小,路由计算的时间、报文数量都不会过大。
(3)OSPF网络类型。
根据路由器所连接的物理网络不同,OSPF将网络划分为4种类型:广播多路访问型(Broadcast MultiAccess)、非广播多路访问型(None Broadcast MultiAccess,NBMA)、点到点型(Point-to-Point)、点到多点型(Point-to-MultiPoint)。
广播多路访问型网络,如Ethernet、Token Ring、FDDI。NBMA型网络,如Frame Relay、X.25、SMDS。Point-to-Point型网络,如PPP、HDLC。
(4)指派路由器(DR)和备份指派路由器(BDR)。
在多路访问网络上可能存在多个路由器,为了避免路由器之间建立完全相邻关系而引起的大量开销,OSPF要求在区域中选举一个DR。每个路由器都与之建立完全相邻关系。DR负责收集所有的链路状态信息,并发布给其他路由器。选举DR的同时也选举一个BDR,在DR失效时,BDR担负起DR的职责。
当路由器开启一个端口的OSPF路由时,将会从这个端口发出一个Hello报文,以后它也将以一定的间隔周期性地发送Hello报文。OSPF路由器用Hello报文来初始化新的相邻关系以及确认相邻的路由器邻居之间的通信状态。
对广播型网络和非广播型多路访问网络,路由器使用Hello协议选举出一个DR。在广播型网络里,Hello报文使用多播地址224.0.0.5周期性广播,并通过这个过程自动发现路由器邻居。在NBMA网络中,DR负责向其他路由器逐一发送Hello报文。
操作
OSPF协议操作总共经历了建立邻接关系、选举DR/BDR、发现路由器等步骤。
(1)建立路由器的邻接关系。
所谓“邻接关系”(Adjacency)是指OSPF路由器以交换路由信息为目的,在所选择的相邻路由器之间建立的一种关系。路由器首先发送拥有自身ID信息(Loopback端口或最大的IP地址)的Hello报文。与之相邻的路由器如果收到这个Hello报文,就将这个报文内的ID信息加入到自己的Hello报文内。
如果路由器的某端口收到从其他路由器发送的含有自身ID信息的Hello报文,则它根据该端口所在网络类型确定是否可以建立邻接关系。
在点对点网络中,路由器将直接和对端路由器建立邻接关系,并且该路由器将直接进入到步骤(3)操作:发现其他路由器。若为MultiAccess网络,该路由器将进入选举步骤。
(2)选举DR/BDR。
不同类型的网络选举DR和BDR的方式不同。
MultiAccess网络支持多个路由器,在这种状况下,OSPF需要建立起作为链路状态和LSA更新的中心节点。选举利用Hello报文内的ID和优先权(Priority)字段值来确定。优先权字段值大小为0~255,优先权值最高的路由器成为DR。如果优先权值大小一样,则ID值最高的路由器选举为DR,优先权值次高的路由器选举为BDR。优先权值和ID值都可以直接设置。
(3)发现路由器。
在这个步骤中,路由器与路由器之间首先利用Hello报文的ID信息确认主从关系,然后主从路由器相互交换部分链路状态信息。每个路由器对信息进行分析比较,如果收到的信息有新的内容,路由器将要求对方发送完整的链路状态信息。这个状态完成后,路由器之间建立完全相邻(Full Adjacency)关系,同时邻接路由器拥有自己独立的、完整的链路状态数据库。
在MultiAccess网络内,DR与BDR互换信息,并同时与本子网内其他路由器交换链路状态信息。
在Point-to-Point或Point-to-MultiPoint网络中,相邻路由器之间互换链路状态信息。
(4)选择适当的路由器。
当一个路由器拥有完整独立的链路状态数据库后,它将采用SPF算法计算并创建路由表。OSPF路由器依据链路状态数据库的内容,独立地用SPF算法计算到每一个目的网络的路径,并将路径存入路由表中。
OSPF利用量度(Cost)计算目的路径,Cost最小者即为最短路径。在配置OSPF路由器时可根据实际情况,如链路带宽、时延或经济上的费用设置链路Cost大小。Cost越小,则该链路被选为路由的可能性越大。
(5)维护路由信息。
当链路状态发生变化时,OSPF通过Flooding过程通告网络上其他路由器。OSPF路由器接收到包含新信息的链路状态更新报文,将更新自己的链路状态数据库,然后用SPF算法重新计算路由表。在重新计算过程中,路由器继续使用旧路由表,直到SPF完成新的路由表计算。新的链路状态信息将发送给其他路由器。值得注意的是,即使链路状态没有发生改变,OSPF路由信息也会自动更新,默认时间为30分钟。
OSPF路由协议的基本特征
前文已经说明OSPF路由协议是一种链路状态的路由协议,为了更好地说明OSPF路由协议的基本特征,将OSPF路由协议与距离矢量路由协议之一的RIP比较如下:
RIP中用于表示目的网络远近的唯一参数为跳(Hop),即到达目的网络所要经过的路由器个数。在RIP路由协议中,该参数被限制最大为15,即RIP路由信息最多能传递至第16个路由器;对于OSPF路由协议,路由表中表示目的网络的参数为Cost,该参数为一虚拟值,与网络中链路的带宽等相关,即OSPF路由信息不受物理跳数的限制,因此OSPF比较适合于大型网络中。
RIPv1路由协议不支持变长子网屏蔽码(VLSM),被认为是RIP路由协议不适用于大型网络的又一个重要原因。采用变长子网屏蔽码可以在最大限度上节约IP地址。OSPF路由协议对VLSM有良好的支持性。
RIP路由协议路由收敛较慢。RIP路由协议周期性地将整个路由表作为路由信息广播至网络中,该广播周期为30s。在一个较为大型的网络中,RIP会产生很大的广播信息,占用较多的网络带宽资源。由于R1P协议30s的广播周期,影响了RIP路由协议的收敛,甚至出现不收敛的现象。OSPF是一种链路状态的路由协议,当网络比较稳定时,网络中的路由信息是比较少的,并且其广播也不是周期性的,因此OSPF路由协议即使是在大型网络中也能够较快地收敛。
在RIP中,网络是一个平面的概念,并无区域及边界等的定义。随着无级路由CIDR概念的出现,RIP协议就明显落伍了。在OSPF路由协议中,一个网络,或者说是一个路由域可以划分为很多个区域,每一个区域通过OSPF边界路由器相连,区域间可以通过路由汇聚来减少路由信息,减小路由表,提高路由器的运算速度。
OSPF路由协议支持路由验证,只有互相通过路由验证的路由器之间才能交换路由信息。而且OSPF可以对不同的区域定义不同的验证方式,提高网络的安全性。
建立OSPF邻接关系过程
OSPF路由协议通过建立交互关系来交换路由信息,但并不是所有相邻的路由器都会建立OSPF交互关系。下面简要介绍OSPF建立adjacency的过程。
OSPF协议是通过Hello协议数据包来建立及维护相邻关系的,同时也用其来保证相邻路由器之间的双向通信。OSPF路由器会周期性地发送Hello数据包,当这个路由器看到自身被列于其他路由器的Hello数据包里时,这两个路由器之间会建立起双向通信。在多接入的环境中,Hello数据包还用于发现指定路由器(DR),通过DR来控制与哪些路由器建立交互关系。
两个OSPF路由器建立双向通信之后的第二个步骤是进行数据库的同步,数据库同步是所有链路状态路由协议的最大的共性。在OSPF路由协议中,数据库同步关系仅仅在建立交互关系的路由器之间保持。
OSPF的数据库同步是通过OSPF数据库描述数据包(Database Description Packets)来进行的。OSPF路由器周期性地产生数据库描述数据包,该数据包是有序的,即附带有序列号,并将这些数据包对相邻路由器广播。相邻路由器可以根据数据库描述数据包的序列号与自身数据库的数据作比较,若发现接收到的数据比数据库内的数据序列号大,则相邻路由器会针对序列号较大的数据发出请求,并用请求得到的数据来更新其链路状态数据库。
将OSPF相邻路由器从发送Hello数据包,建立数据库同步至建立完全的OSPF交互关系的过程分成几个不同的状态,如下所述。
(1)Down:这是OSPF建立交互关系的初始化状态,表示在一定时间之内没有接收到从某一相邻路由器发送来的信息。在非广播性的网络环境内,OSPF路由器还可能对处于Down状态的路由器发送Hello数据包。
(2)Attempt:该状态仅在NBMA环境,如帧中继、X.25或ATM环境中有效,表示在一定时间内没有接收到某一相邻路由器的信息,但是OSPF路由器仍必须通过以一个较低的频率向该相邻路由器发送Hello数据包来保持联系。
(3)Init:在该状态时,OSPF路由器已经接收到相邻路由器发送来的Hello数据包,但自身的IP地址并没有出现在该Hello数据包内,也就是说,双方的双向通信还没有建立起来。
(4)2-Way:这个状态可以说是建立交互方式真正的开始步骤。在这个状态,路由器看到自身已经处于相邻路由器的Hello数据包内,双向通信已经建立。指定路由器及备份指定路由器的选择正是在这个状态完成的。在这个状态,OSPF路由器还可以根据其中的一个路由器是否指定路由器或根据链路是否点对点或虚拟链路来决定是否建立交互关系。
(5)Exstart:这个状态是建立交互状态的第一个步骤。在这个状态,路由器要决定用于数据交换的初始的数据库描述数据包的序列号,以保证路由器得到的永远是最新的链路状态信息。同时,在这个状态路由器还必须决定路由器之间的主备关系,处于主控地位的路由器会向处于备份地位的路由器请求链路状态信息。
(6)Exchange:在这个状态,路由器向相邻的OSPF路由器发送数据库描述数据包来交换链路状态信息,每一个数据包都有一个数据包序列号。在这个状态,路由器还有可能向相邻路由器发送链路状态请求数据包来请求其相应数据。从这个状态开始,可以说OSPF处于Flood状态。
(7)Loading:在Loading状态,OSPF路由器会就其发现的相邻路由器的新的链路状态数据及自身的已经过期的数据向相邻路由器提出请求,并等待相邻路由器的回答。
(8)Full:这是两个OSPF路由器建立交互关系的最后一个状态,这时建立起交互关系的路由器之间已经完成了数据库同步的工作,它们的链路状态数据库已经一致。
OSPF的DR及BDR
在DR和BDR出现之前,每一台路由器和他的所有邻居成为完全网状的OSPF邻接关系,这样5台路由器之间将需要形成10个邻接关系,同时将产生25条LSA。而且在多址网络中,还存在自己发出的LSA从邻居的邻居发回来,导致网络上产生很多LSA的拷贝。所以基于这种考虑,产生了DR和BDR。
完成的工作内容
DR将完成如下工作:
(1)描述这个多址网络和该网络上剩下的其他相关路由器。
(2)管理这个多址网络上的flooding过程。
