哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
哈夫曼编码利用了贪心算法的思想,至于贪心算法,简单地描述下就是,每次都选最好的,这种策略。在处理某些问题时直接使用贪心法,可以获得很好的解决方案。
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
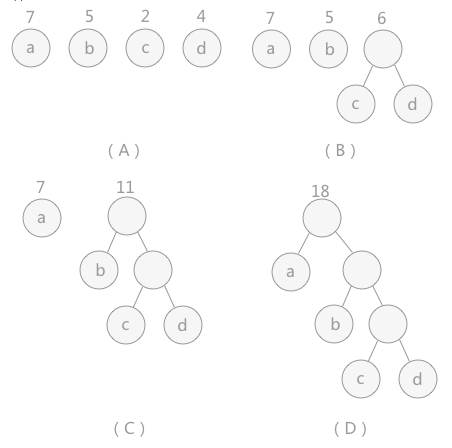
构建哈夫曼树的算法过程:(简单的来说就是每次把根节点权值最小和次小的二叉树合并)
构造方式就是从数组中取出两个最小的元素,让他们作为一个新元素的左右节点,在将新元素放入数组中。再取两个最小元素......以此类推。
直至数组中的元素个数为1的时候,就得到了哈夫曼树。(新的元素是一个节点,放入数组中比较的时候,比较的是里面具体的值)
这会使得权值大的节点在树的上方,而权值小的节点在树的下方。因此使得整棵树的带权路径(WPL)最小。
举个例子,看下图,看完这个例子基本上会了哈夫曼树的构建了。
构建了哈夫曼树之后可以得到字符对应的编码
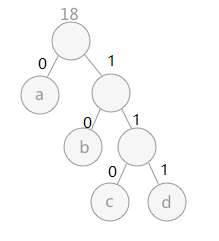
我们可以看到字符a对应的编码就是0,字符b对应的编码就是10,字符c对应的编码就是110,字符d对应的编码就是1111
那么我们如果想对abc进行编码,通过这个哈夫曼树编码就可以得到0101110,这个编码可以被反应解码出来,为什么?因为哈夫曼编码得到的时异字头编码。
代码效果


字符权值文件,最后一行数字代表空格的权值

首先根据字符权值建立对应的haffman树

然后对要进行编码的文件进行编码,并将编码结果保存到3.txt文件中


编码结果

然后可以通过相应的编码和haffman树,译码出对应的内容


获取完整代码请阅读全文
未经允许不得转载!huffman编码与解码【附c++实现代码】