(3)同时为了冗余性,还会选取一个BDR,作为双备份之用。
选取规则
DR BDR选取规则:DR BDR选取是以接口状态机的方式触发的。
(1)路由器的每个多路访问(Multi-access)接口都有个路由器优先级(Router Priority),8位长的一个整数,范围是0~255,Cisco路由器默认的优先级是1,优先级为0的话将不能选举为DR/BDR。优先级可以通过命令ip ospf priority进行修改。
(2)Hello包里包含了优先级的字段,还包括了可能成为DR/BDR的相关接口的IP地址。
(3)当接口在多路访问网络上初次启动的时候,它把DR/BDR地址设置为0.0.0.0,同时设置等待计时器(Wait Timer)的值等于路由器无效间隔(Router Dead Interval)。
选取过程
DR BDR选取过程:
(1)路由器X在和邻居建立双向(2-Way)通信之后,检查邻居的Hello包中Priority,DR和BDR字段,列出所有可以参与DR/BDR选举的邻居。
(2)如果有一台或多台这样的路由器宣告自己为BDR(也就是说,在其Hello包中将自己列为BDR,而不是DR),选择其中拥有最高路由器优先级的成为BDR;如果相同,选择拥有最大路由器标识的。如果没有路由器宣告自己为BDR,选择列表中路由器拥有最高优先级的成为BDR(同样排除宣告自己为DR的路由器),如果相同,再根据路由器标识。
(3)按如下计算网络上的DR。如果有一台或多台路由器宣告自己为DR(也就是说,在其Hello包中将自己列为DR),选择其中拥有最高路由器优先级的成为DR;如果相同,选择拥有最大路由器标识的。如果没有路由器宣告自己为DR,将新选举出的BDR设定为DR。
(4)如果路由器X新近成为DR或BDR,或者不再成为DR或BDR,重复步骤(2)和(3),然后结束选举。这样做是为了确保路由器不会同时宣告自己为DR和BDR。
(5)要注意的是,当网络中已经选举了DR/BDR后,又出现了1台新的优先级更高的路由器,DR/BDR是不会重新选举的。
(6)DR/BDR选举完成后,DRother只和DR/BDR形成邻接关系。所有的路由器将组播Hello包到AllSPFRouters地址224.0.0.5以便它们能跟踪其他邻居的信息,即DR将泛洪update packet到224.0.0.5;DRother只组播update packet到AllDRouter地址224.0.0.6,只有DR/BDR监听这个地址。
筛选过程
简单地说,DR的筛选过程如下:
(1)优先级为0的不参与选举。
(2)优先级高的路由器为DR。
(3)优先级相同时,以router ID大为DR;router ID以回环接口中最大IP为准;若无回环接口,以真实接口最大IP为准。
(4)默认条件下,优先级为1。
OSPF路由器类型
OSPF路由器类型如下图所示。

OSPF路由器类型
区域内路由器(Internal Routers)。
该类路由器的所有接口都属于同一个OSPF区域。
区域边界路由器ABR(Area Border Routers)。
该类路由器可以同时属于两个以上的区域,但其中一个必须是骨干区域。ABR用来连接骨干区域和非骨干区域,它与骨干区域之间既可以是物理连接,也可以是逻辑上的连接。
骨干路由器(Backbone Routers)。
该类路由器至少有一个接口属于骨干区域。因此,所有的ABR和位于Area0的内部路由器都是骨干路由器。
自治系统边界路由器(AS Boundary Routers,ASBR)。
与其他AS交换路由信息的路由器称为ASBR。ASBR并不一定位于AS的边界,它可能是区域内路由器,也可能是ABR。只要一台OSPF路由器引入了外部路由的信息,它就成为ASBR。
OSPF LSA类型
随着OSPF路由器种类概念的引入,OSPF路由协议又对其链路状态广播数据包(LSA)做出了分类。OSPF将链路状态广播数据包主要分成以下6类,如下表所示。
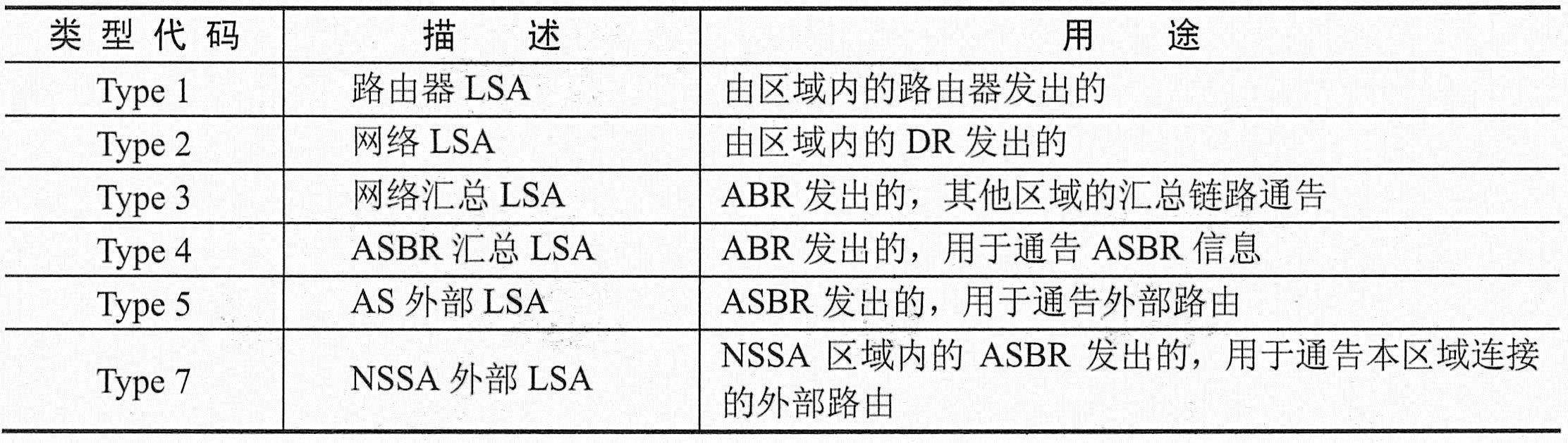
LSA类型
(1)1类LSA(路由器LSA):每台路由器都通告1类LSA,描述了与路由器直连的所有链路(接口)状态,只能在本区域内扩散。
(2)2类LSA(网络LSA):只有DR才有资格产生,只能在本区域内扩散,描述了多路访问网络的所有路由器(Router ID)和链路的子网掩码。
(3)3类LSA(汇总LSA):只有ABR可以产生,能在整个OSPF自治系统扩散,描述了目的网路的路由(还可能包含汇总路由)。
(4)4类LSA(汇总LSA):仅当区域中有ASBR时,ABR才会产生,该LSA标识了ASBR,提供一条前往该ASBR的路由。
(5)5类LSA(外部LSA):只能由ASBR产生,描述了前往OSPF自治系统外的网络的路由,被扩散到整个AS(除各种末节区域外)。
(6)7类LSA(用于NSSA的LSA):只能由NSSA ASBR产生,只能出现在NSSA,而NSSA ABR将其转换为5类LSA并扩散到整个OSPF自治系统。
OSPF区域类型
根据区域所接收的LSA类型不同,可将区域划分为以下几种类型:
(1)标准区域:默认的区域类型,它接收链路更新、汇总路由和外部路由,如下图所示。
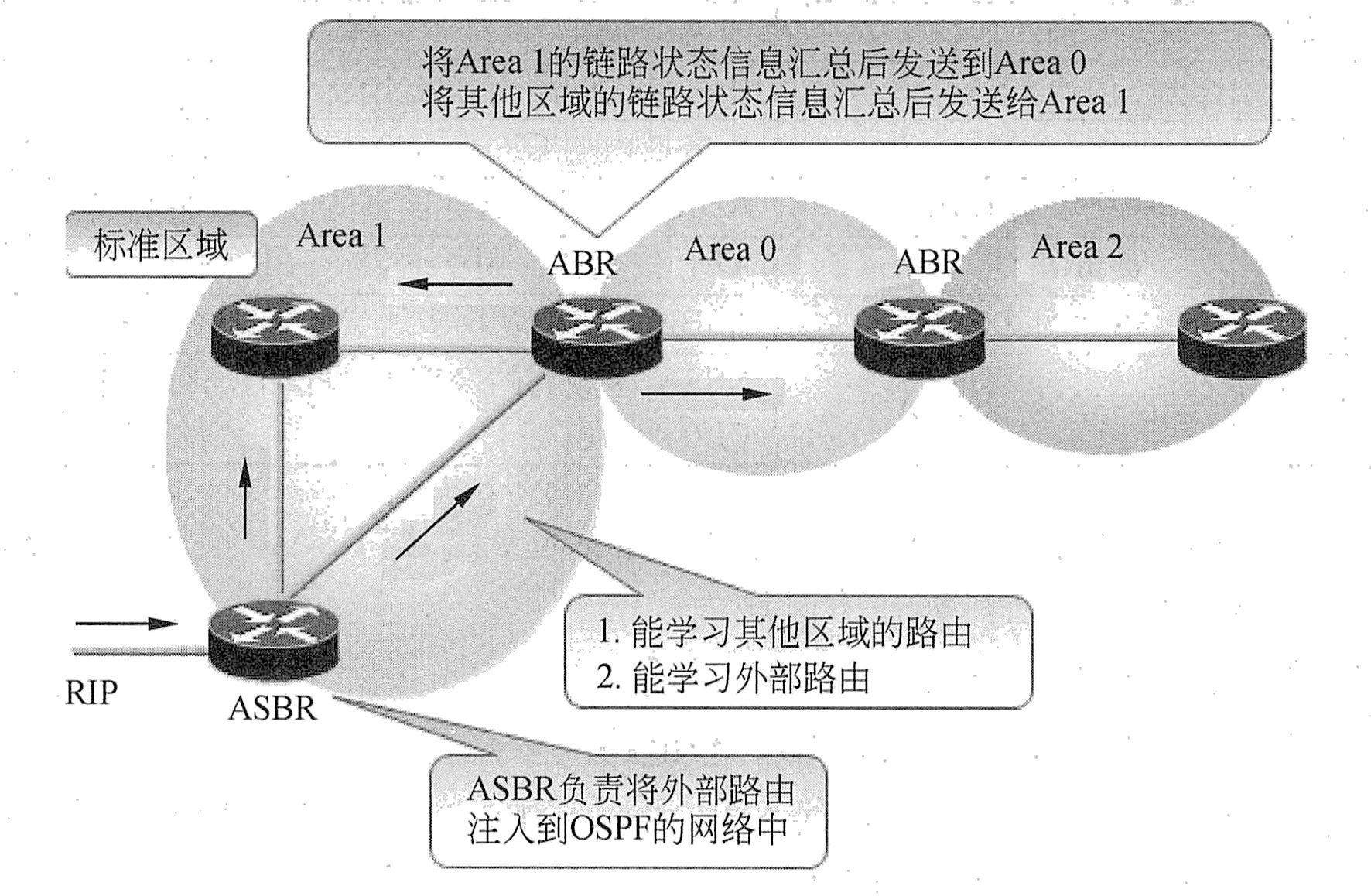
标准区域示例
(2)骨干区域:骨干区域为Area 0,其他区域都与之相连以交换路由信息,该区域具有标准区域的所有特征。
(3)末节区域:不接收4类汇总LSA和5类外部LSA,但接收3类汇总LSA,使用默认路由到AS外部网络(自动生成),该区域不包含ASBR(除非ABR也是ASBR)。
(4)绝对末节区域:这个是Cisco专用。它不接收3类、4类汇总LSA和5类外部LSA,使用默认路由到AS外部网络(自动生成),该区域不包含ASBR(除非ABR也是ASBR)。
(5)NSSA:不接收4类汇总LSA和5类外部LSA,但接收3类汇总LSA且可以有ASBR,使用默认路由前往外部网络,默认路由是由与之相连的ABR生成的,但默认情况下不会生成,要让ABR生成默认路由,可使用命令area area-id nssa default-information-originate。
(6)绝对末节NSSA:这个是Cisco公司专用。它不接收3类、4类汇总LSA和5类外部LSA且可以有ASBR,使用默认路由到AS外部网络,默认路由是自动生成的。
每一种区域中允许泛洪的LSA总结如下表所示。

区域允许LSA总结
注:*为ABR路由器使用一个类型3的LSA通告默认路由。
虚链路
在OSPF路由协议中存在一个骨干区域(Backbone),该区域包括属于这个区域的网络及相应的路由器,骨干区域必须是连续的,同时也要求其余区域必须与骨干区域直接相连。骨干区域一般为区域0,其主要工作是在其余区域间传递路由信息。所有的区域,包括骨干区域之间的网络结构情况是互不可见的,当一个区域的路由信息对外广播时,其路由信息是先传递至区域0(骨干区域),再由区域0将该路由信息向其余区域作广播。

骨干区域不连续虚链路
在实际网络中,可能会存在骨干区域不连续或某一个区域与骨干区域物理不相连的情况,在这两种情况下,系统管理员可以通过设置虚拟链路的方法来解决,如上图和下图所示。
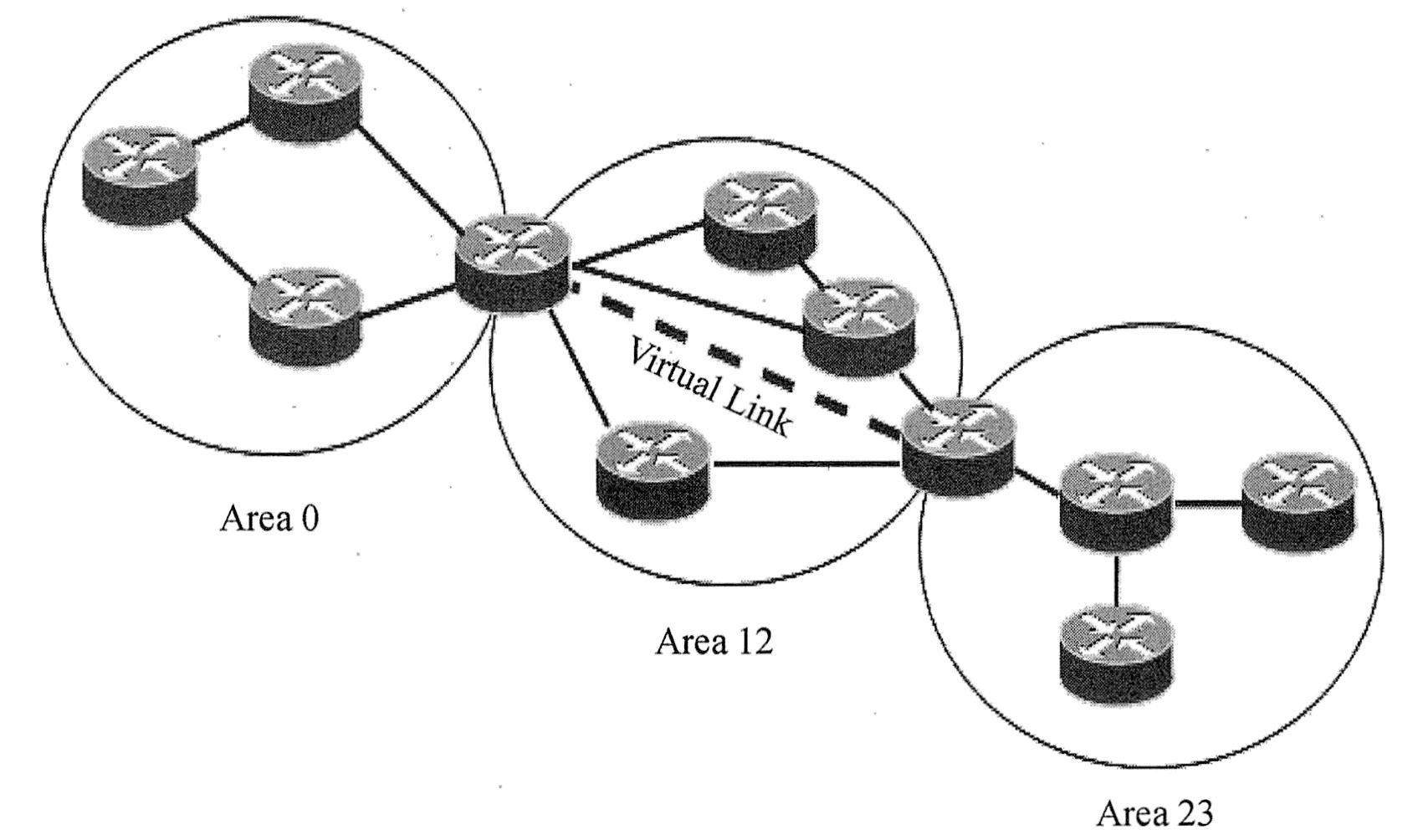
与骨干区域物理不相连虚链路
虚拟链路设置在两个路由器之间,这两个路由器都有一个端口与同一个非骨干区域相连。虚拟链路被认为是属于骨干区域的,在OSPF路由协议看来,虚拟链路两端的两个路由器被一个点对点的链路连在一起。在OSPF路由协议中,通过虚拟链路的路由信息是作为域内路由来看待的。
OSPF配置命令汇总
OSPF常用配置命令如下表所示。
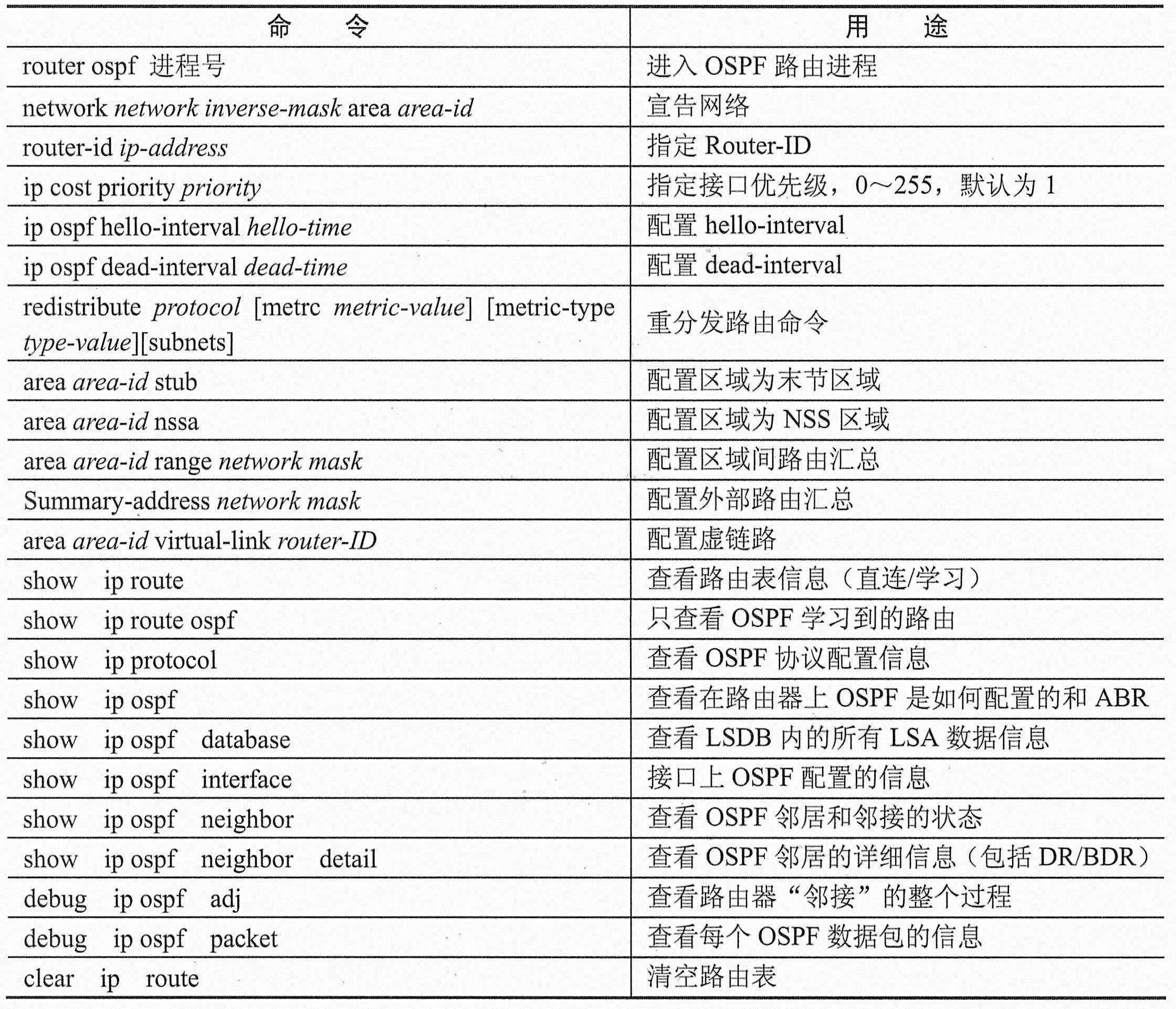
OSPF配置命令汇总
OSPF配置实例
下面,以如下图所示的一个网络为例说明OSPF路由选择协议的配置方法,该网络中有0和1两个区域,其中R1的S1端口、R2的S0端口属于区域0;而R3、R1的S0端口、R2的S1端口则属于区域1。

OSPF配置拓扑图
下面列出三个路由器配置OSPF的指令:

从上面的配置实例中可以知道,在配置OSPF时可以将子网进行合并,以减少条目,提高效率。例如,R3的邻接子网有192.168.1.0、192.168.2.0、192.168.3.0三个,因此可以合并为192.0.0.0/255.0.0.0;当然合并为192.168.0.0/255.255.0.0也是可行的。
VLSM是一种产生不同大小子网的网络分配机制(在RFC1878中有详细说明)。VLSM用直观的方法在IP地址后面加上“/网络及子网编码位数”来表示。例如,192.168.123.0/26表示前26位表示网络号和子网号,即子网掩码为26位长,主机号6位长。利用VLSM技术,可以多次划分子网,即分完子网后,继续根据需要划分子网。
例如,软考在线IT教育研发中心有4个部门,需建立4个子网,其中部门1有50台主机,部门2有25台主机,部门3和部门4则只有10台主机,有一内部C类地址192.168.1.0。下面是采用VLSM划分的过程:
(1)首先,找到最大的网络:部门1,需要50台主机。25<50<26,因此需要6位主机号,剩下的26位则是网络号、子网号。而最后一个8位段还剩下2位,可以表示00、01、10、11四个子网,但00和11有特殊应用,因此只有01、10两个子网,得到192.168.1.64/26、192.168.1.128/26两个子网。
(2)假设将192.168.1.64/26分给部门1,则现在就需要处理部门2~部门4。这三个部分中部门2的网络最大,需要25台主机。24<25<25,因此,需要4位主机号,可以分成192.168.1.128/27和192.168.1.160/27两个子网。
(3)然后,按这个的思路划分下去,可以得到下表。

分配后结果
注:网络范围中的前者是网络地址,后者是广播地址。
58. OSPF协议中DR的作用范围是( )。
A. 一个area
B. 一个网段
C. 一台路由器
D. 运行OSPF协议的网络
为了响应不断增长的建立越来越大的基于IP的网络需要,IETF成立了一个工作组专门开发一种开放的、基于大型复杂IP网络的链路状态路由选择协议。由于它依据一些厂商专用的最短路径优先(SPF)路由选择协议开发而成,而且是开放性的,因此称为开放式最短路径优先(Open Shortest Path First,OSPF)协议,和其他SPF一样,它采用的也是Dijkstra算法。OSPF协议现在已成为最重要的路由选择协议之一,主要用于同一个自治系统。
OSPF协议采用了“区域”的设计,提高了网络可扩展性,并且加快了网络会聚时间。也就是将网络划分成为许多较小的区域,每个区域定义一个独立的区域号并将此信息配置给网络中的每个路由器。从理论上说,通常不应该采用实际地域来划分区域,而是应该本着使不同区域间的通信量最小的原则进行合理分配。
OSPF是一种典型的链路状态路由协议。采用OSPF的路由器彼此交换并保存整个网络的链路信息,从而掌握全网的拓扑结构,独立计算路由。因为RIP路由协议不能服务于大型网络,所以IETF的IGP工作组特别开发链路状态协议——OSPF。目前广为使用的是OSPF第二版,最新标准为RFC2328。
OSPF路由协议概述
OSPF作为一种内部网关协议,用于在同一个自治域(AS)中的路由器之间发布路由信息。区别于距离矢量协议(RIP),OSPF具有支持大型网络、路由收敛快、占用网络资源少等优点,在目前应用的路由协议中占有相当重要的地位。
基本概念和术语
下面介绍OSPF的基本概念和术语:
(1)链路状态。
OSPF路由器收集其所在网络区域上各路由器的连接状态信息,即链路状态信息(Link-State),生成链路状态数据库(Link-State Database)。路由器掌握了该区域上所有路由器的链路状态信息,也就等于了解了整个网络的拓扑状况。OSPF路由器利用“最短路径优先算法(Shortest Path First,SPF)”,独立地计算出到达任意目的地的路由。
(2)区域。
OSPF协议引入“分层路由”的概念,将网络分割成一个“主干”连接的一组相互独立的部分,这些相互独立的部分被称为“区域”(Area),“主干”的部分称为“主干区域”。每个区域就如同一个独立的网络,该区域的OSPF路由器只保存该区域的链路状态。每个路由器的链路状态数据库都可以保持合理的大小,路由计算的时间、报文数量都不会过大。
(3)OSPF网络类型。
根据路由器所连接的物理网络不同,OSPF将网络划分为4种类型:广播多路访问型(Broadcast MultiAccess)、非广播多路访问型(None Broadcast MultiAccess,NBMA)、点到点型(Point-to-Point)、点到多点型(Point-to-MultiPoint)。
广播多路访问型网络,如Ethernet、Token Ring、FDDI。NBMA型网络,如Frame Relay、X.25、SMDS。Point-to-Point型网络,如PPP、HDLC。
(4)指派路由器(DR)和备份指派路由器(BDR)。
在多路访问网络上可能存在多个路由器,为了避免路由器之间建立完全相邻关系而引起的大量开销,OSPF要求在区域中选举一个DR。每个路由器都与之建立完全相邻关系。DR负责收集所有的链路状态信息,并发布给其他路由器。选举DR的同时也选举一个BDR,在DR失效时,BDR担负起DR的职责。
当路由器开启一个端口的OSPF路由时,将会从这个端口发出一个Hello报文,以后它也将以一定的间隔周期性地发送Hello报文。OSPF路由器用Hello报文来初始化新的相邻关系以及确认相邻的路由器邻居之间的通信状态。
对广播型网络和非广播型多路访问网络,路由器使用Hello协议选举出一个DR。在广播型网络里,Hello报文使用多播地址224.0.0.5周期性广播,并通过这个过程自动发现路由器邻居。在NBMA网络中,DR负责向其他路由器逐一发送Hello报文。
操作
OSPF协议操作总共经历了建立邻接关系、选举DR/BDR、发现路由器等步骤。
(1)建立路由器的邻接关系。
所谓“邻接关系”(Adjacency)是指OSPF路由器以交换路由信息为目的,在所选择的相邻路由器之间建立的一种关系。路由器首先发送拥有自身ID信息(Loopback端口或最大的IP地址)的Hello报文。与之相邻的路由器如果收到这个Hello报文,就将这个报文内的ID信息加入到自己的Hello报文内。
如果路由器的某端口收到从其他路由器发送的含有自身ID信息的Hello报文,则它根据该端口所在网络类型确定是否可以建立邻接关系。
在点对点网络中,路由器将直接和对端路由器建立邻接关系,并且该路由器将直接进入到步骤(3)操作:发现其他路由器。若为MultiAccess网络,该路由器将进入选举步骤。
(2)选举DR/BDR。
不同类型的网络选举DR和BDR的方式不同。
MultiAccess网络支持多个路由器,在这种状况下,OSPF需要建立起作为链路状态和LSA更新的中心节点。选举利用Hello报文内的ID和优先权(Priority)字段值来确定。优先权字段值大小为0~255,优先权值最高的路由器成为DR。如果优先权值大小一样,则ID值最高的路由器选举为DR,优先权值次高的路由器选举为BDR。优先权值和ID值都可以直接设置。
(3)发现路由器。
在这个步骤中,路由器与路由器之间首先利用Hello报文的ID信息确认主从关系,然后主从路由器相互交换部分链路状态信息。每个路由器对信息进行分析比较,如果收到的信息有新的内容,路由器将要求对方发送完整的链路状态信息。这个状态完成后,路由器之间建立完全相邻(Full Adjacency)关系,同时邻接路由器拥有自己独立的、完整的链路状态数据库。
在MultiAccess网络内,DR与BDR互换信息,并同时与本子网内其他路由器交换链路状态信息。
在Point-to-Point或Point-to-MultiPoint网络中,相邻路由器之间互换链路状态信息。
(4)选择适当的路由器。
当一个路由器拥有完整独立的链路状态数据库后,它将采用SPF算法计算并创建路由表。OSPF路由器依据链路状态数据库的内容,独立地用SPF算法计算到每一个目的网络的路径,并将路径存入路由表中。
OSPF利用量度(Cost)计算目的路径,Cost最小者即为最短路径。在配置OSPF路由器时可根据实际情况,如链路带宽、时延或经济上的费用设置链路Cost大小。Cost越小,则该链路被选为路由的可能性越大。
(5)维护路由信息。
当链路状态发生变化时,OSPF通过Flooding过程通告网络上其他路由器。OSPF路由器接收到包含新信息的链路状态更新报文,将更新自己的链路状态数据库,然后用SPF算法重新计算路由表。在重新计算过程中,路由器继续使用旧路由表,直到SPF完成新的路由表计算。新的链路状态信息将发送给其他路由器。值得注意的是,即使链路状态没有发生改变,OSPF路由信息也会自动更新,默认时间为30分钟。
OSPF路由协议的基本特征
前文已经说明OSPF路由协议是一种链路状态的路由协议,为了更好地说明OSPF路由协议的基本特征,将OSPF路由协议与距离矢量路由协议之一的RIP比较如下:
RIP中用于表示目的网络远近的唯一参数为跳(Hop),即到达目的网络所要经过的路由器个数。在RIP路由协议中,该参数被限制最大为15,即RIP路由信息最多能传递至第16个路由器;对于OSPF路由协议,路由表中表示目的网络的参数为Cost,该参数为一虚拟值,与网络中链路的带宽等相关,即OSPF路由信息不受物理跳数的限制,因此OSPF比较适合于大型网络中。
RIPv1路由协议不支持变长子网屏蔽码(VLSM),被认为是RIP路由协议不适用于大型网络的又一个重要原因。采用变长子网屏蔽码可以在最大限度上节约IP地址。OSPF路由协议对VLSM有良好的支持性。
RIP路由协议路由收敛较慢。RIP路由协议周期性地将整个路由表作为路由信息广播至网络中,该广播周期为30s。在一个较为大型的网络中,RIP会产生很大的广播信息,占用较多的网络带宽资源。由于R1P协议30s的广播周期,影响了RIP路由协议的收敛,甚至出现不收敛的现象。OSPF是一种链路状态的路由协议,当网络比较稳定时,网络中的路由信息是比较少的,并且其广播也不是周期性的,因此OSPF路由协议即使是在大型网络中也能够较快地收敛。
在RIP中,网络是一个平面的概念,并无区域及边界等的定义。随着无级路由CIDR概念的出现,RIP协议就明显落伍了。在OSPF路由协议中,一个网络,或者说是一个路由域可以划分为很多个区域,每一个区域通过OSPF边界路由器相连,区域间可以通过路由汇聚来减少路由信息,减小路由表,提高路由器的运算速度。
OSPF路由协议支持路由验证,只有互相通过路由验证的路由器之间才能交换路由信息。而且OSPF可以对不同的区域定义不同的验证方式,提高网络的安全性。
建立OSPF邻接关系过程
OSPF路由协议通过建立交互关系来交换路由信息,但并不是所有相邻的路由器都会建立OSPF交互关系。下面简要介绍OSPF建立adjacency的过程。
OSPF协议是通过Hello协议数据包来建立及维护相邻关系的,同时也用其来保证相邻路由器之间的双向通信。OSPF路由器会周期性地发送Hello数据包,当这个路由器看到自身被列于其他路由器的Hello数据包里时,这两个路由器之间会建立起双向通信。在多接入的环境中,Hello数据包还用于发现指定路由器(DR),通过DR来控制与哪些路由器建立交互关系。
两个OSPF路由器建立双向通信之后的第二个步骤是进行数据库的同步,数据库同步是所有链路状态路由协议的最大的共性。在OSPF路由协议中,数据库同步关系仅仅在建立交互关系的路由器之间保持。
OSPF的数据库同步是通过OSPF数据库描述数据包(Database Description Packets)来进行的。OSPF路由器周期性地产生数据库描述数据包,该数据包是有序的,即附带有序列号,并将这些数据包对相邻路由器广播。相邻路由器可以根据数据库描述数据包的序列号与自身数据库的数据作比较,若发现接收到的数据比数据库内的数据序列号大,则相邻路由器会针对序列号较大的数据发出请求,并用请求得到的数据来更新其链路状态数据库。
将OSPF相邻路由器从发送Hello数据包,建立数据库同步至建立完全的OSPF交互关系的过程分成几个不同的状态,如下所述。
(1)Down:这是OSPF建立交互关系的初始化状态,表示在一定时间之内没有接收到从某一相邻路由器发送来的信息。在非广播性的网络环境内,OSPF路由器还可能对处于Down状态的路由器发送Hello数据包。
(2)Attempt:该状态仅在NBMA环境,如帧中继、X.25或ATM环境中有效,表示在一定时间内没有接收到某一相邻路由器的信息,但是OSPF路由器仍必须通过以一个较低的频率向该相邻路由器发送Hello数据包来保持联系。
(3)Init:在该状态时,OSPF路由器已经接收到相邻路由器发送来的Hello数据包,但自身的IP地址并没有出现在该Hello数据包内,也就是说,双方的双向通信还没有建立起来。
(4)2-Way:这个状态可以说是建立交互方式真正的开始步骤。在这个状态,路由器看到自身已经处于相邻路由器的Hello数据包内,双向通信已经建立。指定路由器及备份指定路由器的选择正是在这个状态完成的。在这个状态,OSPF路由器还可以根据其中的一个路由器是否指定路由器或根据链路是否点对点或虚拟链路来决定是否建立交互关系。
(5)Exstart:这个状态是建立交互状态的第一个步骤。在这个状态,路由器要决定用于数据交换的初始的数据库描述数据包的序列号,以保证路由器得到的永远是最新的链路状态信息。同时,在这个状态路由器还必须决定路由器之间的主备关系,处于主控地位的路由器会向处于备份地位的路由器请求链路状态信息。
(6)Exchange:在这个状态,路由器向相邻的OSPF路由器发送数据库描述数据包来交换链路状态信息,每一个数据包都有一个数据包序列号。在这个状态,路由器还有可能向相邻路由器发送链路状态请求数据包来请求其相应数据。从这个状态开始,可以说OSPF处于Flood状态。
(7)Loading:在Loading状态,OSPF路由器会就其发现的相邻路由器的新的链路状态数据及自身的已经过期的数据向相邻路由器提出请求,并等待相邻路由器的回答。
(8)Full:这是两个OSPF路由器建立交互关系的最后一个状态,这时建立起交互关系的路由器之间已经完成了数据库同步的工作,它们的链路状态数据库已经一致。
OSPF的DR及BDR
在DR和BDR出现之前,每一台路由器和他的所有邻居成为完全网状的OSPF邻接关系,这样5台路由器之间将需要形成10个邻接关系,同时将产生25条LSA。而且在多址网络中,还存在自己发出的LSA从邻居的邻居发回来,导致网络上产生很多LSA的拷贝。所以基于这种考虑,产生了DR和BDR。
完成的工作内容
DR将完成如下工作:
(1)描述这个多址网络和该网络上剩下的其他相关路由器。
(2)管理这个多址网络上的flooding过程。
(3)同时为了冗余性,还会选取一个BDR,作为双备份之用。
选取规则
DR BDR选取规则:DR BDR选取是以接口状态机的方式触发的。
(1)路由器的每个多路访问(Multi-access)接口都有个路由器优先级(Router Priority),8位长的一个整数,范围是0~255,Cisco路由器默认的优先级是1,优先级为0的话将不能选举为DR/BDR。优先级可以通过命令ip ospf priority进行修改。
(2)Hello包里包含了优先级的字段,还包括了可能成为DR/BDR的相关接口的IP地址。
(3)当接口在多路访问网络上初次启动的时候,它把DR/BDR地址设置为0.0.0.0,同时设置等待计时器(Wait Timer)的值等于路由器无效间隔(Router Dead Interval)。
选取过程
DR BDR选取过程:
(1)路由器X在和邻居建立双向(2-Way)通信之后,检查邻居的Hello包中Priority,DR和BDR字段,列出所有可以参与DR/BDR选举的邻居。
(2)如果有一台或多台这样的路由器宣告自己为BDR(也就是说,在其Hello包中将自己列为BDR,而不是DR),选择其中拥有最高路由器优先级的成为BDR;如果相同,选择拥有最大路由器标识的。如果没有路由器宣告自己为BDR,选择列表中路由器拥有最高优先级的成为BDR(同样排除宣告自己为DR的路由器),如果相同,再根据路由器标识。
(3)按如下计算网络上的DR。如果有一台或多台路由器宣告自己为DR(也就是说,在其Hello包中将自己列为DR),选择其中拥有最高路由器优先级的成为DR;如果相同,选择拥有最大路由器标识的。如果没有路由器宣告自己为DR,将新选举出的BDR设定为DR。
(4)如果路由器X新近成为DR或BDR,或者不再成为DR或BDR,重复步骤(2)和(3),然后结束选举。这样做是为了确保路由器不会同时宣告自己为DR和BDR。
(5)要注意的是,当网络中已经选举了DR/BDR后,又出现了1台新的优先级更高的路由器,DR/BDR是不会重新选举的。
(6)DR/BDR选举完成后,DRother只和DR/BDR形成邻接关系。所有的路由器将组播Hello包到AllSPFRouters地址224.0.0.5以便它们能跟踪其他邻居的信息,即DR将泛洪update packet到224.0.0.5;DRother只组播update packet到AllDRouter地址224.0.0.6,只有DR/BDR监听这个地址。
筛选过程
简单地说,DR的筛选过程如下:
(1)优先级为0的不参与选举。
(2)优先级高的路由器为DR。
(3)优先级相同时,以router ID大为DR;router ID以回环接口中最大IP为准;若无回环接口,以真实接口最大IP为准。
(4)默认条件下,优先级为1。
OSPF路由器类型
OSPF路由器类型如下图所示。
OSPF路由器类型
区域内路由器(Internal Routers)。
该类路由器的所有接口都属于同一个OSPF区域。
区域边界路由器ABR(Area Border Routers)。
该类路由器可以同时属于两个以上的区域,但其中一个必须是骨干区域。ABR用来连接骨干区域和非骨干区域,它与骨干区域之间既可以是物理连接,也可以是逻辑上的连接。
骨干路由器(Backbone Routers)。
该类路由器至少有一个接口属于骨干区域。因此,所有的ABR和位于Area0的内部路由器都是骨干路由器。
自治系统边界路由器(AS Boundary Routers,ASBR)。
与其他AS交换路由信息的路由器称为ASBR。ASBR并不一定位于AS的边界,它可能是区域内路由器,也可能是ABR。只要一台OSPF路由器引入了外部路由的信息,它就成为ASBR。
OSPF LSA类型
随着OSPF路由器种类概念的引入,OSPF路由协议又对其链路状态广播数据包(LSA)做出了分类。OSPF将链路状态广播数据包主要分成以下6类,如下表所示。
LSA类型
(1)1类LSA(路由器LSA):每台路由器都通告1类LSA,描述了与路由器直连的所有链路(接口)状态,只能在本区域内扩散。
(2)2类LSA(网络LSA):只有DR才有资格产生,只能在本区域内扩散,描述了多路访问网络的所有路由器(Router ID)和链路的子网掩码。
(3)3类LSA(汇总LSA):只有ABR可以产生,能在整个OSPF自治系统扩散,描述了目的网路的路由(还可能包含汇总路由)。
(4)4类LSA(汇总LSA):仅当区域中有ASBR时,ABR才会产生,该LSA标识了ASBR,提供一条前往该ASBR的路由。
(5)5类LSA(外部LSA):只能由ASBR产生,描述了前往OSPF自治系统外的网络的路由,被扩散到整个AS(除各种末节区域外)。
(6)7类LSA(用于NSSA的LSA):只能由NSSA ASBR产生,只能出现在NSSA,而NSSA ABR将其转换为5类LSA并扩散到整个OSPF自治系统。
OSPF区域类型
根据区域所接收的LSA类型不同,可将区域划分为以下几种类型:
(1)标准区域:默认的区域类型,它接收链路更新、汇总路由和外部路由,如下图所示。
标准区域示例
(2)骨干区域:骨干区域为Area 0,其他区域都与之相连以交换路由信息,该区域具有标准区域的所有特征。
(3)末节区域:不接收4类汇总LSA和5类外部LSA,但接收3类汇总LSA,使用默认路由到AS外部网络(自动生成),该区域不包含ASBR(除非ABR也是ASBR)。
(4)绝对末节区域:这个是Cisco专用。它不接收3类、4类汇总LSA和5类外部LSA,使用默认路由到AS外部网络(自动生成),该区域不包含ASBR(除非ABR也是ASBR)。
(5)NSSA:不接收4类汇总LSA和5类外部LSA,但接收3类汇总LSA且可以有ASBR,使用默认路由前往外部网络,默认路由是由与之相连的ABR生成的,但默认情况下不会生成,要让ABR生成默认路由,可使用命令area area-id nssa default-information-originate。
(6)绝对末节NSSA:这个是Cisco公司专用。它不接收3类、4类汇总LSA和5类外部LSA且可以有ASBR,使用默认路由到AS外部网络,默认路由是自动生成的。
每一种区域中允许泛洪的LSA总结如下表所示。
区域允许LSA总结
注:*为ABR路由器使用一个类型3的LSA通告默认路由。
虚链路
在OSPF路由协议中存在一个骨干区域(Backbone),该区域包括属于这个区域的网络及相应的路由器,骨干区域必须是连续的,同时也要求其余区域必须与骨干区域直接相连。骨干区域一般为区域0,其主要工作是在其余区域间传递路由信息。所有的区域,包括骨干区域之间的网络结构情况是互不可见的,当一个区域的路由信息对外广播时,其路由信息是先传递至区域0(骨干区域),再由区域0将该路由信息向其余区域作广播。
骨干区域不连续虚链路
在实际网络中,可能会存在骨干区域不连续或某一个区域与骨干区域物理不相连的情况,在这两种情况下,系统管理员可以通过设置虚拟链路的方法来解决,如上图和下图所示。
与骨干区域物理不相连虚链路
虚拟链路设置在两个路由器之间,这两个路由器都有一个端口与同一个非骨干区域相连。虚拟链路被认为是属于骨干区域的,在OSPF路由协议看来,虚拟链路两端的两个路由器被一个点对点的链路连在一起。在OSPF路由协议中,通过虚拟链路的路由信息是作为域内路由来看待的。
OSPF配置命令汇总
OSPF常用配置命令如下表所示。
OSPF配置命令汇总
OSPF配置实例
下面,以如下图所示的一个网络为例说明OSPF路由选择协议的配置方法,该网络中有0和1两个区域,其中R1的S1端口、R2的S0端口属于区域0;而R3、R1的S0端口、R2的S1端口则属于区域1。
OSPF配置拓扑图
下面列出三个路由器配置OSPF的指令:
从上面的配置实例中可以知道,在配置OSPF时可以将子网进行合并,以减少条目,提高效率。例如,R3的邻接子网有192.168.1.0、192.168.2.0、192.168.3.0三个,因此可以合并为192.0.0.0/255.0.0.0;当然合并为192.168.0.0/255.255.0.0也是可行的。
59. GVRP定义的四种定时器中缺省值最小的是( )。
A. Hold 定时器
B. Join定时器
C. Leave定时器
D. LeaveAll定时器
60. 下列命令片段的含义是( )。

A. 创建了两个VLAN
B. 恢复接口上VLAN缺省配置
C. 配置VLAN的名称
D. 恢复当前VLAN名称的缺省值
61. ( )的含义是一台交换机上的VLAN配置信息可以传播、复制到网络中相连的其他交换机上。
A. 中继端口
B. VLAN中继
C. VLAN透传
D. SuperVLAN
机架式交换机是一种插槽式的交换机,这种交换机扩展性较好,可支持不同的网络类型,如以太网、快速以太网、千兆位以太网、ATM、令牌环及FDDI(Fiber Distributed Data Interface,光纤分布式数据接口)等,但价格较贵。固定配置式带扩展槽交换机是一种有固定端口数并带少量扩展槽的交换机,这种交换机在支持固定端口类型网络的基础上,还可以支持其他类型的网络,价格居中。固定配置式不带扩展槽交换机仅支持一种类型的网络,但价格最便宜。
交换机的性能指标主要有机架插槽数、扩展槽数、最大可堆叠数、最小/最大端口数、支持的网络类型、背板吞吐量、缓冲区大小、最大物理地址表大小、最大电源数、支持协议和标准、支持第3层交换、支持多层(4~7层)交换、支持多协议路由、支持路由缓存、支持网管类型、支持端口镜像、服务质量(Quality of Service,QoS)、支持基于策略的第2层交换、每端口最大优先级队列数、支持最小/最大带宽分配、冗余、热交换组件、负载均衡等。
62. 以下关于BGP的说法中,正确的是( )。
A. BGP是一种链路状态协议
B. BGP通过UDP发布路由信息
C. BGP依据延迟来计算网络代价
D. BGP能够检测路由循环
63. 快速以太网100BASE-T4采用的传输介质为( )。
A. 3类UTP
B. 5类UTP
C. 光纤
D. 网轴电缆
1995年,100Mb/s的快速以太网标准IEEE 802.3u正式颁布,这是基于10Base-T和10Base-F技术、在基本布线系统不变的情况下开发的高速局域网标准。
快速以太网使用的集线器可以是共享型或交换型,也可以通过堆叠多个集线器扩大端口数量。互相连接的集线器起到了中继的作用,扩大了网络的跨距。快速以太网使用的中继器分为两类。I类中继器中包含编码/译码功能,它的延迟比II类中继器大。
快速以太网的数据速率提高了10倍,而最小帧长没变,所以冲突时槽缩小为4.12μs。以太网计算冲突时槽的公式为

式中,S为网络的跨距(最长传输距离);0.7C为0.7倍光速(信号传播速率);tphy为发送站物理层时延,由于发送站发送和接收两次,所以取其时延的两倍值。
可得计算快速以太网跨距的计算公式为

传输介质是网络的最基本部分,用于在用户设备之间传输信号。选择传输介质时,应当考虑如下因素。
◆安装特性:包括单段介质的最大长度、网络的覆盖范围、铺设时允许的最小弯角和最大直径等。
◆连接性:包括网络拓扑、可支持的连接数据等。
◆容量及性能:包括可使用的带宽、支持的逻辑信道数、每个信道可以支持的最大传输速率等。
◆防护性能:包括电气干扰与噪声、物理损害、安全性等。
◆价格:介质的价格。
目前可以选择的介质类型包括以下几类。
◆无屏蔽双绞线:支持点到点连接(包括环形),价格较低,用于计算机联网的双绞线应为3类线以上。
◆屏蔽双绞线:支持点到点连接(包括环形),仅用于电磁干扰较严重的环境,价格适中。
◆基带同轴电缆:支持总线连接(包括环形),价格适中。
◆宽带同轴电缆:支持总线连接(包括环形),价格略高。
◆光纤:支持点到点连接(包括环形),价格偏高。
随着结构化布线技术的推广以及多介质应用的增多,双绞线和光纤成为组网的主要传输介质。
需要指出的是,传输介质的选择应当具有足够的超前意识,因为传输介质的布放一般会对建筑物的本身造成影响,因此应当尽可能避免因设备的更新换代和升级而改变传输介质。
以太网是最早使用的局域网,也是目前使用最广泛的网络产品。以太网有10Mb/s、100Mb/s、1000Mb/s、10Gb/s等多种速率。
以太网传输介质
以太网比较常用的传输介质包括同轴电缆、双绞线和光纤三种,以IEEE 802.3委员会习惯用类似于10Base-T的方式进行命名。这种命名方式由三个部分组成:
(1)10:表示速率,单位是Mb/s。
(2)Base:表示传输机制,Base代表基带,Broad代表宽带。
(3)T:传输介质,T表示双绞线、F表示光纤、数字代表铜缆的最大段长。
传输介质的具体命名方案如下表所示,了解这些知识是十分必要的。
以太网传输介质表
以太网时隙
时间被分为离散的区间称为时隙(Slot Time)。帧总是在时隙开始的一瞬间开始发送。一个时隙内可能发送0,1或多个帧,分别对应空闲时隙、成功发送和发生冲突的情况。
设置时隙理由
在以太网规则中,若发生冲突,则必须让网上每个主机都检测到。信号传播整个介质需要一定的时间。考虑极限情况,主机发送的帧很小,两冲突主机相距很远。在A发送的帧传播到B的前一刻,B开始发送帧。这样,当A的帧到达B时,B检测到了冲突,于是发送阻塞信号。B的阻塞信号还没有传输到A,A的帧已发送完毕,那么A就检测不到冲突,而误认为已发送成功,不再发送。由于信号的传播时延,检测到冲突需要一定的时间,所以发送的帧必须有一定的长度。这就是时隙需要解决的问题。
在最坏情况下,检测到冲突所需的时间
若A和B是网上相距最远的两个主机,设信号在A和B之间传播时延为τ,假定A在t时刻开始发送一帧,则这个帧在t+τ时刻到达B,若B在t+τ-ε时刻开始发送一帧,则B在t+τ时就会检测到冲突,并发出阻塞信号。阻塞信号将在t+2τ时到达A。所以A必须在t+2τ时仍在发送才可以检测到冲突,所以一帧的发送时间必须大于2τ。
按照标准,10Mb/s以太网采用中继器时,连接最大长度为2500m,最多经过4个中继器,因此规定对于10Mb/s以太网规定一帧的最小发送时间必须为51.2μs。51.2μs也就是512位数据在10Mb/s以太网速率下的传播时间,常称为512位时。这个时间定义为以太网时隙。512位=64字节,因此以太网帧的最小长度为64字节。
冲突发生的时段
(1)冲突只能发生在主机发送帧的最初一段时间,即512位时的时段。
(2)当网上所有主机都检测到冲突后,就会停发帧。
(3)512位时是主机捕获信道的时间,如果某主机发送一个帧的512位时,而没有发生冲突,以后也就不会再发生冲突了。
提高传统以太网带宽的途径
以往被淘汰、传统的以太网是以10Mb/s速率半双工方式进行数据传输的。随着网络应用的迅速发展,网络的带宽限制已成为进一步提高网络性能的瓶颈。提高传统以太网带宽的方法主要有以下3种。
交换以太网
以太网使用的CSMA/CD是一种竞争式的介质访问控制协议,因此从本质上说它在网络负载较低时性能不错,但如果网络负载很大时,冲突会很常见,因此导致网络性能的大幅下降。为了解决这一瓶颈问题,“交换式以太网”应运而生,这种系统的核心是使用交换机代替集线器。交换机的特点是,其每个端口都分配到全部10Mb/s的以太网带宽。若交换机有8个端口或16个端口,那么它的带宽至少是共享型的8倍或16倍(这里不包括由于减少碰撞而获得的带宽)。
交换以太网能够大幅度的提高网络性能的主要原因是:
.减少了每个网段中的站点的数量;
.同时支持多个并发的通信连接。
网络交换机有三种交换机制:直通(Cut through)、存储转发(Store and forward)和碎片直通(Fragment free Cut through)。
交换式以太网具有几个优点:第一,它保留现有以太网的基础设施,保护了用户的投资;第二,提高了每个站点的平均拥有带宽和网络的整体带宽;第三,减少了冲突,提高了网络传输效率。
全双工以太网
全双工技术可以提供双倍于半双工操作的带宽,即每个方向都支持10Mb/s,这样就可以得到20Mb/s的以太网带宽。当然这还与网络流量的对称度有关。
全双工操作吸引人的另一个特点是它不需要改变原来10Base-T网络中的电缆布线,可以使用和10Base-T相同的双绞线布线系统,不同的是它使用一对双绞线进行发送,而使用另一对进行接收。这个方法是可行的,因为一般10Base-T布线是有冗余的(共4对双绞线)。
高速服务器连接
众多的工作站在访问服务器时可能会在服务器的连接处出现瓶颈,通过高速服务器连接可以解决这个问题。使用带有高速端口的交换机(如24个10Mb/s端口,1个100Mb/s或1000Mb/s高速端口),然后再把服务器接在高速端口上并使用全双工操作。这样服务器就可以实现与网络200Mb/s或2000Mb/s的连接。
以太网的帧格式
以太网帧的格式如下图所示,包含的字段有前导码、目的地址、源地址、数据类型、发送的数据,以及帧校验序列等。这些字段中除了数据字段是变长以外,其余字段的长度都是固定的。
以太网的帧结构
注:字段的长度以字节为单位
前导码(P)字段占用8字节。
目的地址(DA)字段和源地址(SA)字段都是占用6字节的长度。目的地址用于标识接收站点的地址,它可以是单个的地址,也可以是组地址或广播地址,当地址中最高字节的最低位设置为1时表示该地址是一个多播地址,用十六进制数可表示为01:00:00:00:00:00,假如全部48位(每字节8位,6字节即48位)都是1时,该地址表示是一个广播地址。源地址用于标识发送站点的地址。
类型(Type)字段占用两字节,表示数据的类型,如0x0800表示其后的数据字段中的数据包是一个IP包,而0x0806表示ARP数据包,0x8035表示RARP数据包。
数据(Data)字段占用46~1500个不等长的字节数。以太网要求最少要有46字节的数据,如果数据不够长度,必须在不足的空间插入填充字节来补充。
帧校验序列(FCS)字段是32位(即4字节)的循环冗余码。
64. CSMA/CD采用的介质访问技术属于资源的( )。
A. 轮流使用
B. 固定分配
C. 竞争使用
D. 按需分配
65. WLAN接入安全控制中,采用的安全措施不包括( )。
A. SSID访问控制
B. CA认证
C. 物理地址过滤
D. WPA2安全认证
66. 下列IEEE 802.11系列标准中,WLAN的传输速率达到300Mbps的是( )。
A. 802.11a
B. 802.11b
C. 802.11g
D. 802.11n
2009年9月11日IEEE 802.11n标准正式发布。802.11n结合了MIMO与OFDM技术,可以将WLAN的传输速率由目前802.11a/802.11g的54Mbps提高到300Mbps,甚至600Mbps。
正交频分复用(Orthogonal Frequency Division Multiplexing, OFDM)是一种多载波调制技术。其主要思想是将信道划分成若干个正交子信道,将高速数据信号转换成并行的低速子数据流,并将各个子数据流交织编码,调制到正交的子信道上进行传输,在接收端采用相关技术可以将正交信号再分开。OFDM具有较高的频谱利用率。
MIMO(Multiple Input Multiple Output,多入多出)是通过多径无线信道实现的,传输的信息流经过空时编码成N个子信息流,由N个天线发射出去,经空间信道传输后由M个接收天线接收。多天线接收机利用先进的空时编码处理功能对数据流进行分离和解码,从而实现最佳的处理结果。
传输速率是指数据在信道中传输的速度。可以用码元传输速率和信息传输速率两种方式来描述。
码元是在数字通信中常常用时间间隔相同的符号来表示一位二进制数字。这样的时间间隔内的信号称为二进制码元,而这个间隔被称为码元长度。码元传输速率又称为码元速率或传码率。码元速率又称为波特率,每秒中传送的码元数。若数字传输系统所传输的数字序列恰为二进制序列,则等于每秒钟传送码元的数目,而在多电平中则不等同。单位为“波特/秒”,常用符号Baud/s表示。
信息传输速率即位率,位/秒(b/s),表示每秒中传送的信息量。
设定码元传输速率为RB,信息速率Rb,则两者的关系如下:
Rb=RB×log2M
其中,M为采用的进制。例如,对于采用十六进制进行传输信号,则其信息速率就是码元速率的4倍;如果数字信号采用四级电平即四进制,则一个四进制码元对应两个二进制码元(4=22)。
67. 某单位计划购置容量需求为60TB的存储设备,配置一个RAID组,采用RAID5冗余,并配置一块全局热备盘,至少需要( )块单块容量为4TB的磁盘。
A. 15
B. 16
C. 17
D. 18
本知识点的要点是掌握与磁盘相关的最重要的概念与计算公式。
磁盘是最常见的一种外部存储器,它是由一至多个圆形磁盘组成的,其常见技术指标如下。
(1)磁道数=(外半径-内半径)×道密度×记录面数
说明:硬盘的第一面与最后一面是起保护作用的,一般不用于存储数据,所以在计算的时候要减掉。例如,6个双面的盘片的有效记录面数是6×2-2=10。
(2)非格式化容量=位密度×3.14×最内圈直径×总磁道数
说明:每个磁道的位密度是不相同的,但每个磁道的容量却是相同的。一般来说,0磁道是最外面的磁道,其位密度最小。
(3)格式化容量=总磁道数×每道扇区数×扇区容量
(4)平均数据传输速率=每道扇区数×扇区容量×盘片转速
说明:盘片转速是指磁盘每秒钟转多少圈。
(5)存取时间=寻道时间+等待时间
说明:寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间。显然,寻道时间与磁盘的转速没有关系。
RAID技术旨在缩小日益扩大的CPU速度和磁盘存储器速度之间的差距。其策略是用多个较小的磁盘驱动器替换单一的大容量磁盘驱动器,同时合理地在多个磁盘上分布存放数据以支持同时从多个磁盘进行读写,从而改善了系统的I/O性能。小容量驱动器阵列与大容量驱动器相比,具有成本低、功耗小、性能好等优势。低代价的编码容错方案在保持阵列的速度与容量优势的同时保证了极高的可靠性,同时也较容易扩展容量。但是由于允许多个磁头同时进行操作以提高I/O数据传输速度,因此不可避免地提高了出错的概率。
为了补偿可靠性方面的损失,RAID使用存储的校验信息(Stored Parity Information)来从错误中恢复数据。最初,Inexpensive一词主要针对当时另一种技术(Single Large Expensive Disk,SLED)而言,但随着技术的发展,SLED已经过时,RAID和non-RAID皆采用了类似的磁盘技术。因此,RAID现在代表独立磁盘冗余阵列,用Independent来强调RAID技术所带来的性能改善和更高的可靠性。
RAID机制中共分8个级别,工业界公认的标准分别为RAID0~RAID7。RAID应用的主要技术有分块技术、交叉技术和重聚技术。
(1)RAID0级(无冗余和无校验的数据分块):具有最高的I/O性能和最高的磁盘空间利用率,易管理,但系统的故障率高,属于非冗余系统,主要应用于那些关注性能、容量和价格而不是可靠性的应用程序。
(2)RAID1级(磁盘镜像阵列):由磁盘对组成,每一个工作盘都有其对应的镜像盘,上面保存着与工作盘完全相同的数据拷贝,具有最高的安全性,但磁盘空间利用率只有50%。RAID1主要用于存放系统软件、数据及其他重要文件。它提供了数据的实时备份,一旦发生故障,所有的关键数据即刻就可使用。
(3)RAID2级(采用纠错海明码的磁盘阵列):采用了海明码纠错技术,用户需增加校验盘来提供单纠错和双验错功能。对数据的访问涉及阵列中的每一个盘。大量数据传输时I/O性能较高,但不利于小批量数据传输。实际应用中很少使用。
(4)RAID3和RAID4级(采用奇偶校验码的磁盘阵列):把奇偶校验码存放在一个独立的校验盘上,如果有一个盘失效,其上的数据可以通过对其他盘上的数据进行异或运算得到。读数据很快,但因为写入数据时要计算校验位,速度较慢。
(5)RAID5级(无独立校验盘的奇偶校验码磁盘阵列):与RAID4类似,但没有独立的校验盘,校验信息分布在组内所有盘上,对于大、小批量数据读写性能都很好。RAID4和RAID5使用了独立存取(Independent Access)技术,阵列中每一个磁盘都相互独立地操作,所以I/O请求可以并行处理。该技术非常适合于I/O请求率高的应用而不太适应于要求高数据传输率的应用。与其他方案类似,RAID4、RAID5也应用了数据分块技术,但块的尺寸相对大一点。
(6)RAID6级:这是一个强化的RAID产品结构。阵列中设置一个专用校验盘,它具有独立的数据存取和控制路径,可经由独立的异步校验总线、高速缓存总线或扩展总线来完成快速存取的传输操作。值得注意的是,RAID6在校验盘上使用异步技术读写,这种异步仅限于校验盘,而阵列中的数据盘和面向主机的I/O传输仍与以前的RAID结构雷同,即采用的是同步操作技术。仅此校验异步存取,加上Cache存取传输,RAID6的性能就比RAID5要好。
(7)RAID7级:RAID7等级是至今为止理论上性能最高的RAID模式,因为它从组建方式上就已经和以往的方式有了重大的不同。以往一个硬盘是一个组成阵列的“柱子”,而在RAID 7中,多个硬盘组成一个“柱子”,它们都有各自的通道。这样做的好处就是在读写某一区域的数据时,可以迅速定位,而不会因为以往因单个硬盘的限制同一时间只能访问该数据区的一部分,在RAID7中,以前的单个硬盘相当于分割成多个独立的硬盘,有自己的读写通道,效率也就不言自明了。然而,RAID7的设计与相应的组成规模注定了它是一揽子承包计划。
总体上说,RAID7是一个整体的系统,有自己的操作系统,有自己的处理器,有自己的总线,而不是通过简单的插卡就可以实现的。RAID7所有的I/O传输都是异步的,因为它有自己独立的控制器和带有Cache的接口,与系统时钟并不同步。所有的读写操作都将通过一个带有中心Cache的高速系统总线进行传输,称为X-Bus。专用的校验硬盘可以用于任何通道。带有完整功能的即时操作系统内嵌于阵列控制微处理器,这是RAID7的心脏,负责各通道的通信及Cache的管理,这也是它与其他等级最大不同点之一。归纳起来,RAID7的主要特点如下。
.连通性:可增至12个主机接口。
.扩展性:线性容量可增至48个硬盘。
.开放式系统:运用标准的SCSI硬盘、标准的PC总线、主板及SIMM内存,集成Cache的数据总线(就是上文提到的X-Bus),在Cache内部完成校验生成工作,多重的附加驱动可以随时热机待命,提高冗余率和灵活性。
.易管理性:SNMP可以让管理员远程监视并实现系统控制。
按照RAID7设计者的说法,这种阵列将比其他RAID等级提高150%~600%写入时的I/O性能,但这引起了不小的争议。
68. 对某银行业务系统的网络方案设计时,应该优先考虑( ) 原则。
A. 开放性
B. 先进性
C. 经济性
D. 高可用性
系统方案设计包括总体设计和各部分的详细设计。
.系统总体设计:包括系统的总体架构方案设计、软件系统的总体架构设计、数据存储的总体设计、计算机和网络系统的方案设计等。
.系统详细设计:包括代码设计、数据库设计、人机界面设计、处理过程设计等。
69. 在项目管理过程中,变更总是不可避免,作为项目经理应该让项目干系人认识到( )。
A. 在项目设计阶段,变更成本较低
B. 在项目实施阶段,变更成本较低
C. 项目变更应该由项目经理批准
D. 应尽量满足建设方要求,不需要进行变更控制
定义
项目干系人(Project Stakeholder),也称为利害相关者,是积极参与项目,或其利益因项目的实施或完成而受到积极或消极影响的个人或组织,他们还会对项目的目标和结果产生影响。项目管理团队必须明确项目的干系人,确定其需求,然后对这些需求进行管理和施加影响,确保项目取得成功。
干系人对项目的影响
包括积极的影响和消极的影响。项目管理团队不仅要关注积极的项目干系人,也不能忽略消极项目干系人。项目关键干系人包括:
.项目经理(Project Manager)
.顾客/客户(Customer/User)
.执行组织(Performing Organization)
.项目团队成员(Project Team Members)
.项目管理团队(Project Management Team)
.出资人(Sponsor)
.有影响力的人(Influencers)
.项目管理办公室(PMO)
项目经理是负责实现项目目标的个人。
一般要求
.广博的知识(项目管理知识、系统集成行业知识、客户行业知识)。
.丰富的经历。
.良好的协调能力。
.良好的职业道德。
.良好的沟通与表达能力。
.良好的领导能力。
好的项目经理
一个好的项目经理能够使项目完成得出色,把握项目计划包括成本、进度、范围以及质量等,把客户的满意度提到最高。要做好一个项目经理,需要:
.真正理解项目经理的角色。
.重视项目团队的管理,奖罚分明。
.计划、计划、再计划。
.真正理解“一把手工程”。
.切记注重用户参与。
定义
把各种知识、技能、手段和技术应用于项目活动之中,以达到项目的要求。管理一个项目包括:
.识别要求。
.确定清楚而又能实现的目标。
.权衡质量、范围、时间和成本方面的要求,使技术规格说明书、计划和方案适合于各干系人的不同需求与期望。
项目管理需要的知识领域
除了专门的项目管理技术以外,项目管理组至少应能理解和使用以下5方面的知识领域:
.项目管理知识体系。
.应用领域的知识、标准和规定。
.项目环境知识。
.通用的管理知识和技能。
.软技能(处理人际关系技能)。
项目管理体系
项目管理体系是指用于管理项目的工具、技术、方法、资源和规程。项目管理计划说明如何使用项目管理体系。
项目管理环境
项目管理团队应该考虑的项目环境包括:
.社会环境:经济、人口、教育、道德、种族、宗教和其他特征等。
.政治环境:法律、风俗和政治风气等。
.自然环境:生态和自然地理等。
项目管理办公室
项目管理办公室(PMO)是在管辖范围内集中、协调地管理项目的组织单元。也可指“大项目管理办公室”、“项目办公室”或“大项目办公室”。PMO监控项目、大项目或各类项目组合的管理。由PMO管理的项目不必要有特定的关系,PMO关注与上级组织或客户的整体业务目标相联系的项目或子项目之间的协调计划、优先级和执行情况。
PMO执行的职责可以是一个宽广的范围,包括从以培训、软件、标准政策和规程、模板的形式提供项目管理支持功能,到实际直接管理项目和项目的结果。
PMO可以存在于任何组织结构中,包括职能型组织。
项目经理和项目管理办公室的区别如下:
.追求的目标不同。项目经理关注于特定项目的目标,而PMO管理主要的大项目范围的变化,并将之视为更好地达到业务目标的潜在机会,其工作目标包含组织级的观点。
.项目经理控制赋予项目的资源以最好地实现项目目标,而PMO对所有项目之间的共享资源进行优化使用。
.项目经理管理本项目的范围、进度、费用和质量,而PMO管理整体的风险、整体的机会和所有项目的依赖关系。
过程和过程组
过程就是一组为了完成一系列事先指定的产品、成果或服务而必须执行的互相联系的行动和活动。
项目管理过程由项目团队实施,包括两大类:
.面向管理的过程。即项目管理过程,其目的是启动、规划、执行、监控和结束一个项目。
.面向产品的过程。一般由项目生命期规定,并因领域而异。
项目管理过程和创造产品的过程从项目开始到结束始终彼此重叠交互。
任何项目都必须执行5个项目过程组,它们与应用领域或特定行业无关。过程组不是项目阶段,每一阶段或子项目都要重复过程组的所有子过程。
.启动过程组。定义并批准项目或阶段。在多阶段项目中,后续阶段进行的启动过程是为了确认在指定项目章程与拟定初步项目范围说明书过程中所做的原假设与决策的合理性。启动过程组也定义了项目意图,确定了目标,并授权项目经理进行项目。
.规划过程组。定义和细化目标,规划最佳的行动方案,即从各种备选方案中选择最优方案,以实现项目或阶段所承担的目标和范围。项目团队应让所有项目干系人参与项目计划过程。当项目计划工作结束时,不管是由组织还是由项目团队负责,都要有明确的指导方针,否则将无法确定如何进行后续的反馈和细化。项目管理计划的渐进明细经常被称作“滚动式计划”,这意味着计划是一个迭代和持续的过程。
.执行过程组。整合人员和其他资源,在项目的生命期或某个阶段执行项目管理计划。
.监控过程组。要求定期测量和监控项目进展,识别与项目管理计划的偏差,以便在必要时采取纠正措施,确保项目或阶段目标达成。
.收尾过程组。正式接受产品、服务或工作成果,有序地结束项目或阶段。
项目管理过程组和“计划-执行-检查-行动(即PDCA)”循环的对应关系如下图所示。
项目管理过程组和PDCA循环的对应
规划过程组与PDCA循环中的“计划”对应;执行过程组与循环中的“执行”对应;监控过程组与循环中的“检查”和“行动”对应。启动过程组是这些循环的开始,而收尾过程组是其结束。
过程的交互
项目管理过程组通过它们各自所产生的结果而联系起来——一个过程的结果或者输出通常会成为另一个过程的输入或者整个项目的最终结果。在项目过程组之间以及项目过程本身当中,这种联系是迭代的。
如果一个项目被划分成阶段,每个阶段中的过程经常会反复进行。项目中过程组的相互作用如下图所示。

过程组的相互作用
5个项目过程组与44个项目管理过程及9个项目管理知识域的映射关系如下表所示。
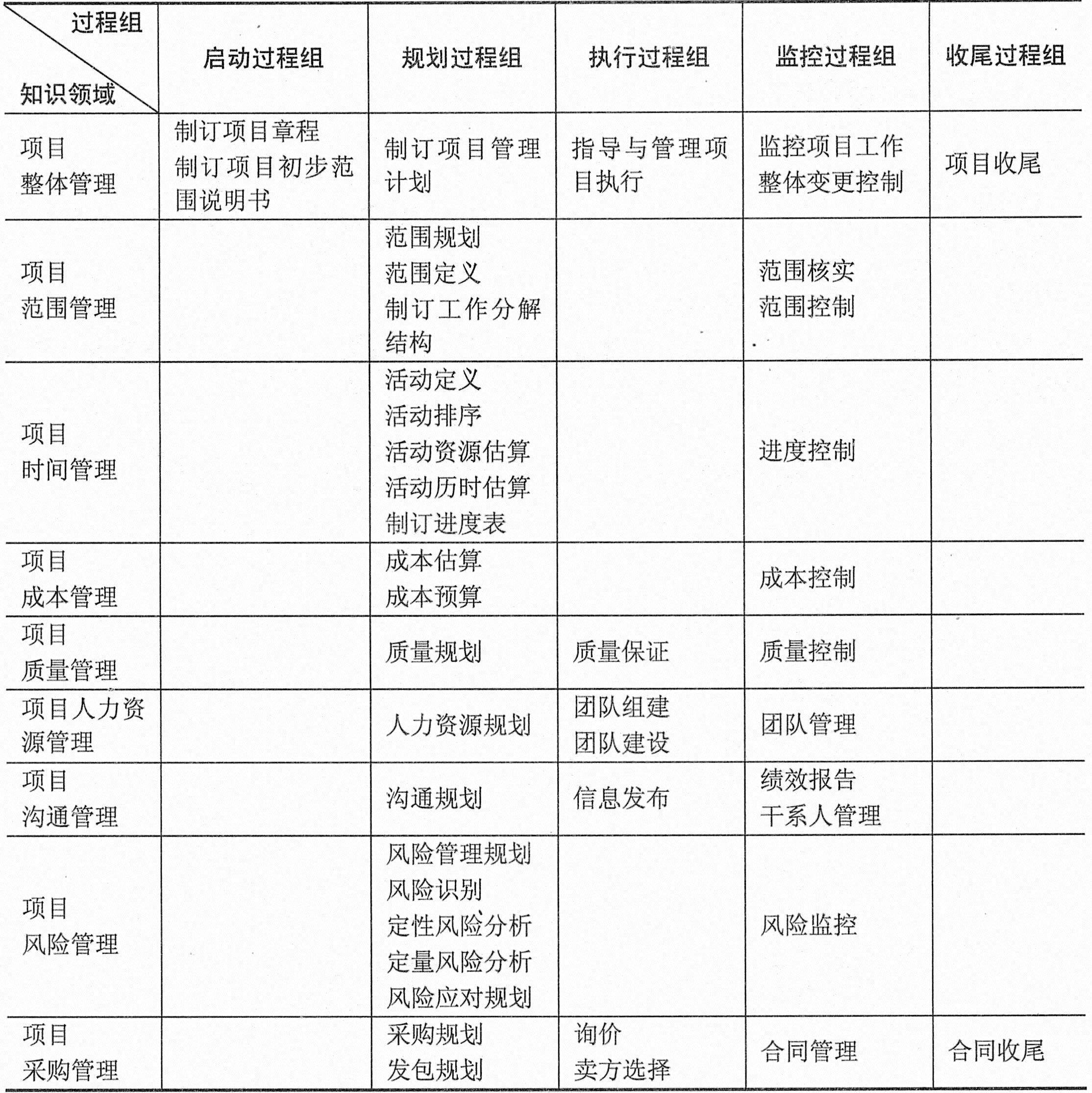
过程组、过程和类知识域的映射关系
注:1.在《信息系统项目管理师教程》中,“团队组建”被划分为规划过程组。在PMBOK 2004版中,“团队组建”在执行过程组中,笔者认为划分在执行过程组中更合理。
2.发包规划在《信息系统项目管理师教程》中也称为计划签约和编制合同。
70. 进行项目风险评估最关键的时间点是( )。
A. 计划阶段
B. 计划发布后
C. 设计阶段
D. 项目出现问题时
评估测试不只针对物理设备,更重要的是要评估、比较各种网络技术。通常使用模拟测试配置和模拟负载进行子系统(如路由器)和网络技术(如ATM或FDDI等)的评估。评估测试不适用于全局网络,因为全局网络拓扑负载、网络设备太多,不好准确定位引起问题的原因和位置,不能进行有效的比较。多数评估测试在专用的子网测试环境中进行。
很多公司都有其固定合作的网络设备供应商,如路由器、集线器或交换机的供应商,通常很少再做设备比较测试,但网络技术的比较测试需要经常进行。企业经常面对选择哪种技术以及怎样比较不同技术的问题,所以技术评估是评估测试中很重要的一项。
在比较设备与技术时,除了使用专用于待测设备或技术的工程负载外,有经验的程序员也使用真实负载,使用真实负载可以了解待测设备或技术在特定环境下的运行性能。通过两种负载模式检测结果的比较,可以获知待测设备还有多少多余容量。
评估测试与设备或技术的功能/特征测试一样,用于比较待测设备或技术的性能、稳定性、特性、易用性配置和管理等方面的功能。
评估测试实质是衰减测试的基础,评估测试中对几种设备或技术进行比较;衰减测试中对同一设备的不同版本进行比较。测试中选择设备的标准也完全可作为验证升级版本工作正常与否的标准。尽可能多地集成在计划/设计阶段进行测试是非常好的方法,最初的产品评估测试可以被开发阶段的可接受性测试和升级阶段的衰减性测试所借鉴。
评估测试是最常进行的测试,在设备选型、技术选型,以及网络系统升级过程中都要进行或多或少的评估测试。
用于评估测试的负载模式和测试脚本要能有效覆盖被检测的设备和技术。常使用最好情形(工程负载)和真实负载模式进行测试,两种方式都提供了唯一的、重要的检测结果,测试人员要能够理解、解释测试结果间的不同。
工程检测结果是被测设备和技术在最理想的情形下测试得到的结果,因此不能在真实运行环境里显示它们的运行性能;真实检测结果能很好地显示待测设备或技术在运行网络环境中的性能,但无法预测设备的总容量。如果时间允许,两种测试都要做。通常测试人员只有时间进行一种测试,一般进行最好情形的测试。许多公开发行的测试报告都是基于最好情形(工程负载)下的测试结果。
所有的测试配置都是模拟的。用于设备比较的测试配置不一定要代表运行网络的典型配置,任何有效、公正的测试配置都能对被测产品进行很好的比较。然而,测试配置和负载越接近运行网络的配置和负载,测试的结果越能反映被测设备在运行网络中的运行情况。
在安装和配置测试网络时必须注意:要确保配置中所有测试组件都是最新版本,使测试尽可能地公正和统一,以取得最好的测试结果。在测试非正式版时一定要小心,因为发布日期经常有错误。测试配置中安装了非正式版后,它还可能会变,所以非正式版的测试结果和正式版的测试结果经常不一致,分析非正式版的设备经常会延误项目的进行。
进行评估测试时,除了被测设备,测试配置中的所有网络组件都要保持不变。这一点非常重要,只有这样才能保证被测设备可以进行公平比较。对于子网,这一点很容易做到(一个网络设备很容易被另一个设备所替代)。
网络技术评估要比较各种网络技术,因而测试配置中的几个网络组件都需要更换。重要的是不要改变源或目标配置。在配置中不仅通信线路需要更换,路由器也需要更换。传输负载和端点的配置要保持不变。
需要评估测试计划中的各个测试任务,逐步完成测试、数据收集和数据解释。在评估测试中,各测试进行的先后次序没有关系,因为它们不是线性关系,而是多次重复进行的。当在测试中发现了新的信息时,以前所做的测试可能要重新进行以确定它的测试结果,或要对以前的测试稍作改变以检验网络运行的其他方面。此外,在评估期间设备提供商经常发布新的版本或非正式的版本,所以各种基于这种设备的测试都要重新进行。
制定网络设备、技术比较或取舍标准时,不仅要参考评估测试所得的测试结果数据,还要综合考虑其他一些信息,如各设备的性能价格比,但由于没有运行网络的持续和峰值负载要求,所以缺少比较基准,往往将产品评估测试引入歧途。
最后要根据评估测试所得的数据和图表对网络系统作出总结性评估,并撰写网络系统评估报告。
71. The Address Resolution Protocol(ARP)was developed to enable communication on an Internetwork and perform a required function in IP routing.ARP lies between layers(71)of the OSI model,and allows computers to introduce each other across a network prior to communication.APR finds the(72 )address of a host from its known(73 )address.Before a device sends a datagram to another device,it looks in its ARP cache to see if there is a MAC address and corresponding IP address for the destination device.If there is no entry,the souree device sends a(74)message to every device on the network.Each device compares the IP address to its own.Only the device with the matching IP address replies with a packet containing the MAC address for the device(except in the case of “proxy ARP”).The source device adds the(75 )device MAC address to its ARP table for future reference.
A. 1 and 2
B. 2 and 3
C. 3 and 4
D. 4 and 5
在网络管理中,最为常用的就是net命令家族。常用的net命令有以下几个。
.net view命令:显示由指定的计算机共享的域、计算机或资源的列表。
.net share:用于管理共享资源,使网络用户可以使用某一服务器上的资源。
.net use命令:用于将计算机与共享的资源相连接或断开,或者显示关于计算机连接的信息。
.net start命令:用于启动服务,或显示已启动服务的列表。
.net stop命令:用于停止正在运行的服务。
.net user命令:可用来添加或修改计算机上的用户账户,或者显示用户账户的信息。
.net config命令:显示正在运行的可配置服务,或显示和更改服务器服务或工作站服务的设置。
.net send命令:用于将消息(可以是中文)发送到网络上的其他用户、计算机或者消息名称上。
.net localgroup命令:用于添加、显示或修改本地组。
.net accounts命令:可用来更新用户账户数据库、更改密码及所有账户的登录要求。
IP层接收由网络接口层发送来的数据包,并把该数据包发送到更高层——TCP或UDP层;相反,IP层也把从TCP或UDP层发送来的数据包传送到更低层——网络接口层。IP数据包是不可靠的,因为IP并没有做任何事情确认数据包是否按顺序发送或者被破坏,IP数据包中含有发送它的主机地址(源地址)和接收它的主机地址(目的地址)。
高层的TCP和UDP服务在接收数据包时通常假设包中的源地址是有效的,即IP地址形成了许多服务的认证基础,这些服务相信数据包是从一个有效的主机发送过来的。IP确认包含一个选项,称为IP source routing,可以用来指定一条源地址和目的地址之间的直接路径。对于一些TCP和UDP的服务来说,使用了该选项的IP包好像是从路径上的最后一个系统传递过来的,而不是来自于它的真实地点。这个选项是为了测试而存在的,说明它可以被用来欺骗系统以进行通常被禁止的连接,因此,许多依靠IP源地址进行确认的服务将产生问题,甚至会被非法入侵。
ARP(Address Resolution Protocol,地址解析协议)是根据IP地址获取物理地址的一个TCP/IP。主机发送信息时会将包含目标IP地址的ARP请求广播到网络中的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。ARP是建立在网络中各个主机互相信任的基础上的,网络中的主机可以自主发送ARP应答消息,其他主机收到应答报文时不会检测该报文的真实性,会直接将其记入本机ARP缓存;因此,攻击者就可以向某一主机发送伪ARP应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个ARP欺骗。ARP命令可用于查询本机ARP缓存中IP地址和MAC地址的对应关系、添加或删除静态对应关系等。相关协议有RARP、代理ARP。NDP用于在IPv6中代替ARP。
72. The Address Resolution Protocol(ARP)was developed to enable communication on an Internetwork and perform a required function in IP routing.ARP lies between layers(71)of the OSI model,and allows computers to introduce each other across a network prior to communication.APR finds the(72 )address of a host from its known(73 )address.Before a device sends a datagram to another device,it looks in its ARP cache to see if there is a MAC address and corresponding IP address for the destination device.If there is no entry,the souree device sends a(74)message to every device on the network.Each device compares the IP address to its own.Only the device with the matching IP address replies with a packet containing the MAC address for the device(except in the case of “proxy ARP”).The source device adds the(75 )device MAC address to its ARP table for future reference.
A. IP
B. logical
C. hardware
D. network
73. The Address Resolution Protocol(ARP)was developed to enable communication on an Internetwork and perform a required function in IP routing.ARP lies between layers(71)of the OSI model,and allows computers to introduce each other across a network prior to communication.APR finds the(72 )address of a host from its known(73 )address.Before a device sends a datagram to another device,it looks in its ARP cache to see if there is a MAC address and corresponding IP address for the destination device.If there is no entry,the souree device sends a(74)message to every device on the network.Each device compares the IP address to its own.Only the device with the matching IP address replies with a packet containing the MAC address for the device(except in the case of “proxy ARP”).The source device adds the(75 )device MAC address to its ARP table for future reference.
A. IP
B. physical
C. MAC
D. virtual
74. The Address Resolution Protocol(ARP)was developed to enable communication on an Internetwork and perform a required function in IP routing.ARP lies between layers(71)of the OSI model,and allows computers to introduce each other across a network prior to communication.APR finds the(72 )address of a host from its known(73 )address.Before a device sends a datagram to another device,it looks in its ARP cache to see if there is a MAC address and corresponding IP address for the destination device.If there is no entry,the souree device sends a(74)message to every device on the network.Each device compares the IP address to its own.Only the device with the matching IP address replies with a packet containing the MAC address for the device(except in the case of “proxy ARP”).The source device adds the(75 )device MAC address to its ARP table for future reference.
A. unicast
B. multicast
C. broadcast
D. point-to-point
75. The Address Resolution Protocol(ARP)was developed to enable communication on an Internetwork and perform a required function in IP routing.ARP lies between layers(71)of the OSI model,and allows computers to introduce each other across a network prior to communication.APR finds the(72 )address of a host from its known(73 )address.Before a device sends a datagram to another device,it looks in its ARP cache to see if there is a MAC address and corresponding IP address for the destination device.If there is no entry,the souree device sends a(74)message to every device on the network.Each device compares the IP address to its own.Only the device with the matching IP address replies with a packet containing the MAC address for the device(except in the case of “proxy ARP”).The source device adds the(75 )device MAC address to its ARP table for future reference.
A. source
B. destination
C. gateway
D. proxy
获取标准答案和详细的答案解析请阅读全文